






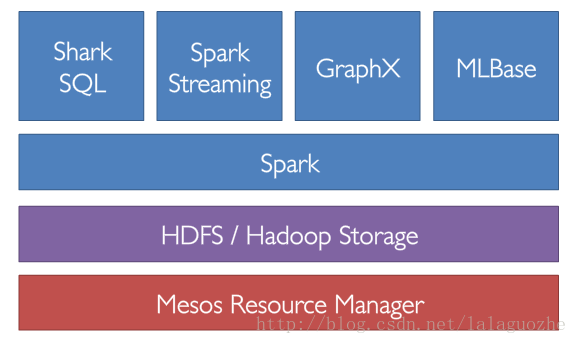
Spark是UC Berkeley AMPLab开发的类MapRed计算框架。MapRed框架适用于batch job,但是由于它自身的框架限制,第一,pull-based heartbeat作业调度。第二,shuffle中间结果全部落地disk,导致了高延迟,启动开销很大。而Spark是为迭代式,交互式计算所生的。第一,它采用了actor model
的akka
作为通讯框架。第二,
它
使
用了RDD分布式内存,操作之间的数据不需要dump到磁盘上,而是通过RDD Partition
分
布
在各个节点内存中
,
极大的提高了数据间的流转,
同
时RDD之间维护了血统关系,一旦RDD fail掉了,能通过父RDD自动重建,
保
证了fault tolerance,而在Spark之上有丰富的应用,比如
Shark,Spark Stre
aming,MLBase。我们在生产环境中已经使用Shark来作为Hive的一种补充,它共享了hive 的metastore,serde
,
使用方式也和hive几乎一样,如果
data input size不是很大的情况下,相同语句
确实比hive
会快很多,后续会单独写一篇来详解。
Spark software stack
本篇介绍下spark的安装:
Spark可以运行在统一资源调度器上,比如YARN, Mesos,也可以独立部署Standalone模式,由于我们YARN集群还没上,所以暂时用Standalone模式,它是master/slave模式,由一个spark master和一组spark worker构成,Standalone模式只支持FIFO调度策略,而且默认情况下提交一个job会占用掉spark集群所有的core,这样就变一个集群只能运行一个job了,需要设置spark.cores.max值来做调整
部署环境:
Spark Master: test85.hadoop
Spark Worker: test88.hadoop, test89.hadoop, test90.hadoop, test91.hadoop
1. 保证Master和Worker节点SSH打通
2. 由于Spark会使用hadoop client来和hdfs交互,所以每个节点需要安装Hadoop Client
3. 安装Scala,Scala 2.10.2版本和Spark有冲突,所以只能安装Scala 2.9.3
wget http://spark-project.org/download/spark-0.7.3-prebuilt-hadoop1.tgz
tar xzvf spark-0.7.3-prebuilt-hadoop1.tgz
ln -s spark-0.7.3 spark-release
在/etc/profile加上环境变量
export SPARK_HOME=/usr/local/spark-release
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SPARK_HOME/bin:$SCALA_HOME/bin设置Spark的configuration文件,在$ SPARK_HOME/conf/ spark-env.sh中
设置Spark的configuration文件,在$SPARK_HOME/conf/spark-env.sh中
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export SPARK_EXAMPLES_JAR=$SPARK_HOME/examples/target/scala-2.9.3/spark-examples_2.9.3-0.7.3.jar
export SPARK_SSH_OPTS="-p58422 -o StrictHostKeyChecking=no"
export SPARK_MASTER_IP=test85.hadoop
export SPARK_MASTER_WEBUI_PORT=8088
export SPARK_WORKER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=4
export SPARK_WORKER_MEMORY=8g
export LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib
export SPARK_LIBRARY_PATH=/usr/local/hadoop/hadoop-release/lib/native/Linux-amd64-64
slaves文件中加入worker地址
# A Spark Worker will be started on each of the machines listes below
test88.hadoop
test89.hadoop
test90.hadoop
test91.hadoop
同步配置文件和Spark,Scala到整个集群
启动spark master
bin/start-master.sh
13/09/23 09:46:57 INFO Slf4jEventHandler: Slf4jEventHandler started
13/09/23 09:46:57 INFO ActorSystemImpl: RemoteServerStarted@akka://sparkMaster@test85.hadoop:7077
13/09/23 09:46:57 INFO Master: Starting Spark master at spark://test85.hadoop:7077
13/09/23 09:46:57 INFO IoWorker: IoWorker thread 'spray-io-worker-0' started
13/09/23 09:46:57 INFO HttpServer: akka://sparkMaster/user/HttpServer started on /0.0.0.0:8088
启动spark workers
bin/start-slaves.sh
13/09/23 09:47:54 INFO Slf4jEventHandler: Slf4jEventHandler started
13/09/23 09:47:55 INFO ActorSystemImpl: RemoteServerStarted@akka://sparkWorker@test89.hadoop:36665
13/09/23 09:47:55 INFO Worker: Starting Spark worker test89.hadoop:36665 with 4 cores, 8.0 GB RAM
13/09/23 09:47:55 INFO Worker: Spark home: /usr/local/spark-0.7.3
13/09/23 09:47:55 INFO Worker: Connecting to master spark://test85.hadoop:7077
13/09/23 09:47:56 INFO ActorSystemImpl: RemoteClientStarted@akka://sparkMaster@test85.hadoop:7077
13/09/23 09:47:57 INFO IoWorker: IoWorker thread 'spray-io-worker-0' started
13/09/23 09:47:58 INFO HttpServer: akka://sparkWorker/user/HttpServer started on /0.0.0.0:8099
13/09/23 09:47:58 INFO Worker: Successfully registered with master运行计算PI的job
./run spark.examples.SparkPi spark://test85.hadoop:7077
[hadoop@test85 spark-release]$ ./run spark.examples.SparkPi spark://test85.hadoop:7077
13/09/23 10:15:59 INFO Slf4jEventHandler: Slf4jEventHandler started
13/09/23 10:15:59 INFO SparkEnv: Registering BlockManagerMaster
13/09/23 10:15:59 INFO MemoryStore: MemoryStore started with capacity 323.9 MB.
13/09/23 10:15:59 INFO DiskStore: Created local directory at /tmp/spark-local-20130923101559-6a72
13/09/23 10:15:59 INFO ConnectionManager: Bound socket to port 54795 with id = ConnectionManagerId(test85.hadoop,54795)
13/09/23 10:15:59 INFO BlockManagerMaster: Trying to register BlockManager
13/09/23 10:15:59 INFO BlockManagerMaster: Registered BlockManager
13/09/23 10:15:59 INFO HttpBroadcast: Broadcast server started at http://10.1.77.85:58290
13/09/23 10:15:59 INFO SparkEnv: Registering MapOutputTracker
13/09/23 10:15:59 INFO HttpFileServer: HTTP File server directory is /tmp/spark-22ef9d2b-0e57-42e2-ae90-a9cd99233c1c
13/09/23 10:16:00 INFO IoWorker: IoWorker thread 'spray-io-worker-0' started
13/09/23 10:16:00 INFO HttpServer: akka://spark/user/BlockManagerHTTPServer started on /0.0.0.0:46611
13/09/23 10:16:00 INFO BlockManagerUI: Started BlockManager web UI at http://test85.hadoop:46611
13/09/23 10:16:00 INFO SparkContext: Added JAR /usr/local/spark-release/examples/target/scala-2.9.3/spark-examples_2.9.3-0.7.3.jar at http://10.1.77.85:51299/jars/spark-examples_2.9.3-0.7.3.jar with timestamp 1379902560222
13/09/23 10:16:00 INFO Client$ClientActor: Connecting to master spark://test85.hadoop:7077
13/09/23 10:16:00 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20130923101600-0000
13/09/23 10:16:00 INFO Client$ClientActor: Executor added: app-20130923101600-0000/0 on worker-20130923094755-test89.hadoop-36665 (test89.hadoop) with 4 cores
13/09/23 10:16:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20130923101600-0000/0 on host test89.hadoop with 4 cores, 512.0 MB RAM
13/09/23 10:16:00 INFO Client$ClientActor: Executor added: app-20130923101600-0000/1 on worker-20130923094752-test90.hadoop-39876 (test90.hadoop) with 4 cores
13/09/23 10:16:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20130923101600-0000/1 on host test90.hadoop with 4 cores, 512.0 MB RAM
13/09/23 10:16:00 INFO Client$ClientActor: Executor added: app-20130923101600-0000/2 on worker-20130923094751-test91.hadoop-53527 (test91.hadoop) with 4 cores
13/09/23 10:16:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20130923101600-0000/2 on host test91.hadoop with 4 cores, 512.0 MB RAM
13/09/23 10:16:00 INFO Client$ClientActor: Executor added: app-20130923101600-0000/3 on worker-20130923094752-test88.hadoop-43591 (test88.hadoop) with 4 cores
13/09/23 10:16:00 INFO SparkDeploySchedulerBackend: Granted executor ID app-20130923101600-0000/3 on host test88.hadoop with 4 cores, 512.0 MB RAM
13/09/23 10:16:00 INFO SparkContext: Starting job: reduce at SparkPi.scala:22
13/09/23 10:16:00 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:22) with 2 output partitions (allowLocal=false)
13/09/23 10:16:00 INFO DAGScheduler: Final stage: Stage 0 (map at SparkPi.scala:18)
13/09/23 10:16:00 INFO DAGScheduler: Parents of final stage: List()
13/09/23 10:16:00 INFO DAGScheduler: Missing parents: List()
13/09/23 10:16:00 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[1] at map at SparkPi.scala:18), which has no missing parents
13/09/23 10:16:00 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[1] at map at SparkPi.scala:18)
13/09/23 10:16:00 INFO ClusterScheduler: Adding task set 0.0 with 2 tasks
13/09/23 10:16:00 INFO Client$ClientActor: Executor updated: app-20130923101600-0000/2 is now RUNNING
13/09/23 10:16:00 INFO Client$ClientActor: Executor updated: app-20130923101600-0000/3 is now RUNNING
13/09/23 10:16:00 INFO Client$ClientActor: Executor updated: app-20130923101600-0000/1 is now RUNNING
13/09/23 10:16:00 INFO Client$ClientActor: Executor updated: app-20130923101600-0000/0 is now RUNNING
13/09/23 10:16:02 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka://sparkExecutor@test90.hadoop:44054/user/Executor] with ID 1
13/09/23 10:16:02 INFO TaskSetManager: Starting task 0.0:0 as TID 0 on executor 1: test90.hadoop (preferred)
13/09/23 10:16:02 INFO TaskSetManager: Serialized task 0.0:0 as 1339 bytes in 35 ms
13/09/23 10:16:02 INFO TaskSetManager: Starting task 0.0:1 as TID 1 on executor 1: test90.hadoop (preferred)
13/09/23 10:16:02 INFO TaskSetManager: Serialized task 0.0:1 as 1339 bytes in 1 ms
13/09/23 10:16:02 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka://sparkExecutor@test91.hadoop:34433/user/Executor] with ID 2
13/09/23 10:16:02 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka://sparkExecutor@test89.hadoop:53079/user/Executor] with ID 0
13/09/23 10:16:02 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager test91.hadoop:49214 with 323.9 MB RAM
13/09/23 10:16:02 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager test90.hadoop:33628 with 323.9 MB RAM
13/09/23 10:16:02 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka://sparkExecutor@test88.hadoop:38074/user/Executor] with ID 3
13/09/23 10:16:03 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager test88.hadoop:55313 with 323.9 MB RAM
13/09/23 10:16:03 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager test89.hadoop:37899 with 323.9 MB RAM
13/09/23 10:16:03 INFO TaskSetManager: Finished TID 1 in 1128 ms (progress: 1/2)
13/09/23 10:16:03 INFO TaskSetManager: Finished TID 0 in 1175 ms (progress: 2/2)
13/09/23 10:16:03 INFO DAGScheduler: Completed ResultTask(0, 1)
13/09/23 10:16:03 INFO DAGScheduler: Completed ResultTask(0, 0)
13/09/23 10:16:03 INFO DAGScheduler: Stage 0 (map at SparkPi.scala:18) finished in 2.939 s
13/09/23 10:16:03 INFO SparkContext: Job finished: reduce at SparkPi.scala:22, took 2.976491771 s
Pi is roughly 3.14368参考文档:

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









