







软间隔
软间隔是相对于硬间隔定义的。
在上一篇文章:学习笔记(一)中的SVM算法是线性可分的SVM算法,属于硬间隔。
所谓硬间隔,就是存在所有样本必须划分正确的约束条件,即所有样本必须严格满足:
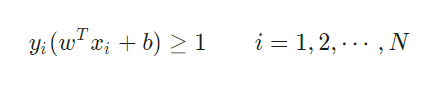
而对于软间隔,则是允许某些样本不满足以上约束条件。

硬间隔要求间隔之间不存在任何点,这一点是十分苛刻的,导致硬间隔SVM对于异常点非常敏感。
由于噪声的因素,属于A类的点可能会分布在B类中(异常点),此时硬间隔将无法找到一个划分超平面。
而我们之所以定义软间隔,也是基于这个原因。允许训练的模型中,部分样本(离群点或者噪音点)不必满足该约束,同时在最大化间隔时,不满足约束的样本应该尽可能的少。
软间隔优化目标函数
优化目标函数
针对软间隔问题,我们引入了以下的优化目标函数:

其中C>0是一个常数,l_0/1是"0/1损失函数"
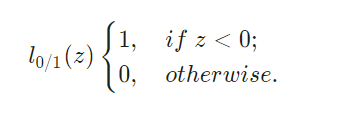
当C为无穷大时,为了保证目标函数取得最小值,需要要求l_0/1=0,即所有样本严格满足硬间隔约束条件;
当C取有限值时,允许部分样本不满足约束条件。
替代损失函数
由于l_0/1非凸、非连续的数学特性,导致目标函数不易求解,我在网上发现一般是采用以下的"替代损失"函数来进行代替l_0/1:
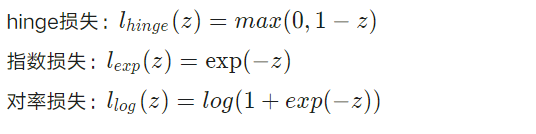
一般这些函数都是凸、连续,且是l_0/1的上界。
软间隔支持向量机

例如:使用hinge损失代替l_0/1

上式就是常用的“软间隔支持向量机”。

和SVM学习笔记(一) 的结果对比,可以看到唯一的区别就是现在拉格朗日乘子a多了一个上限C。
通过样本确定参数,最终的求解过程也和上一篇文章相同,对任一适合条件都可求得一个b^*。
但是由于原始问题对b的求解并不唯一,所以实际计算时可以取在所有符合条件的样本点上的平均值。
另外,解释一下C的意义:C是分割区域的带宽长度,C值越大带宽越窄,越不允许中间的分隔地带存在出错的样本;C越小带宽越大,越允许有较多出错的样本出现在分割区域内。















 6093
6093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









