









我们在开发中会经常遇到限制字符串长度的情况,如输入框限制输入字数,我们会经常使用substringToIndex进行字符串截取,这样做有一个潜在的问题,那就是当截取的index恰好是一个emoji表情的时候,因为一个emoij在字符串的length并不等于1,这样就会把emoji表情分割开来,从而造成整个字符串不显示或者最后一个字符是乱码的情况。
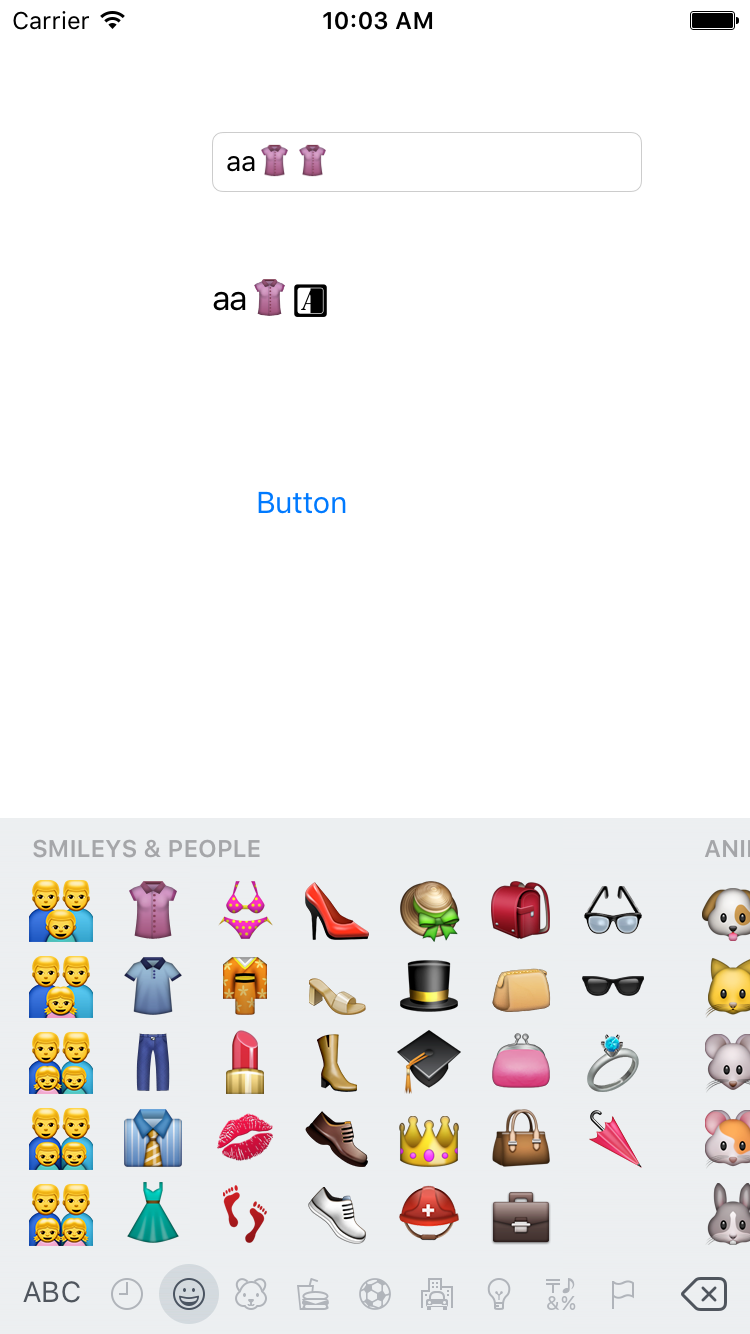
起初我发现截取一半的emoji的时候吧字符串进行UTF8String转码后为NULL,所以根据此我写了这样一个方法:
-(NSString *)subStringWith:(NSString *)string ToIndex:(NSInteger)index{
NSString *result = string;
const char *res = [result substringToIndex:index].UTF8String;
if (res == NULL) {
result = [result substringToIndex:index - 1];
}else{
result = [result substringToIndex:index];
}
return result;
}即少截取一个字符以避免截取到emoji的情形。
但是放到以前还行,现在的话就会有问题,这种方法是建立在emoji表情都占两个length的长度基础上的,而现在新出的国旗emoji占了四个长度,当截取到emoji的前三个的时候进行转码并不等于NULL。后翻看NSString的文档,发现了这两个方法官方文档没有给出说明,索性试一试:
- (NSRange)rangeOfComposedCharacterSequenceAtIndex:(NSUInteger)index;
- (NSRange)rangeOfComposedCharacterSequencesForRange:(NSRange)range NS_AVAILABLE(10_5, 2_0);我发现当把截取的index传给rangeOfComposedCharacterSequenceAtIndex方法时返回的是index所在的emoji表情的range,所以Objective-C已经考虑到了emoji表情截取的问题,但是没有给出注释。。。
故而修改方法如下:
-(NSString *)subStringWith:(NSString *)string ToIndex:(NSInteger)index{
NSString *result = string;
if (result.length > index) {
NSRange rangeIndex = [result rangeOfComposedCharacterSequenceAtIndex:index];
result = [result substringToIndex:(rangeIndex.location)];
}
return result;
}














 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









