







最近公司同事有一个需求就是能够一键抓到股票基金的净值,然后自己做运算,然后空闲时间给他写了个脚本,可能有的人会说python有第三方解析html,但是考虑到给别人用的复杂性,所以这里完全用正则表达式解析
源码会放在下面,利用http://xueqiu.com获取股票的净值 利用http://fund.eastmoney.com获取基金的净值
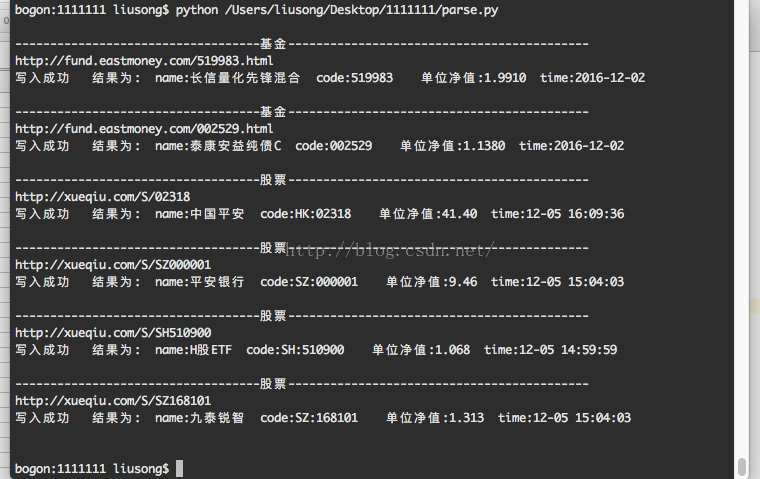
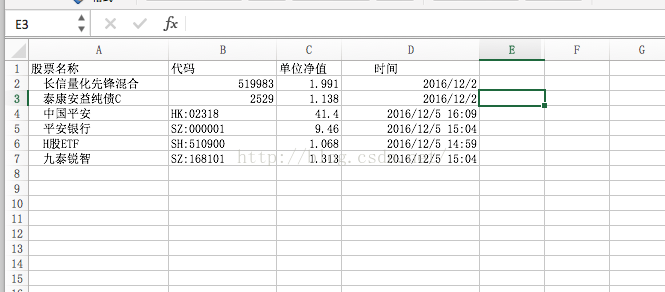
使用方法介绍,
1.是股票,在雪球网查看自己的股票地址 如 http://xueqiu.com/S/SZ000001 则在数组里填写/SZ000001 注意带/
2.是基金,在http://fund.eastmoney.com网站查询自己的基金地址如 http://fund.eastmoney.com/519983.html 则在数组里填写519983,然后执行脚本,会在当前目录创建一个result.csv文件,然后就可以进行其他运算了
codes =['519983','002529','/02318','/SZ000001','/SH510900','/SZ168101']
codes换成你自己的数组,执行脚本
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2
import string,re
import os
import csv
import codecs
codes =['519983','002529','/02318','/SZ000001','/SH510900','/SZ168101']
filename = 'result.csv'
def getHtml(url):
req_header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept':'text/html;q=0.9,*/*;q=0.8',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'utf-8',
'Connection':'close',
'Referer':None #注意如果依然不能抓取的话,这里可以设置抓取网站的host
}
req_timeout = 5
req = urllib2.Request(url,None,req_header)
resp = urllib2.urlopen(req,None,req_timeout)
html = resp.read()
return html
def parse_one(code):
#基金
url = 'http://fund.eastmoney.com/' + code + '.html'
# print url
html = getHtml(url)
pattern ='<dl class="dataItem02">.*?</dl>'
# 将正则表达式编译成Pattern对象
m = re.search(pattern,html)
content = m.group(0) #dateIemm02
pattern2 = '<dd class="dataNums">.*?</dd>'
content2 = re.search(pattern2,content).group(0) #包含净值和比例的标签
pattern3 = '<span\sclass="[^">]+">([^<>]+)</span>'
content3 = re.search(pattern3,content2)
price =content3.group(1)
pattern4 = '<dt>.*?</dt>' #带时间的dt->p->
content4 =re.search(pattern4,content).group(0)
pattern5 = '\(</span>.*?<' #(</span>2016-10-27)<
content5 = re.search(pattern5,content4).group(0)
time = content5[8: len(content5)-2]
pattern6= '<div class="fundDetail-tit">.*?</div>'
content6 =re.search(pattern6,html).group(0) #<div class="fundDetail-tit"><div style="float: left">长信量化先锋混合(<span class="ui-num">519983</span>)</div>
content6 = content6.replace('<div class="fundDetail-tit">','')
pattern7 = 'left">.*?<span'
content7 =re.search(pattern7,content6).group(0) # left">长信量化先锋混合(<span
name = content7[6:len(content7)-5]
writeResult(name,code,price,time)
def parse_two(code):
#股票
url = 'http://xueqiu.com/S' + code
html = getHtml(url)
# print url
pattern ='stockName"><strong.*?class="stockName">.*?</strong>'
nameAndCode =re.search(pattern,html).group(0) # stockName"><strong title="E Fund Management Co.,ltd." class="stockName">H股ETF(SH:510900)</strong>
pattern2 = 'class="stockName">.*?<'
content1 =re.search(pattern2,nameAndCode).group(0) #class="stockName">H股ETF(SH:510900)<
nameAndCode = content1[18:len(content1)-2] #H股ETF(SH:510900
name = nameAndCode.split('(')[0]
code = nameAndCode.split('(')[1]
pattern3 = '<div id="currentQuote">.*</div>' #包含时间净值和时间
content3= re.search(pattern3,html).group(0)
pattern4 = '<div class="currentInfo">.*?<div class="stockInfo'
content4 = re.search(pattern4,content3).group()
#<div class="currentInfo"><strong data-current="40.75" class="stockUp">HK$40.75</strong><span class="stockUp"><span>+0.250</span><span class="quote-percentage"> (+0.62%)</span></span></div><span class="update-quote
pattern5 = 'data-current=.*class="sto'
content5 = re.search(pattern5,content4).group()
pattern5 = 'data-current.*?class="'
content5 = re.search(pattern5,content5).group(0) #data-current="40.75" class="stockUp
pattern5 = 'ent=.*cl'
content5 = re.search(pattern5,content5).group()
price = content5.split('\"')[1]
pattern6 = '<div class="stockInfo">.*?</div>' #<div class="stockInfo"><span id="timeInfo">10-28 15:27:26 (北京时间) </span></div>
content6 = re.search(pattern6,content3).group()
pattern6 = '<span.*?</span>'
content6 = re.search(pattern6,content6).group() #<span id="timeInfo">10-28 15:29:00 (北京时间) </span>
pattern6 = 'timeInfo">.*?<'
content6 = re.search(pattern6,content6).group() #<span id="timeInfo">10-28 15:29:00 (北京时间) </span>
pattern6 = '>.*?\('
content6 = re.search(pattern6,content6).group() #timeInfo">10-28 15:30:10 (北京时间) <
time = content6[1:len(content6)-1]
writeResult(name,code,price,time)
def writeResult(name,code,price,time):
result = 'name:' + name + ' ' + 'code:'+code + ' ' + '单位净值:' + price + ' ' + 'time:' + time
item=[name,code,price,time]
csvfile = open(filename,'ab')
csvfile.write(codecs.BOM_UTF8)
writer = csv.writer(csvfile,dialect='excel')
writer.writerow(item)
csvfile.close()
print '写入成功 结果为: ' + result
item=['股票名称','代码','单位净值',' 时间 ']
csvfile = open(filename,'wb')
csvfile.write(codecs.BOM_UTF8)
writer = csv.writer(csvfile)
writer.writerow(item)
csvfile.close()
for code in codes:
if re.match('^\/.*?',code):
print '\n-----------------------------------股票-------------------------------------------'
parse_two(code)
else:
print '\n-----------------------------------基金-------------------------------------------'
parse_one(code)
print '\n'














 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









