







搭建好环境的前提下!!!
1.创建mapReduce项目
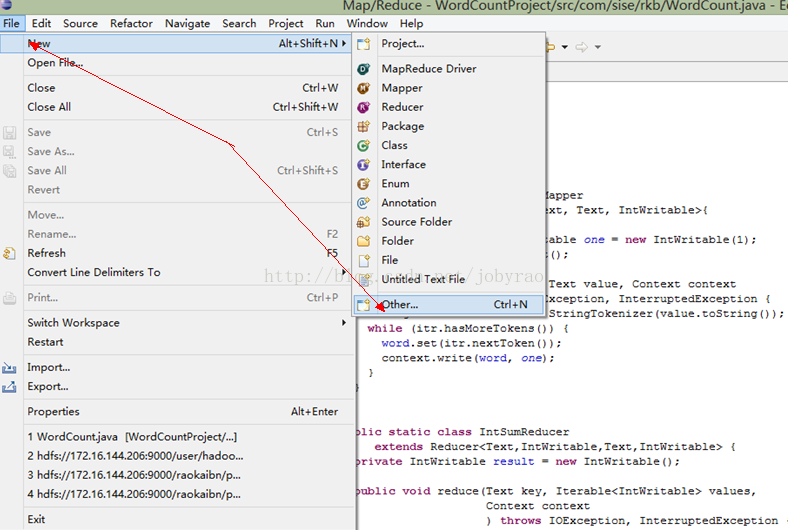
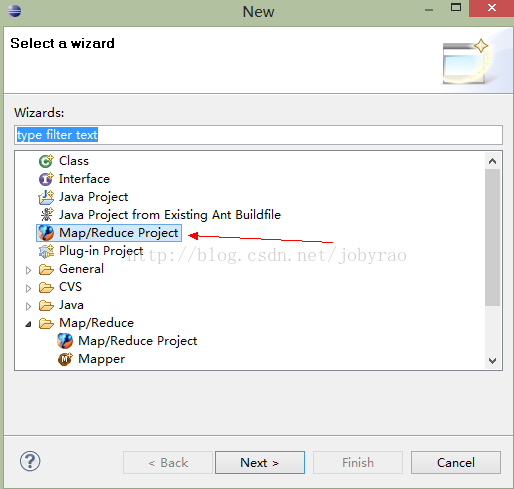
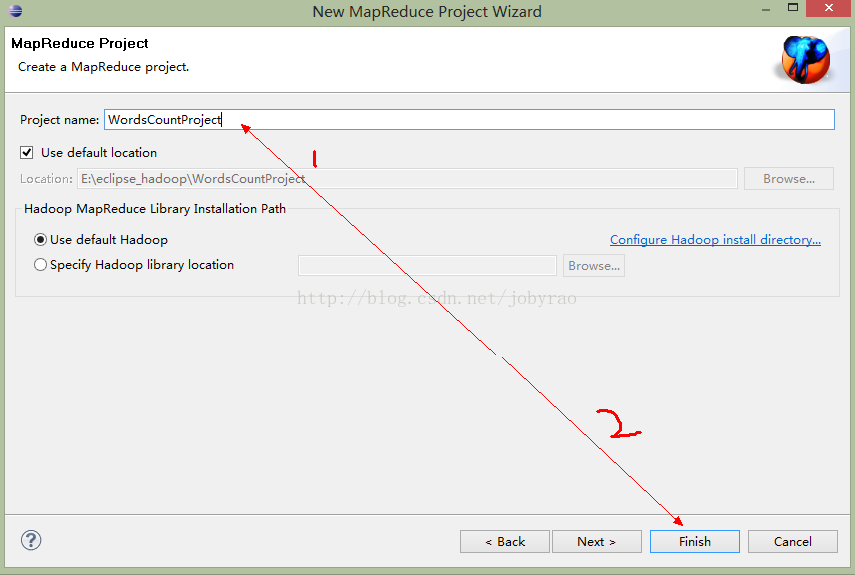
2.以上一个mapReduce项目就创建完成了,接下来就是代码示例(WordCount.java):
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.ha
搭建好环境的前提下!!!
1.创建mapReduce项目
2.以上一个mapReduce项目就创建完成了,接下来就是代码示例(WordCount.java):
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.ha
 2347
1万+
2347
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















