







回顾一下cs224d中提及的神经网络在nlp中的应用.
word2vec
A Neural Probabilistic Language Model
z在nlp任务中, 我们希望将词表达为一个向量, 而通常来说词库都会非常大, 采用one-hot 编码的话, 假设词库的容量是 V , 那么每一个词都是一个
Window besed Co-occurrence Matrix 的方法, 这种方法有几个缺点:
1. 新词加入的时候矩阵的维度要改变
2. 矩阵过于稀疏, 因为大多数词是不相关的
3. 矩阵维度过大(≈106×106)
4. 训练时间过长, o(n2)
5. 需要一些技巧来解决词频的不均衡性
我们希望通过概率模型来改进这种算法, 如Unigram, Bigram模型就假设了词与前面一或两个词的出现相关. 这种都是基于统计的角度来考虑的. 在2003年, Bengio 发表了一篇用神经网络来训练词向量的文章[1].
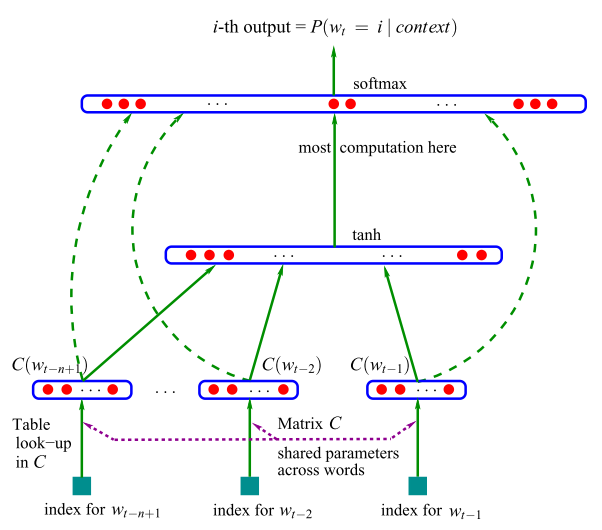
通过前面的n 个词来预测下一个词:
y=b+Wx+Utanh(d+Hx)
. 其中
x 是词库矩阵 C的拼接.
x=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









