









SVM直观理解总结
本文由 @lonelyrains出品,转载请注明出处。
文章链接: http://blog.csdn.net/lonelyrains/article/details/49509115
1、SVM初衷是基于逻辑回归的线性简化(基础)
改变代价函数整体的常系数并不影响梯度调优时
Θ
矩阵的选取,所以修正一下
λ
,并消掉了样本量
m
的系数。
Sigmoid阈值计算比较麻烦,而且偏向0.5的时候难以说明情况好坏,所以优化为线性简化。如果y实际值为1,则希望
故线性简化代价函数如下图:

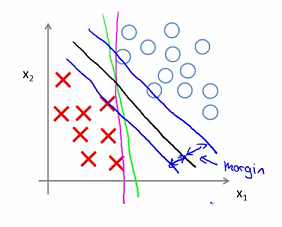
2、SVM的LargeMargin边界(加工)
如何找到的是黑色分界线,而不是偏向正负样本两边的蓝色分界?如下图
如果代价函数的前半部分为
0
,则希望取
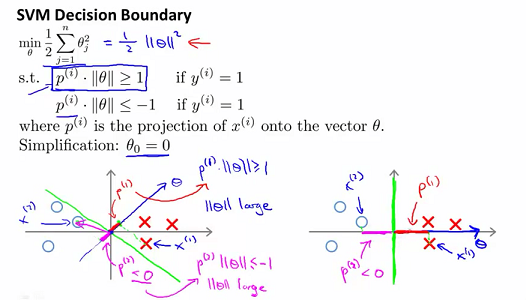
3、SVM核函数(精髓)
线性不可分边界,如果纯粹用
x→
的内部自变量的高维排列组合,会引起组合爆炸。如图:

为了简化问题,取样本核为每一个样本。直观上理解,即每一个样本,都对所有样本求一次相似度。相似度评价函数即核函数。理论上样本随机正态分布,为了相似度满足完全一致时取1,而不一致时接近于0,所以对随机正态分布做了简单的修改。

然后再用这些样本核来做对应的降维后的线性代价函数的自变量,便得到了直观上与对所有
x→
一致的效果。
4、松弛变量参数调优(后期)
如果
C
取得很大,则对应于
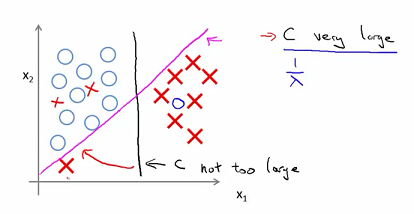















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









