







K-means 聚类算法:
K-means聚类算法
算法流程,我们首先有训练集,但是训练集我们没有类标签,我们想把数据聚类成一些cluster ,这是一种无监督学习方法。具体步骤:1. 首先初始化cluster centroid 2. 迭代的找每一个数据集点到最近cluster centroid,然后把该点给到最近cluster centroid所在的cluster,然后在更新cluster centroid 直到算法收敛。

算法也可如下图描述:分为两部分cluster assignment 和move centroid。

算法执行一个示意图:
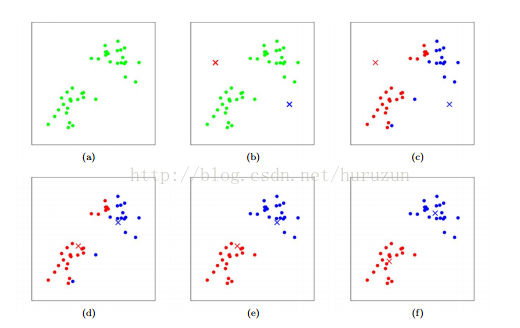
训练数据有点表示,cluster centroid由叉号来表示。(a) 原始数据集 (b)随机初始化cluster centroid (c)-(f)就是算法迭代示意。极端情况如果当某个cluster centroid没有任何一个点分配给它,通常情况下我们把那个cluster centroid 删除,这样导致只会留下K-1个cluster centroid ,如果必须保留K 个 cluster则删除该点,随机选择其他点作为cluster centroid。
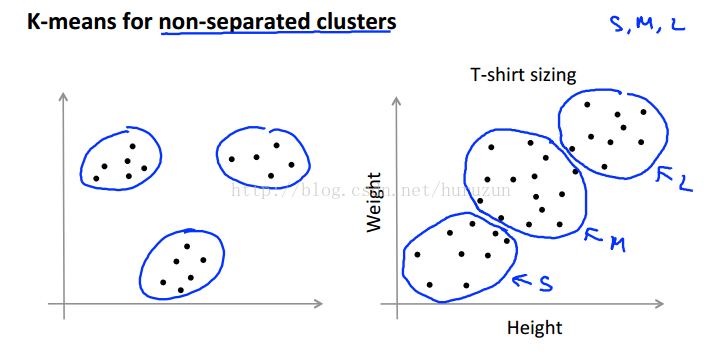
前面举例说的是很好可分状态,如下图左边,而下图右边不是一个可分的,但是通过K-means仍然可以聚类出有实际背景意义下东西,图中说的就是T-shirt大小和人身高体重关系图。
Optimization Objective
K-means算法如何确保收敛性:
我们学过很多经典算法包括线性回归、logistic回归等都有优化函数(optimization object) 优化函数我们可以首先在实现当中可以很好debug,更重要的是优化函数我们去避免local optima 并且利用K-means找到更好的聚类效果。

J function 计算每一个训练数据到各自cluster centroid点距离平方和。可以证明K-means算法就是对J function的坐标上升法(coordinate descent)。具体看下面这段话。

看一张坐标上升法示意图利于理解:
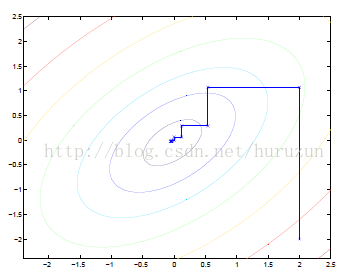
椭圆代表了二次函数的各个等高线,变量数为2,起始坐标是(2,-2)。图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
J function是一个non-convex函数,所以坐标上升无法保证收敛得到全局最小值。换句话说就是K-means算法对局部最优化是susceptible 。如果担心这个问题,可以多次运行算法(使用不同的随机初始值),选择最小的distortion function。
顺便再说一下这里对K的选择不是唯一的。
习题:优化函数我们可以首先在实现当中可以很好debug 如下图
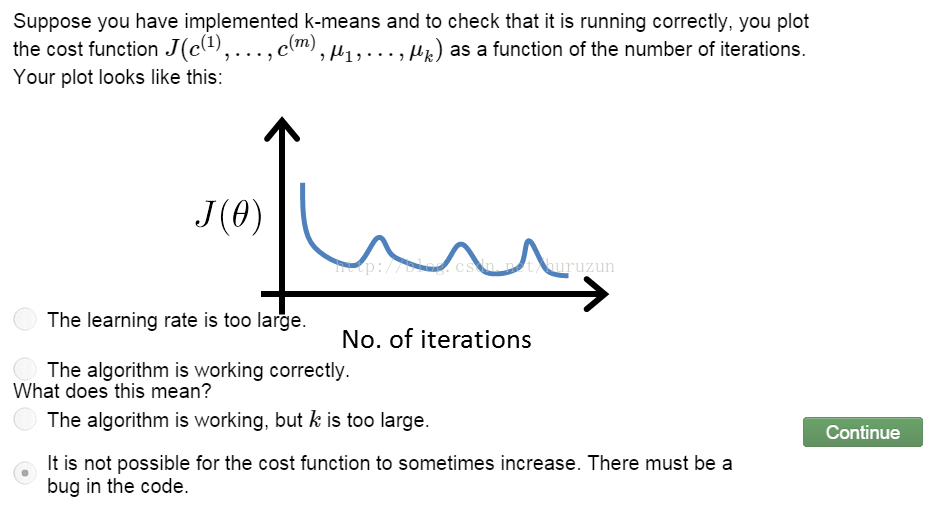

Random initialization
通常做法是:

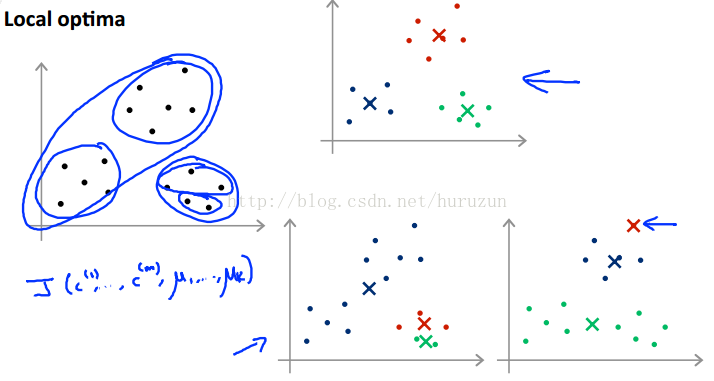
同样数据可能聚类效果如上图右侧三个图所示,为了得到比较好的结果,我们通常多次random initialization 执行K-means多次来避免。形式化描述如下图

如果K聚类的cluster很多,则多次random initialization不会产生很大影响。如果K值在2-10之间cluster数目比较小,多次random initialization会产生比较明显的变化得到效果上明显提升。
习题:

Choosing theNumber of Cluster
很难去确定多少个cluster看下图
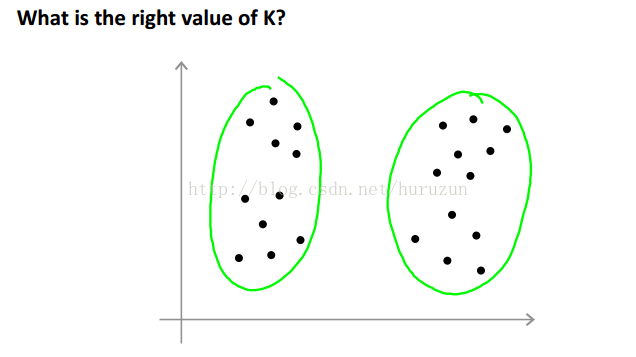
图中我们可以把cluster看作2、4甚至是3个,因为我们没有类标签所以,所以没有一个最终确定答案。
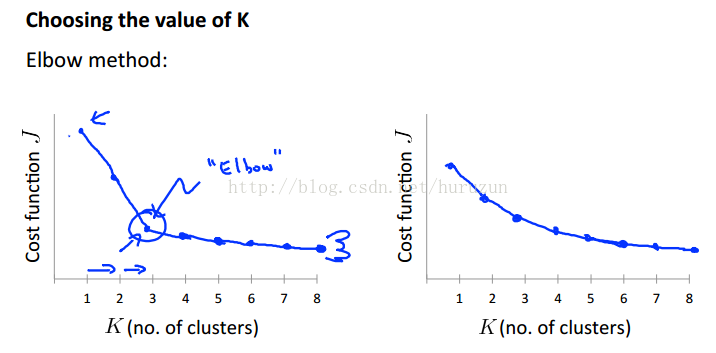
上图是一种图形化选择K方法

选择K的值更多根据应用背景来决定如下图:
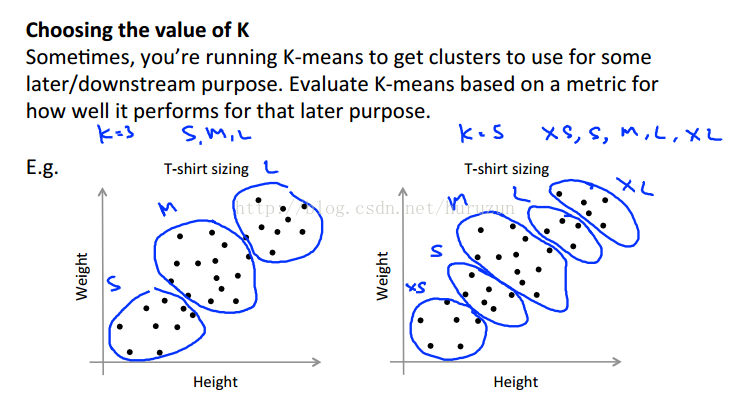
根据你需要进行聚类要求对衣服大小可以选择K=3或者K=5。















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









