







关于Keras模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
Sequential models:这种方法用于实现一些简单的模型。你只需要向一些存在的模型中添加层就行了。
Functional API:Keras的API是非常强大的,你可以利用这些API来构造更加复杂的模型,比如多输出模型,有向无环图等等。
两类模型有一些方法是相同的:
model.summary():打印出模型概况
model.get_config():返回包含模型配置信息的Python字典。模型也可以从它的config信息中重构回去
config = model.get_config()
model = Model.from_config(config)
# or, for Sequential:
model = Sequential.from_config(config)model.get_layer():依据层名或下标获得层对象
model.get_weights():返回模型权重张量的列表,类型为numpy array
model.set_weights():从numpy array里将权重载入给模型,要求数组具有与model.get_weights()相同的形状。
model.to_json:返回代表模型的JSON字符串,仅包含网络结构,不包含权值。可以从JSON字符串中重构原模型:
from models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)model.to_yaml:与model.to_json类似,同样可以从产生的YAML字符串中重构模型
from models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)model.save_weights(filepath):将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)
model.load_weights(filepath, by_name=False):从HDF5文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。如果想将权重载入不同的模型(有些层相同)中,则设置by_name=True,只有名字匹配的层才会载入权重
快速开始序贯(Sequential)模型
序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。
可以通过向Sequential模型传递一个layer的list来构造该模型。
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, units=784),
Activation('relu'),
Dense(10),
Activation('softmax'),
])也可以通过.add()方法一个个的将layer加入模型中
model = Sequential()
model.add(Dense(32, input_shape=(784,)))#layers.Dense 意思是这个神经层是全连接层
model.add(Activation('relu'))指定输入数据的shape
模型需要知道输入数据的shape,因此,Sequential的第一层需要接受一个关于输入数据shape的参数,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。有几种方法来为第一层指定输入数据的shape。
传递一个input_shape的关键字参数给第一层,input_shape是一个tuple类型的数据,其中也可以填入None,如果填入None则表示此位置可能是任何正整数。数据的batch大小不应包含在其中。
有些2D层,如Dense,支持通过指定其输入维度input_dim来隐含的指定输入数据shape。一些3D的时域层支持通过参数input_dim和input_length来指定输入shape。
如果你需要为输入指定一个固定大小的batch_size(常用于stateful RNN网络),可以传递batch_size参数到一个层中,例如你想指定输入张量的batch大小是32,数据shape是(6,8),则你需要传递batch_size=32和input_shape=(6,8)model = Sequential()
model.add(Dense(32, input_dim=784))
model = Sequential()
model.add(Dense(32, input_shape=784))编译
在训练模型之前,我们需要通过compile来对学习过程进行配置。compile接收三个参数
优化器optimizer:该参数可指定为已预定义的优化器名,如rmsprop、adagrad,或一个Optimizer类的对象,详情见optimizers
损失函数loss:该参数为模型试图最小化的目标函数,它可为预定义的损失函数名,如categorical_crossentropy、mse,也可以为一个损失函数。详情见losses
指标列表metrics:对分类问题,我们一般将该列表设置为metrics=['accuracy']。指标可以是一个预定义指标的名字,也可以是一个用户定制的函数.指标函数应该返回单个张量,或一个完成metric_name - > metric_value映射的字典.请参考性能评估# For a multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# For a binary classification problem
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# For a mean squared error regression problem
model.compile(optimizer='rmsprop',
loss='mse')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])compile(self, optimizer, loss, metrics=None, sample_weight_mode=None)optimizer:字符串(预定义优化器名)或优化器对象,参考优化器
loss:字符串(预定义损失函数名)或目标函数,参考损失函数
metrics:列表,包含评估模型在训练和测试时的网络性能的指标,典型用法是metrics=['accuracy']
sample_weight_mode:如果你需要按时间步为样本赋权(2D权矩阵),将该值设为“temporal”。默认为“None”,代表按样本赋权(1D权)。在下面fit函数的解释中有相关的参考内容。
kwargs:使用TensorFlow作为后端请忽略该参数,若使用Theano作为后端,kwargs的值将会传递给 K.function
model = Sequential()
model.add(Dense(32, input_shape=(500,)))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])训练
Keras以Numpy数组作为输入数据和标签的数据类型。训练模型一般使用fit函数,该函数的详情见这里。下面是一些例子。
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)# For a single-input model with 10 classes (categorical classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=10, batch_size=32)fit
fit(self, x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)本函数将模型训练nb_epoch轮,其参数有:
x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
y:标签,numpy array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练的轮数,每个epoch会把训练集轮一遍。
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode='temporal'。
initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
evaluate
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)本函数按batch计算在某些输入数据上模型的误差,其参数有:
x:输入数据,与fit一样,是numpy array或numpy array的list
y:标签,numpy array
batch_size:整数,含义同fit的同名参数
verbose:含义同fit的同名参数,但只能取0或1
sample_weight:numpy array,含义同fit的同名参数
predict
predict(self, x, batch_size=32, verbose=0)Keras Sequential models
导入和构建序列模型。
from keras.models import Sequential
models = Sequential()接下来我们可以向模型中添加 Dense(full connected layer),Activation,Conv2D,MaxPooling2D函数。
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropout
model.add(Conv2D(64, (3,3), activation='relu', input_shape = (100,100,32)))
# This ads a Convolutional layer with 64 filters of size 3 * 3 to the graph
以下是如何将一些最流行的图层添加到网络中。我已经在卷积神经网络教程中写了很多关于图层的描述。
#卷积层
这里我们使用一个卷积层,64个卷积核,维度是33的,之后采用 relu 激活函数进行激活,输入数据的维度是 100100*32。注意,如果是第一个卷积层,那么必须加上输入数据的维度,后面几个这个参数可以省略。
model.add(Conv2D(64, (3,3), activation='relu', input_shape = (100,100,32)))#MaxPooling 层
指定图层的类型,并且指定赤的大小,然后自动完成赤化操作,酷毙了!
model.add(MaxPooling2D(pool_size=(2,2)))全连接层
这个层在 Keras 中称为被称之为 Dense 层,我们只需要设置输出层的维度,然后Keras就会帮助我们自动完成了。
model.add(Dense(256, activation='relu'))#Dropout
model.add(Dropout(0.5))#扁平层
model.add(Flatten())数据输入
网络的第一层需要读入训练数据。因此我们需要去制定输入数据的维度。因此,input_shape参数被用于制定输入数据的维度大小。
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(224, 224, 3)))在这个例子中,数据输入的第一层是一个卷积层,输入数据的大小是 224*224*3 。
以上操作就帮助你利用序列模型构建了一个模型。接下来,让我们学习最重要的一个部分。一旦你指定了一个网络架构,你还需要指定优化器和损失函数。我们在Keras中使用compile函数来达到这个功能。比如,在下面的代码中,我们使用 rmsprop 来作为优化器,binary_crossentropy 来作为损失函数值。
model.compile(loss='binary_crossentropy', optimizer='rmsprop')如果你想要使用随机梯度下降,那么你需要选择合适的初始值和超参数:
from keras.optimizers import SGD
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)现在,我们已经构建完了模型。接下来,让我们向模型中输入数据,在Keras中是通过 fit函数来实现的。你也可以在该函数中指定 batch_size 和 epochs 来训练。
model.fit(x_train, y_train, batch_size = 32, epochs = 10, validation_data(x_val, y_val))最后,我们使用 evaluate 函数来测试模型的性能。
score = model.evaluate(x_test, y_test, batch_size = 32)
函数式模型接口
Keras的函数式模型为Model,即广义的拥有输入和输出的模型,我们使用Model来初始化一个函数式模型
from keras.models import Model
from keras.layers import Input, Dense
a = Input(shape=(32,))
b = Dense(32)(a)
model = Model(inputs=a, outputs=b)在这里,我们的模型以a为输入,以b为输出,同样我们可以构造拥有多输入和多输出的模型
model = Model(inputs=[a1, a2], outputs=[b1, b3, b3])常用Model属性
model.layers:组成模型图的各个层
model.inputs:模型的输入张量列表
model.outputs:模型的输出张量列表
Model模型方法
compile
compile(self, optimizer, loss, metrics=None, loss_weights=None, sample_weight_mode=None)本函数编译模型以供训练,参数有
optimizer:优化器,为预定义优化器名或优化器对象,参考优化器
loss:损失函数,为预定义损失函数名或一个目标函数,参考损失函数
metrics:列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[‘accuracy’]如果要在多输出模型中为不同的输出指定不同的指标,可像该参数传递一个字典,例如metrics={‘ouput_a’: ‘accuracy’}
sample_weight_mode:如果你需要按时间步为样本赋权(2D权矩阵),将该值设为“temporal”。默认为“None”,代表按样本赋权(1D权)。如果模型有多个输出,可以向该参数传入指定sample_weight_mode的字典或列表。在下面fit函数的解释中有相关的参考内容。
kwargs:使用TensorFlow作为后端请忽略该参数,若使用Theano作为后端,kwargs的值将会传递给 K.function
【Tips】如果你只是载入模型并利用其predict,可以不用进行compile。在Keras中,compile主要完成损失函数和优化器的一些配置,是为训练服务的。predict会在内部进行符号函数的编译工作(通过调用_make_predict_function生成函数)
fit(self, x=None, y=None, batch_size=32, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
使用Keras API开发VGG卷积神经网络
VGG:VGG卷积神经网络是牛津大学在2014年提出来的模型。当这个模型被提出时,由于它的简洁性和实用性,马上成为了当时最流行的卷积神经网络模型。它在图像分类和目标检测任务中都表现出非常好的结果。在2014年的ILSVRC比赛中,VGG 在Top-5中取得了92.3%的正确率。 该模型有一些变种,其中最受欢迎的当然是 vgg-16,这是一个拥有16层的模型。你可以看到它需要维度是 224*224*3 的输入数据。
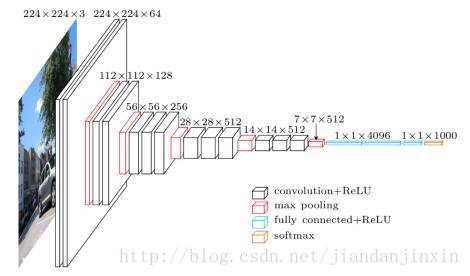
让我们来写一个独立的函数来完整实现这个模型。
img_input = Input(shape=input_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
我们可以将这个完整的模型,命名为 vgg16.py。
在这个例子中,我们来运行 imageNet 数据集中的某一些数据来进行测试。具体代码如下
model = applications.VGG16(weights='imagenet')
img = image.load_img('cat.jpeg', target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
for results in decode_predictions(preds):
for result in results:
print('Probability %0.2f%% => [%s]' % (100*result[2], result[1]))

建模示例
DEBUG = False
# 建模
if DEBUG:
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid', input_shape=(60, 200, 1), name='conv1'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Convolution2D(32, 3, 3, name='conv2'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
# model.add(Reshape((20, 60)))
# model.add(LSTM(32))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(216))
model.add(Activation('softmax'))
else:
model = model_from_json(open('model/ba_cnn_model2.json').read())
model.load_weights('model/ba_cnn_model2.h5')
# 编译
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'], class_mode='categorical')
model.summary()
# 绘图
plot(model, to_file='model.png', show_shapes=True)
# 训练
check_pointer = ModelCheckpoint('./model/train_len_size1.h5', monitor='val_loss', verbose=1, save_best_only=True)
model.fit(x_train, y_train, batch_size=32, nb_epoch=5, validation_split=0.1, callbacks=[check_pointer])
json_string = model.to_json()
with open('./model/ba_cnn_model2.json', 'w') as fw:
fw.write(json_string)
model.save_weights('./model/ba_cnn_model2.h5')
# 测试
y_pred = model.predict(x_test, verbose=1)
cnt = 0
for i in range(len(y_pred)):
guess = ctable.decode(y_pred[i])
correct = ctable.decode(y_test[i])
if guess == correct:
cnt += 1
if i%10==0:
print '--'*10, i
print 'y_pred', guess
print 'y_test', correct
print cnt/float(len(y_pred))
参考文献
Keras TensorFlow教程:如何从零开发一个复杂深度学习模型















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









