







 本文探讨了硬间隔SVM在处理噪声数据时的过拟合问题,并介绍了软间隔SVM的概念,允许一定程度的误差以减少过拟合风险。通过引入松弛变量ξ,软间隔SVM成为了一个优化问题,通过Lagrange乘子法和核函数进行求解。实际应用中,如libSVM和Scikit-learn,调整C和γ参数至关重要,较小的值通常能带来更好的泛化能力。
本文探讨了硬间隔SVM在处理噪声数据时的过拟合问题,并介绍了软间隔SVM的概念,允许一定程度的误差以减少过拟合风险。通过引入松弛变量ξ,软间隔SVM成为了一个优化问题,通过Lagrange乘子法和核函数进行求解。实际应用中,如libSVM和Scikit-learn,调整C和γ参数至关重要,较小的值通常能带来更好的泛化能力。
上两篇讲到了hard-margin的SVM以及kernel的原理,利用高斯kernel可以将低维空间转换到无穷维,将所有样本分开。但是如果数据中存在一定的噪声数据,SVM也会将噪声数据拟合,存在过拟合的风险。Soft-margin SVM原理就是让SVM能够容忍一定的噪声数据,以减少过拟合的风险。
Hard-margin过拟合问题
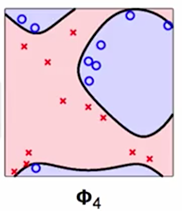
先看一下上面的相同数据集中的两个模型,左图中的模型能够容忍数据中存在一定噪声,而且在数据集上表示还可以;右图就是Hard-margin SVM,不能容忍数据集中的噪声,根据奥卡姆剃刀原理,明显左边的模型能更好的解释数据,右图的模型存在过拟合的风险。
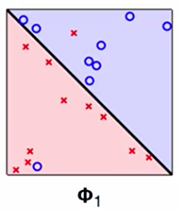
Soft-margin SVM假设
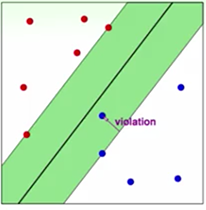
为了让Hard-margin容忍一定的误差,在每个样本点后面加上了一个宽松条件,允许这个点违反一点点 ξ 大小的误差(上图中的violation就是这个 ξ ),对于没有违反的点,则 ξ 为0。同时为了最优化,需要最小化所有误差的和,因此在最小化的项后面加上了误差和。
minw,b,ξ12wTw+C∑n=1Nξn;s.t.yn(wTϕ(x)+b)≥1−ξn,ξn≥0n=1...N
上式子中,在 ξ 前面加了权重C,这个可以由使用SVM的用户指定,可以看出,如果C很大,对错误的惩罚越大,模型会倾向于尽量将样本分割开;如果C越小,则会有更多的违反边界的点存在,并且上图中绿色的margin就越大。
Soft-margin SVM 推导
上面的假设仍旧是标准的二次规划问题,可以通过转化成Lagrange对偶形式,利用kernel来计算(这和hard-margin的推导过程类似,可以参考上一篇kernel及支持向量)。把带有惩罚项的SVM优化式写成Lagrange优化形式,如下:
L(b,w,ξ,α,β)=12wTw+C∑n=1Nξn+∑n=1Nαn(1−ξn−yn(wTzn+b))+∑n=1Nβn(−ξn)
对偶问题如下:
maxαn≥0,β
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









