





Abstract
我们提出了author-topic model,一个利用LDA将作者信息也包含进来的文档生成模型。每一个作者都与主题的多项式分布有关联,每一个主题都与词的多项式分布相关联。一份包含多个作者的文档被建模成一个在主题上关于该文档作者的混合分布。我们将该模型应用到一个包含1700篇NIPS会议论文与160000篇CiteSeer文献摘要的数据集中。精确地推理对于这些数据集是非常困难的,所以我们利用Gibbs sampling去估算主题与作者的分布。我们比较了两种文档生成模型的性能,这些模型是author-topic model的特例:LDA(一种主题模型)和作者模型(每一个作者都与词分布相关而不是主题分布)。我们利用author-topic model来展示这些主题,并且展现了计算作者间相似性与作者输出熵的应用。
1. Introduction
特征化文档内容在信息检索、统计自然语言处理、机器学习中是一个稀疏平常问题。一个文档内容所表示的可以被用于组织、聚类、或者查询一类文档。最近,文档生成模型已经开始被用于探索基于主题内容的展示,将每一个文档建模成一个混合的概率主题 (e.g., Blei, Ng, & Jordan, 2003; Hofmann, 1999).
在这里,我们考虑这些方法如何被用于解决由大量文档集合所带来的根本问题:建模作者的兴趣点。
通过对作者的兴趣点建模,我们可以解决一系列关于文档集合内容的问题。拥有一个合适的作者模型,我们可以确定作者所写作的主题,作者所写的文档可能与观察文档相似,还有作者所做的相似的工作。然而,研究作者模型已经趋向于关注作者的身份识别问题 - 谁写了什么文档 - 对于这两个方面中的哪一方面离开在相对不明显的特征的基础上判别模型通常是高效的。比如,利用“stylometric (Stylometry, or the study of measurable features of (literary) style, such as sentence length, vocabulary richness and various frequencies (of words, word lengths, word forms, etc.), has been around at least since the middle of the 19th century, and has found numerous practical applications in authorship attribution research.)”方法(e.g., Holmes & Forsyth, 1995)找到文本特征(e.g., frequency of certain stop words, sentence lengths, diversity of an author’s vocabulary),判别不同的作者。
在此篇论文中,我们阐述了对于文本集的生成模型,author-topic model,与此同时,我们对文档内容及作者兴趣进行了建模。这个生成模型代表了每个文档和与其相对应的混合主题,就像是现在最先进的方法LDA(Blei et al., 2003),将这些方法通过让不同主题的混合权重被其文档作者所决定的方式来应用到作者建模中。通过学习模型的参数,我们获得了出现在语料库中的主题集及其与不同文档的相关性,以及识别哪些作者使用了那哪些主题。
本篇论文的组织结构 如下。在第2节中,我们讨论了拥有作者与主题的文档生成模型,并且介绍了一下author-topic model。我们将在第3节说说用于推算模型参数的Gibbs sampler,然后在第4节中,我们得出将该算法应用到计算机科学文档的两个集合 – NIPS会议论文及CIteSeer数据库摘要中的结果。我们在第5节总结并讨论了未来更深层次的研究。
2. Generative models for documents
我们详述了三种文档生成模型:一种是将文档建模成混合的主题 (Blei et al., 2003),另一个是将作者建模成一个基于词的分布,还有一个是利用主题将作者与文档同时建模。所有这三种模型都是使用的同一种标记法。一个文档
d
是一个词
2.1 Modeling documents with topics
最近一些用于对文档内容进行建模的方法都是基于一个文档中的词的概率分布可以被表达为混合主题的思想,其中每一个主题都是基于词的概率分布 (e.g., Blei, et al., 2003; Hofmann, 1999)。我们将详述这么一个模型 - LDA。在LDA中,文档集合生成的建模过程一般分为三步。第一,对于每一份文档,一个主题分布是从Dirichlet Distribution中取样的。第二,对于在文档中的每一个词,我们根据第一步的主题分布来选择一个单独的主题。最后,每一个词都从基于针对第一、二步所采样主题的词的多项式分布中取样。
这一生成过程对应于图1(a)所示的分层贝叶斯模型hierarchical Bayesian model(使用“盘子表示法plate notation”)。在该模型中,
ϕ
表示主题分布的矩阵,其中,
T
个主题中的每一个词分布
2.2 Modeling authors with words
主题模型验证了文档是如何被建模成一个混合的概率分布的。由此,我们提出了一个简单的模型去建模作者的学术偏好。假设有一组作者,
ad
,准备去写这一篇文档
d
. 对于在文档中的每一个词,一个作者被随机均匀的选出。一个词从一个针对于所选出的作者的基于词的概率分布中选出。
这个模型与McCallum在1999年所提出的混合模型相似,它还与一个LDA的变种差不多,这个LDA变种的混合权重对于不同主题是固定不变的。下面所说的图模型在图1(b)中显示。
2.3 The author-topic model
该author-topic model集合了以上两个模型的优点,定义如下:利用一个基于主题的“表现”(大家知道什么意思就好,实在翻译不出来)同时对文档内容及作者的学术偏好进行建模。在author-topic model 中,一组作者用
ad
表示,文档用
d
表示。文档中的每一个关于作者的词都是随机的均匀的被选取出来。然后,在topic model中,从一个针对于作者的主题分布中选出一个主题,然后,从所选择出的主题中生成该词。
与该graphical model所对应的这一过程在图1(c)中展示。在author model中,
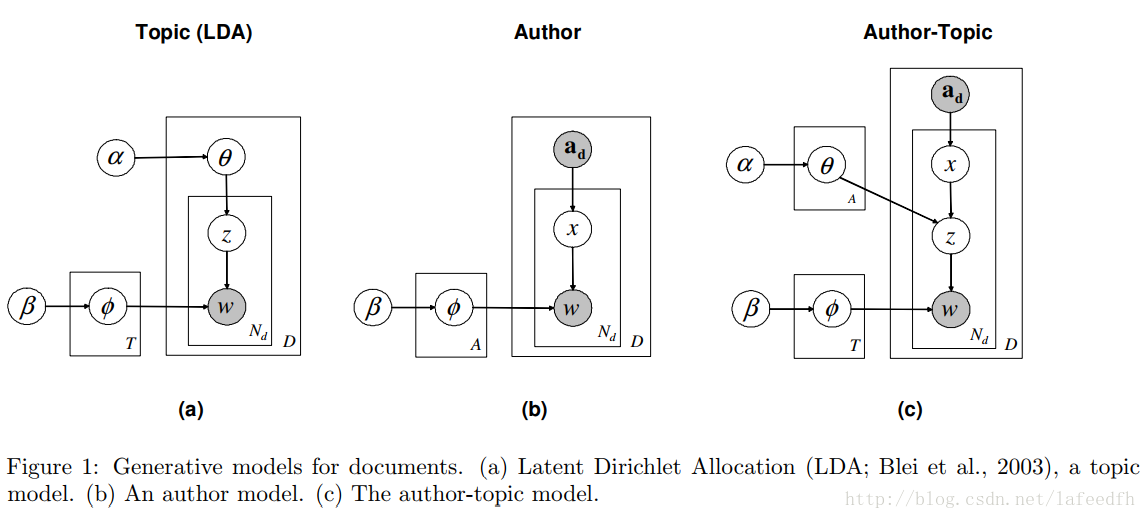
该author-topic model包含了上述两种模型的特殊情况:topic models像是LDA,与之相对应的特殊情况是每一篇文档都只有一个独一无二的作者,author model与之相对应的特殊情况是每一个作者有且只有一个话题。通过估测参数
3. Gibbs sampling algorithms
各种算法被用于估量topic models的参数,从基础的EM期望最大化算法 (EM; Hofmann, 1999),到大概的推理的方法,像是 vartional EM算法(Blei et al., 2003),还与吉布斯采样Gibbs sampling (Griffiths & Steyvers, 2004)。EM算法通常被用于解决在这些模型中求局部最大值(最优)(Blei et al., 2003),
翻译太渣渣,欢迎纠错
(持续更新ing)
(持续更新ing)
PS:原文在这里~
The Author-Topic Model for Authors and Documents(Paper)














 7684
7684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









