







python网络爬虫学习
(一)通过GET和POST方式获取页面内容
网络爬虫,即Web Spider,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
HTTP协议中定义了四个与服务器进行交互的方法,分别是GET, POST,PUT,DELETE ,实际对应对服务器内容的“增”删“改”查“四个操作
本篇文章主要记录我学习GET和POST请求方式的过程
首先,如何区分GET 和POST请求?
我们可以简单地通过浏览器地址栏是否改变来加以区分。举例说明,在百度上搜索CSDN时,页面会跳转到搜索结果页,同时浏览器上方的URL也会发生改变。
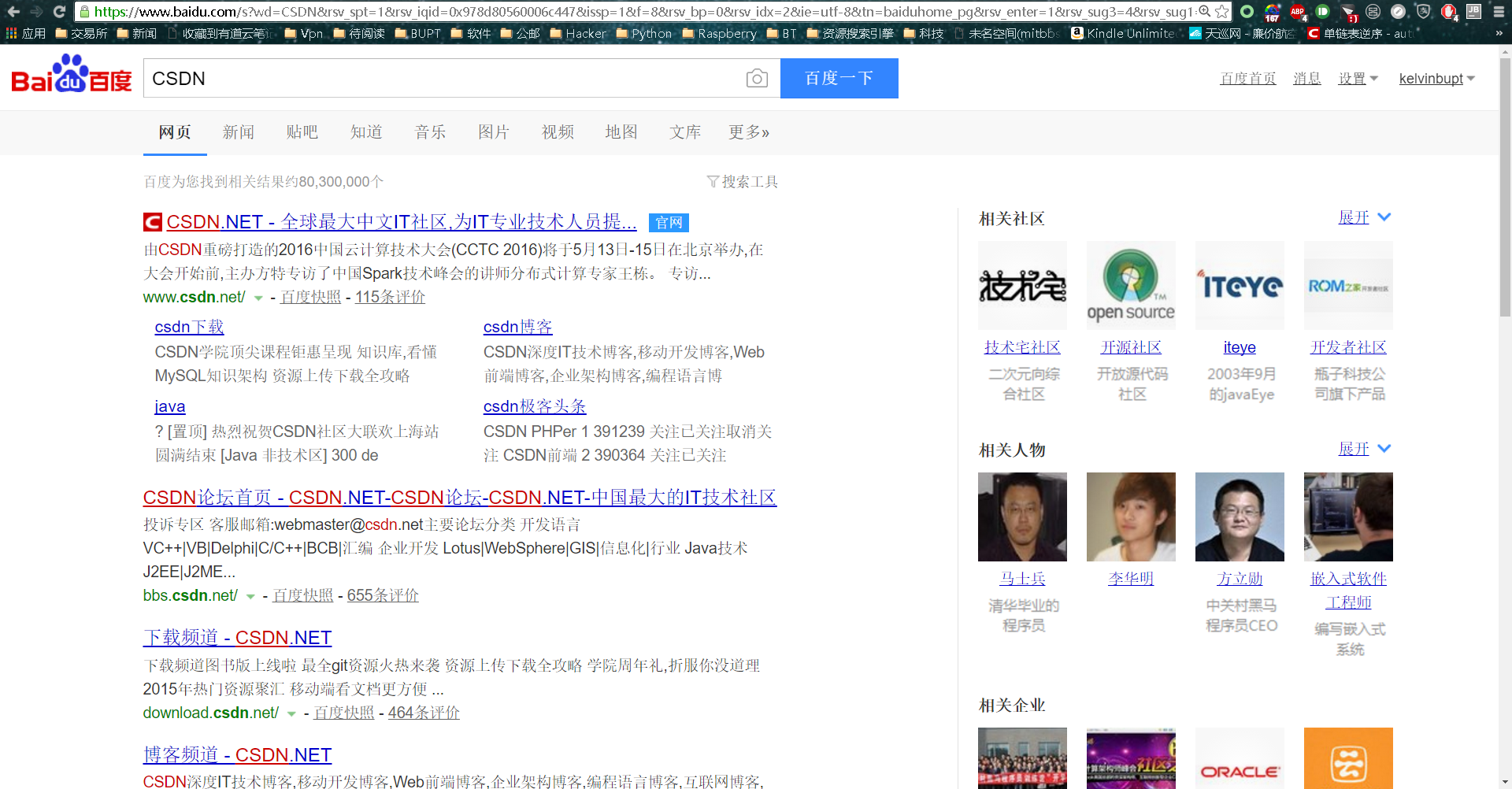
如上图所示,变化就在于,在最初的url后面会附加相关的字段,以?分割url和请求的数据,这些数据就是你要查询字段的编码。。而这个过程,就是典型的GET请求的情况。
POST请求则显得”深藏不露“。它在于你必须通过浏览器输入或提交一些服务器需要的数据,才能给你返回完整的界面,这点其实与GET请求情况有相通之处,但是这个过程浏览器的地址栏是不会发生跳转的。
那POST请求提交的数据是如何传给服务器的呢?可以采用一些分析页面的手段来获取上传的数据。实际上,POST请求是将提交的数据放在HTTP包的包体中,这种方式无疑加强了数据的安全性,不像GET请求那样,用户可以通过跳转的url就可以查看出向服务器发送的数据。另外,PO
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









