







Ridge回归
可以看成是对最小二乘法的一种补充,岭回归通过对系数的大小施加惩罚来解决普通最小二乘法的一些问题。
它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项,和一个调节线性回归项和正则化项权重的系数
α
。损失函数表达式如下:
其中 α 为常数系数,需要进行调优。 ||θ||2 为L2范数。
Ridge回归的解法和一般线性回归大同小异。如果采用梯度下降法,则每一轮 θ 迭代的表达式是:
如果用最小二乘法,则 θ 的结果是:
Ridge回归在不抛弃任何一个变量的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但这会使得模型的变量特别多,模型解释性差。有没有折中一点的办法呢?即又可以防止过拟合,同时克服Ridge回归模型变量多的缺点呢?有,这就是下面说的Lasso回归。
Lasso回归
Lasso回归有时也叫做线性回归的L1正则化,和Ridge回归的主要区别就是在正则化项,Ridge回归用的是L2正则化,而Lasso回归用的是L1正则化。Lasso回归的损失函数表达式如下:
Lasso回归使得一些系数变小,甚至还是一些绝对值较小的系数直接变为0,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。
但是Lasso回归有一个很大的问题,导致我们需要把它单独拎出来讲,就是它的损失函数不是连续可导的,由于L1范数用的是绝对值之和,导致损失函数有不可导的点。也就是说,我们的最小二乘法,梯度下降法,牛顿法与拟牛顿法对它统统失效了。那我们怎么才能求有这个L1范数的损失函数极小值呢?
用坐标轴下降法求解Lasso回归
求解步骤:
1.给定初始点(
x1,x2,...,xn
)
2.固定除
xi
意外其他维度的点,以
xi
为自变量获取最小值
3.换个维度,重复2
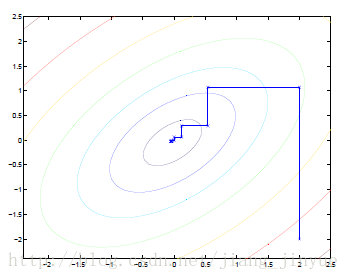
可以看出,坐标下降法在每次迭代中在当前点处沿一个坐标方向进行一维搜索,固定其他的坐标方向,找到一个函数的局部极小值。
坐标下降优化方法是一种非梯度优化算法。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度迭代。
gradient descent 方法是利用目标函数的导数(梯度)来确定搜索方向的,该梯度方向可能不与任何坐标轴平行。而coordinate descent方法是利用当前坐标方向进行搜索,不需要求目标函数的导数,只按照某一坐标方向进行搜索最小值,两者都是迭代方法,且每一轮迭代,都需要O(mn)的计算量(m为样本数,n为系数向量的维度)。
最小角回归法求解Lasso回归
1.前向选择(Forward Selection)算法
问题是求解
Y=Xθ
中的
θ
。其中
Y
为 mx1的向量,
把矩阵
X
看做n个mx1的向量
即: Y¯¯¯ ,是 Y 在
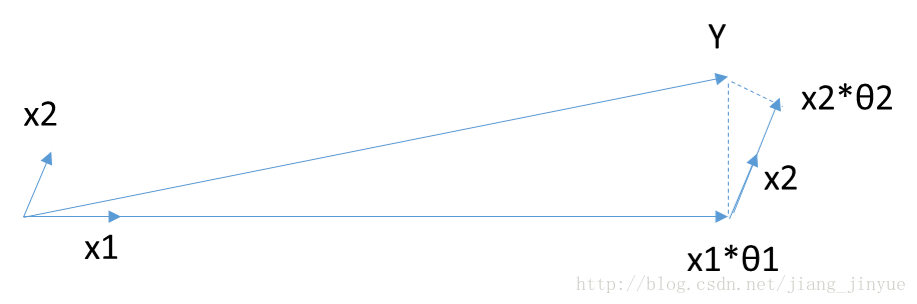
当 X 只有2维时,例子如上图,和
2.前向梯度(Forward Stagewise)算法
前向梯度算法和前向选择算法有类似的地方,不再使用投影的方式,而是在最接近的自变量
Xt
的方向上移动一小步,在观察与残差
Yyes
最接近的自变量,直到残差足够小。

当
X
只有2维时,例子如上图,和
当算法在ε很小的时候,可以很精确的给出最优解,当然,其计算的迭代次数也是大大的增加。和前向选择算法相比,前向梯度算法更加精确,但是更加复杂。有没有折中的办法可以综合前向梯度算法和前向选择算法的优点,做一个折中呢?有!这就是终于要出场的最小角回归法。
3.最小角回归(Least Angle Regression, LARS)算法
首先,依然是寻找到与因变量
Y
接近或者相关度最高的自变量

当θ只有2维时,例子如上图,和Y最接近的是X1,首先在X1上面走一段距离,一直到残差在X1和X2的角平分线上,此时沿着角平分线走,直到残差最够小时停止,此时对应的系数β即为最终结果。
最小角回归法是一个适用于高维数据的回归算法,其主要的优点有:
1)特别适合于特征维度n 远高于样本数m的情况。
2)算法的最坏计算复杂度和最小二乘法类似,但是其计算速度几乎和前向选择算法一样
3)可以产生分段线性结果的完整路径,这在模型的交叉验证中极为有用
主要的缺点是:
由于LARS的迭代方向是根据目标的残差而定,所以该算法对样本的噪声极为敏感。














 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









