






这篇论文主要讲的是Hinton和他的学生在参加LSVRC-2010和2012比赛中用到的网络结构。
主要分为以下几个方面:
1.ReLU非饱和非线性激活函数
这里主要讲的是ReLU函数相对与传统的sigmoid和tanh函数的优势。论文中提到ReLU属于非饱和非线性函数,性对于传统的sigmoid和tanh等饱和非线性激活函数有着收敛速度更快的优势。非饱和是指,随着x轴上变量的增大变得比较大时,y轴的值依旧增长很快,相反,饱和的是指,当x轴变量变得比较大时,函数值增长的幅度很小。
2.在多个GPU上训练
在他们网络的训练过程中,采用了两个GTX 580 GPU进行训练,在训练的过程中将网络的节点平均分布到两个GPU上。这里有一个训练的小trick,在有的网络层中,两个GPU根本不通信,只在指定的一个或几个网络层中,两个GPU互相通信。具体的工作模式在后面讲到。
但是这里有一个问题,就是如何控制GPU之间进行这样的操作?我目前还没有用过多GPU进行网络训练,可能会用到CUDA?以后用到后再说。
3.局部相应归一化(LRN,Local Response Normalization)
本文提出虽然ReLU对与输入很大的x仍然能够很快的进行学习,但是使用归一化依然能够进一步提升效果。
设
aix,y
为在位置
(x,y)
处应用第i个卷积核运算,并经ReLU激活后的值,按如下公式进行归一化运算:
其中 n 为与当前的kernel临近的
N 为当前层所有的kernel数
4.Overlapping Pooling
普通的下采样是不重叠的,但是对于有重叠的下采样可以保留更多的信息,可以在一定程度上提高准确率。同时这样在sightly程度上防止过拟合。
5.整体的网络架构
如图所示:
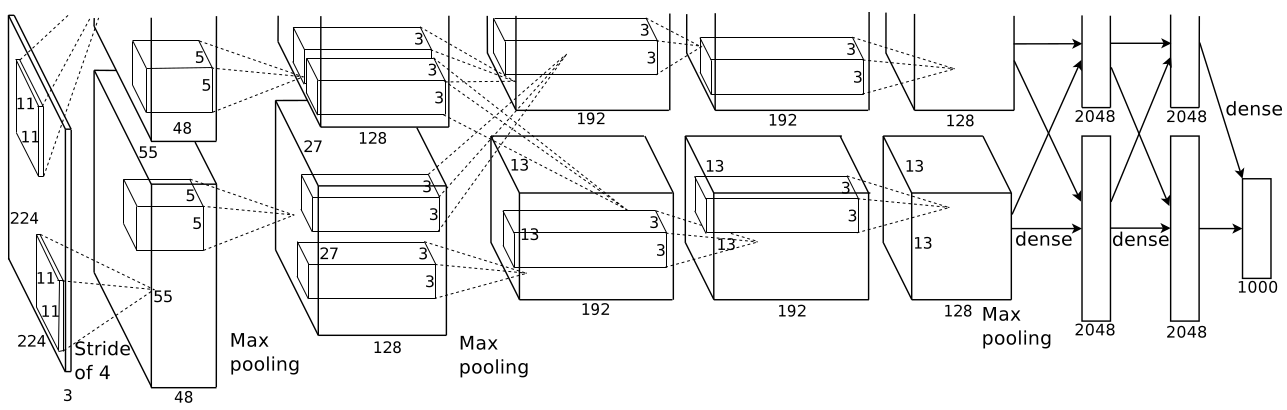
网络共分为8层,其中有5个卷基层和3个全链接层,第一个卷基层卷积模板为11*11*3,共有96个这样的卷积核,得到的feature maps分别分布在两个不同的GPU上。然后第二层卷积只是在各自的CPU上进行卷积,这两组48个feature maps组与组之间没有关联,在第三层才有关联有3*3*256的卷积核,共384个。同理后面的网络结构。
6.降低过拟合
论文中提到这么大的网络,即使是在ImageNet这样大的数据库上进行训练,也会产生过拟合,因此采用如下两种方法降低过拟合
(1)增大数据
对训练的图像进行变换,如平移,水平翻转等以增大数据量。论文中从256*256的图像中及其翻转图像中随机提取224*224的图像。
论文还提到了对图片的RGB通道进行强度改变。即在训练集的RGB通道上做PCA,但是不降维,只取特征向量和特征值,对训练集上每张图片的每个像素
其中 pi 和 λi 分别表示特征向量和特征值, α 表示高斯随机变量(均值为0,方差为0.1)
(2)Dropout
dropout层一般用在FC层之后,每次forward的时候FC之前层的每个神经元会以一定的概率不参与forward,而backward的时候这些单元也不参与。这种方式使得网络强制以部分神经元来表示当前的图片,很大限度上降低过拟合。但是这样一定程度上会延长训练的时间,因为随机性不只是会打乱过拟合的过程,也会打乱正常拟合的过程。
在test的时候,不使用dropout,使所有神经元参与运算,给他们的结果乘以0.5来作为输出值。
其实,最后不乘0.5也是可以的。如果在分类的时候使用的不是原来的softmax,那么只要特征之间可以区分就行了,乘不同的系数只是放大或者缩小了这种差别。















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









