







前言
之前介绍了SSD的基本用法和检测单张图片的方法,那么本篇博客将详细记录如何使用SSD检测框架训练KITTI数据集。SSD项目中自带了用于训练PASCAL VOC数据集的脚本,基本不用做修改就可以轻松完成训练;但是想要训练其他数据集比如KITTI,则需做很大的调整。本文所有工具源码都已公开,请根据实际情况自行修改。
下载数据集
博主打算将SSD算法用于检测车载视频,用到的是 KITTI数据集 。简单介绍一下,KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。用于评测目标(机动车、非机动车、行人等)检测、目标跟踪、路面分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡(ps:欧洲道路状况和中国还是很不相同,期待国内早日能有同类数据集)。
进入官网,找到object一栏,准备下载数据集:
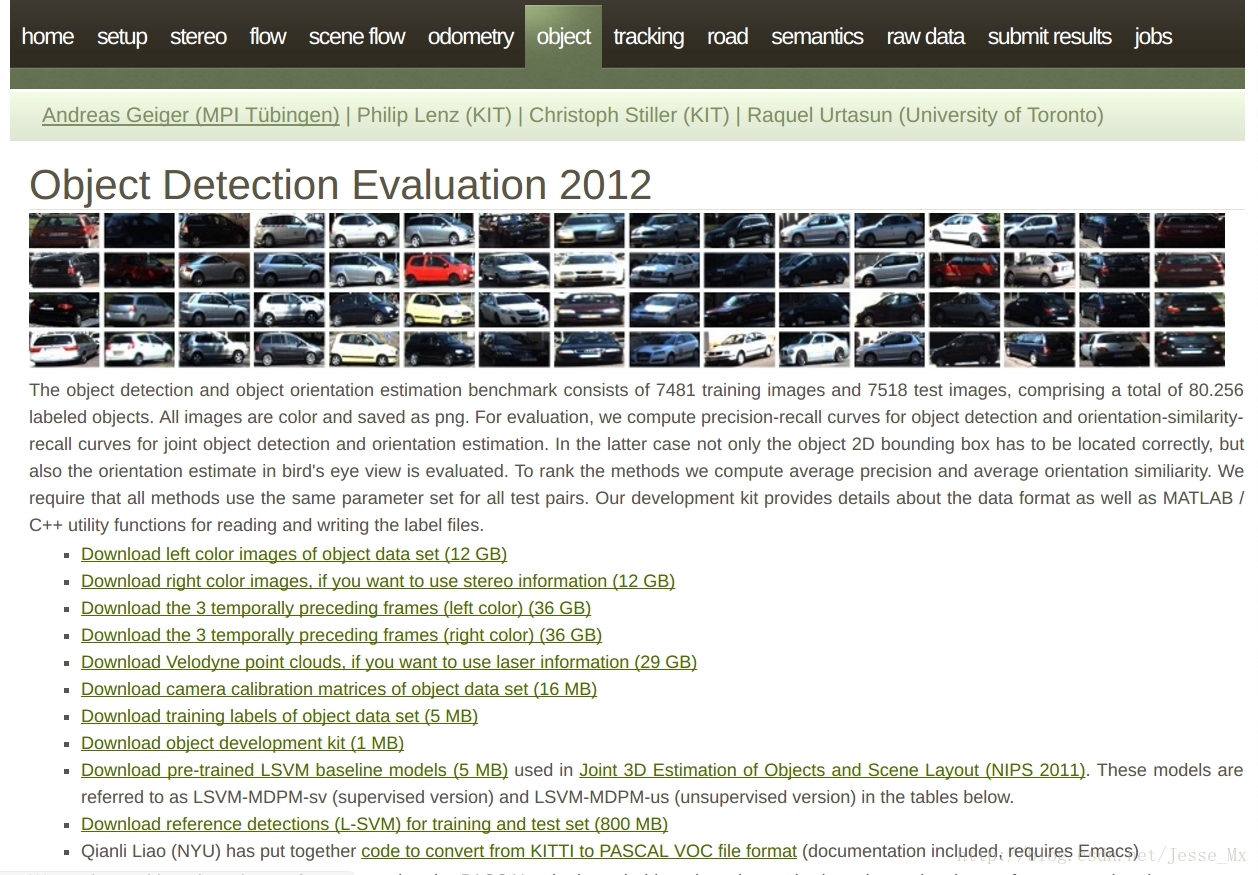
根据下载情况(博主把前四个都下载了,点开看过),进行SSD训练只需要下载第1个图片集 Download left color images of object data set (12 GB)和标注文件 Download training labels of object data set (5 MB) 就够了。然后将其解压,发现其中7481张训练图片有标注信息,而测试图片没有,这就是本次训练所使用的图片数量。由于SSD中训练脚本是基于VOC数据集格式的,所以我们需要把KITTI数据集做成PASCAL VOC的格式,其基本架构可以参看这篇博客:PASCAL VOC数据集分析 。根据SSD训练要求,博主在/home/mx/data/中目录中建立一系列文件夹存放所需数据集和工具文件,具体如下:
PS.参看截图,数据要放在home目录下的data文件夹,不是caffe中的data文件夹,这个要注意,否则后续脚本出错。
# 在data/文件夹下新建KITTIdevkit/KITTI两层子目录,所需文件放在KITTI/中
Annotations/
└── 000000.xml
ImageSets/
└── main/
└── trainval.txt
└── test.txt # 等等
JPEGImages/
└── 000000.png
Labels/
└── 000000.txt # 自建文件夹,存放原始标注信息,待转化为xml,不属于VOC格式
create_train_test_txt.py # 3个python工具,后面有详细介绍
modify_annotations_txt.py
txt_to_xml.py
(截图来源于小规模试验,图片只有400张)
转换数据集
为了方便SSD进行训练,我们需要将KITTI数据集转换成PASCAL VOC的格式,细心的朋友可能已经发现,KITTI官网提供了一个工具: code to convert from KITTI to PASCAL VOC file format ,为啥不用呢?因为我觉得很难用,缺乏灵活性,还不如自己的Python转换工具好使。
KITTI标注信息说明
KITTI数据集中标注信息是存放在txt文本中的,我们随便复制一些标注语句,看看都包含了那些信息:
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
具体的含义在官网没找到,但是博主偶然在DIGITS项目中看到了KITTI标注信息的明确含义:
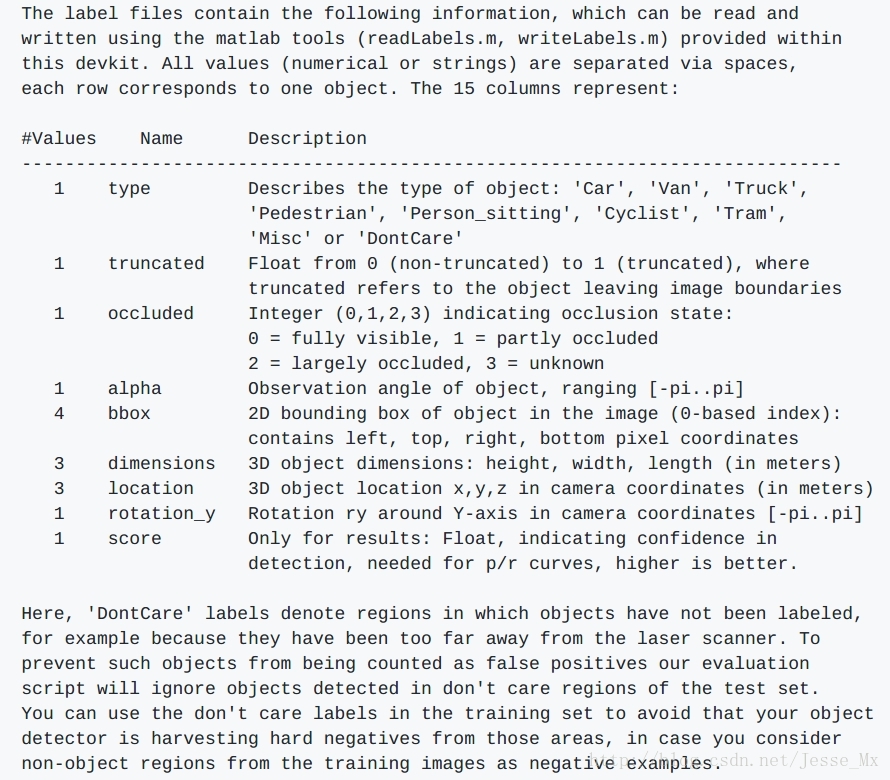
上图链接:Object Detection Data Extension ,可以看到,KITTI的标注信息中,SSD训练需要使用的只有类别’Car‘和物体外框的坐标‘387.63 181.54 423.81 203.12’,其余的字段都可以忽略。
转换KITTI类别
PASCAL VOC数据集总共20个类别,如果用于特定场景,20个类别确实多了。此次博主为数据集设置3个类别, ‘Car’,’Cyclist’,’Pedestrian’,只不过标注信息中还有其他类型的车和人,直接略过有点浪费,博主希望将 ‘Van’, ‘Truck’, ‘Tram’ 合并到 ‘Car’ 类别中去,将 ‘Person_sitting’ 合并到 ‘Pedestrian’ 类别中去(‘Misc’ 和 ‘Dontcare’ 这两类直接忽略)。这里使用的是modify_annotations_txt.py工具,源码如下:
# modify_annotations_txt.py
import glob
import string
txt_list = glob.glob('./Labels/*.txt') # 存储Labels文件夹所有txt文件路径
def show_category(txt_list):
category_list= []
for item in txt_list:
try:
with open(item) as tdf:
for each_line in tdf:
labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开
category_list.append(labeldata[0]) # 只要第一个字段,即类别
except IOError as ioerr:
print('File error:'+str(ioerr))
print(set(category_list)) # 输出集合
def merge(line):
each_line=''
for i in range(len(line)):
if i!= (len(line)-1):
each_line=each_line+line[i]+' '
else:
each_line=each_line+line[i] # 最后一条字段后面不加空格
each_line=each_line+'\n'
return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:
new_txt=[]
try:
with open(item, 'r') as r_tdf:
for each_line in r_tdf:
labeldata = each_line.strip().split(' ')
if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类
labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
if labeldata[0] == 'Person_sitting': # 合并行人类
labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
if labeldata[0] == 'DontCare': # 忽略Dontcare类
continue
if labeldata[0] == 'Misc': # 忽略Misc类
continue
new_txt.append(merge(labeldata)) # 重新写入新的txt文件
with open(item,'w+') as< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6597
6597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









