







论文题目:Human-level control through deep reinforcement learning
代码地址:https://sites.google.com/a/deepmind.com/dqn
摘要
强化学习理论提供了一个规范的描述,深深根植于动物行为的心理学和神经科学观点,即关于智能体如何优化他们对环境的控制。然而,为了在接近现实世界复杂性的情况下成功地进行强化学习,智能体面临着一个困难的任务:它们必须从高维感官输入中获得对环境的有效表示,并利用这些将过去的经验推广到新的情况。值得注意的是,人类和其他动物似乎通过强化学习和分层感觉处理系统的和谐结合解决了这个问题。前者由大量的神经数据证明,这些数据揭示了多巴胺能神经元发出的相位信号和时序差分强化学习算法之间的显著相似性。虽然强化学习工具已在多个领域取得了一些成功,但它们的适用性在之前仅限于可以手工标志特征的领域,或者是具有完全观察到的低维状态空间的领域。在这里,我们利用最近在训练深度神经网络方面取得的进展开发了一种新的人工智能体,称为DQN,它可以使用端到端强化学习直接从高维感官输入中学习成功的策略。我们在具有挑战性的 Atari 2600 经典游戏领域对该智能体进行了测试。我们证明了在使用相同的算法、网络架构和超参数的情况下,仅接收像素和游戏得分作为输入的深度 Q 网络智能体能够超越所有先前算法的性能,在 49 款游戏中达到与专业人类游戏测试员相当的水平。这项研究填补了高维感官输入与行动之间的鸿沟,从而产生了第一个能够学习完成各种挑战性任务的人工智能体。
创新点
- 使用深度卷积神经网络来近似最优动作-价值函数
- 经验重放
- 主网络和目标网络
卷积神经网络结构
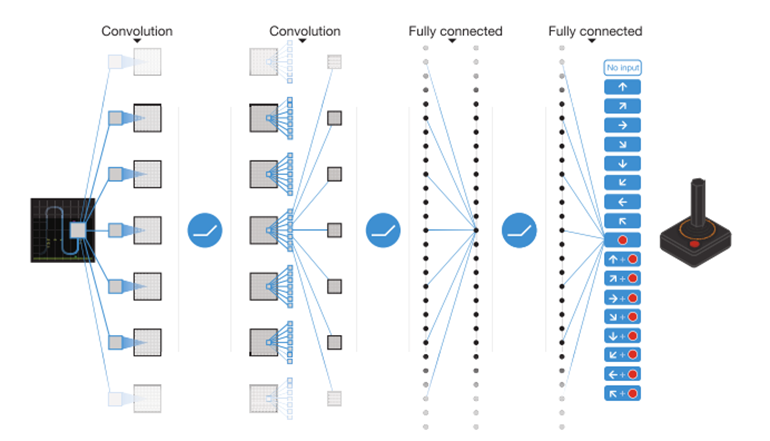
神经网络的输入包括由预处理映射生成的84*84*4图像,然后是三个卷积层(注:蛇形蓝线表示每个滤波器在输入图像上的滑动)和两个全连接层,每个有效动作都有一个输出。每个隐层之后都有一个整流非线性层(即 max(0,x))。
根据网络结构可以看出,DQN仅适用于离散动作空间。
与其余非线性表示不同的一点:网络的输入是状态表示,每个可能的动作都有一个单独的输出单元给出其预测 Q 价值。这样就能通过一次前向传递计算出给的状态下的所有可行动作价值
神经网络的输入由预处理函数生成的 84*84*4图像组成。其他输入还有游戏分数、可选动作数量、生命计数。
第一个隐藏层使用 32 个 8x8 卷积进行步长为 4 的卷积操作,接 Relu 激活函数;第二个隐藏层使用 64 个 4x4 卷积核进行步长为 2 的卷积操作,接 Relu 激活函数;第三个卷积层使用 64 个 3x3 卷积核进行步长为 1 的卷积操作,接 Relu 激活函数;最后一个隐藏层是 512 个 Relu 单元组成的全连接层;输出层是一个线性全连接层,每个有效动作都对应一个输出
至于为什么要选择CNN,这是因为测试环境都是 Atria 的 2D 游戏,所以使用了擅长提取图像特征的 CNN 卷积神经网络作为嵌入函数,降低agent observation的维度
经验回放
在这种技术中,我们将智能体在每个时间步的经验et=(st, at, rt, st+1)存储在数据集Dt={e1,…,et}中,并将许多回合(当达到终端状态时发生回合结束)汇集到重放记忆中。在算法的内部循环中,我们对从存储样本池中随机抽取的经验样本应用Q-learning更新或小批量更新。与标准在线Qlearning相比,这种方法有几个优点。
- 每一步的经验都可能用于许多权重更新,这允许更高的数据效率。
- 直接从连续样本中学习是低效的,因为样本之间有很强的相关性;随机化样本打破了这些相关性,因此减少了更新的方差。
- 当学习on-policy时,当前参数决定参数被训练的下一个数据样本。例如,如果最大化动作是向左移动,那么训练样本将由左侧的样本主导;如果最大化动作切换到右边,那么训练分布也会切换。很容易看到不必要的反馈回路是如何产生的,参数可能会陷入困境或局部最小值,甚至灾难性地偏离。
通过使用经验重放,行为分布在其先前的许多状态上均匀,平滑学习并避免参数的振荡或发散。请注意,当通过经验重放学习时,有必要进行off-policy学习(因为我们当前的参数与用于生成样本的参数不同),这激发了Q-learning的选择。
在实践中,我们的算法只将最后的经验元组存储在回放内存中,并在执行更新时随机采样。这种方法在某些方面是有限的,因为内存缓冲区不区分重要的转换,并且由于有限的内存大小N,总是用最近的转换覆盖。同样,统一采样让回放内存中的所有转换具有同等重要性。更复杂的采样策略可能会强调我们学到最多东西的转换,类似于优先级扫描。
目标网络和主网络
克隆网络Q来获得一个目标网络,并使用
来生成Q-learning的目标yj,用于后续的Q-learning update。
与标准的在线Q-learning相比,这种修改使算法更加稳定,在标准的在线Q-learning中,增加Q (st,at)的更新通常也会增加所有a的Q (st+1,a),因此也会增加目标yj,可能导致策略的振荡或发散。使用一组较旧的参数生成目标,会在更新Q的时间和更新影响目标yj的时间之间增加延迟,使发散或振荡更难。
除此之外,目标网络打断了 DQN 自身的 Bootstrapping 操作,一定程度上缓解了 Q 价值高估问题
附加
把TD error,即![]() 控制在-1到1之间。因为绝对值损失函数|x|对所有负值的x都有导数为-1,对所有正值的x都有导数为1,所以将平方误差裁剪为-1到1之间对应于对(-1,1)区间以外的误差使用绝对值损失函数。这进一步提高了算法的稳定性。
控制在-1到1之间。因为绝对值损失函数|x|对所有负值的x都有导数为-1,对所有正值的x都有导数为1,所以将平方误差裁剪为-1到1之间对应于对(-1,1)区间以外的误差使用绝对值损失函数。这进一步提高了算法的稳定性。
算法理论
![]() :代表当前屏幕像素值的一个向量,模拟器生成的图像。
:代表当前屏幕像素值的一个向量,模拟器生成的图像。
![]() :动作和观察序列,每个序列都是一个不同的状态,因此,我们只需使用完整序列st作为t时间的状态表示
:动作和观察序列,每个序列都是一个不同的状态,因此,我们只需使用完整序列st作为t时间的状态表示
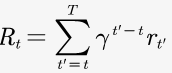 :return
:return
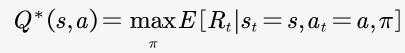 :最优action-value
:最优action-value
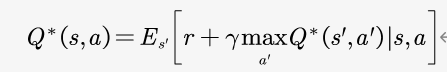
![]() :目标值
:目标值
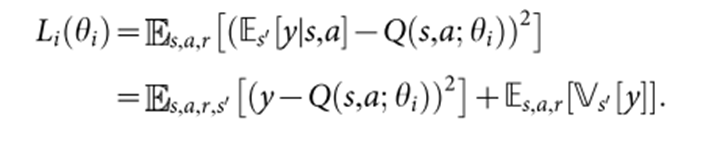 :损失函数
:损失函数
对损失函数求梯度: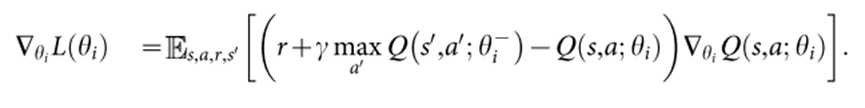
该算法是model-free:它直接使用来自模拟器的样本来解决强化学习任务,而无需直接估计奖励和状态转移。它也是off-policy:,同时遵循确保充分探索状态空间的行为分布。在实践中,行为分布通常由一个-greedy策略选择,该策略遵循概率为的贪婪策略,并选择概率为的随机行为。
伪代码
 因为使用任意长度的历史作为神经网络的输入是很困难的,所以Q函数在上面描述的函数
因为使用任意长度的历史作为神经网络的输入是很困难的,所以Q函数在上面描述的函数产生的固定长度的历史表示上工作。
实验
预处理
1、对单帧进行编码时,取正在编码的帧和上一帧中每个像素颜色值的最大值。因为在游戏中,有些物体只出现在偶数帧中,而另一些物体只出现在奇数帧中,这是由于 Atari 2600 一次能显示的条形图数量有限造成的,这样做可以消除闪烁现象。
2、从 RGB 帧中提取 Y 通道(也称为亮度),并将其调整为 84*84。用函数对 m 个最新帧进行预处理,并将它们堆叠起来,生成 Q 函数的输入。本文取m=4,不过该算法对不同的m值(例如3或5)都很稳定,形成84*84*4的输入张量。
训练细节
在训练期间对游戏的奖励结构作了一处修改。由于不同游戏的评分标准差异很大,将所有正奖励的分值剪切为 1,将所有负奖励的分值剪切为 -1,而 0 分奖励的分值保持不变。通过这种方式对奖励进行剪切,可以限制误差梯度的规模,从而更容易在多个游戏中使用相同的学习率。同时,这可能会影响智能体性能,因为它无法区分不同程度的奖励。
训练期间的行为策略是-贪婪,在前一百万帧中
从1.0 线性退火到 0.1,此后固定为 0.1。我们总共训练了 5000 万帧(即总共约 38 天的游戏体验),并使用了 100 万帧最近帧的经验重放。
使用了一种简单的跳帧技术。智能体在第 k 帧而不是每帧上观察并选择动作,其最后一个动作在跳过的帧上重复。这是因为模拟器向前运行一步所需的计算量远远少于让智能体选择一个动作所需的计算量,因此这种技术可以让智能体多玩大约k倍的游戏,而不会显著增加运行时间。我们使用 k=4 进行所有游戏。
使用 RMSProp 优化方法进行优化
参数在其他所有游戏中均保持不变。所有超参数的值和说明见下表。
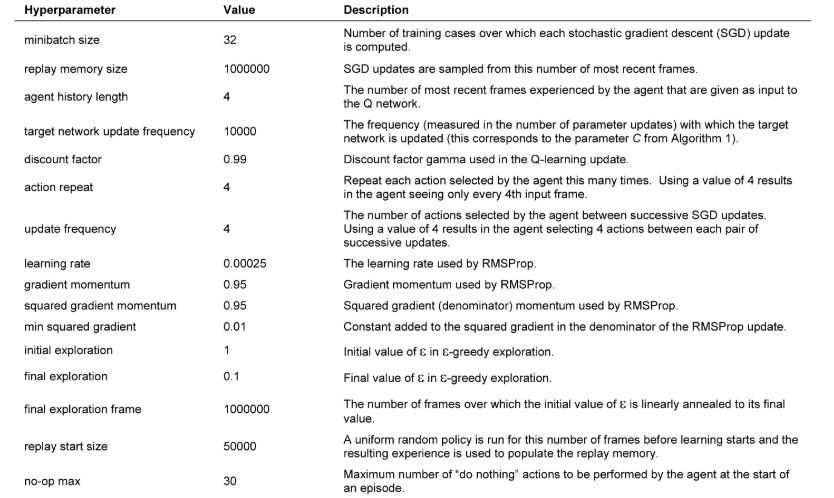
实验设置相当于使用了以下最低限度的先验知识:输入数据包括视觉图像(这促使我们使用卷积深度网络)、游戏特定得分(带名义修饰)、动作数量,但不包括其对应关系(例如,指定向上 "按钮")和生命值。
评价步骤
在不同的初始随机条件("noop";见上表 )和 =0.05 的
-greedy 策略下,每局游戏进行 30 次,每次最多 5 分钟,对训练的智能体进行评估。随机智能体作为基线(baseline)对比,以 10Hz 的频率选择随机动作,即每六帧一次,并在间隔帧中重复上一次动作。
10Hz 是人类玩家选择 "开火 "按钮的最快速度,将随机智能体设置为这一频率可避免在少数游戏中出现虚假的基线分数。我们还评估了以 60Hz(即每帧)选择一个动作的随机智能体的性能。这样做的效果微乎其微:只有六款游戏(拳击、突围、疯狂攀岩、恶魔攻击、Krull 和 Robotank)的归一化 DQN 性能变化超过 5%,而在所有这些游戏中,DQN 的性能都远远超过人类专家。
专业人类测试人员使用与智能体相同的模拟器引擎,并在受控条件下进行游戏。人类测试者不能暂停、保存或重新加载游戏。与最初的 Atari 2600 环境一样,模拟器以 60Hz 的频率运行,音频输出被禁用:因此,人类玩家和智能体之间的感官输入是相同的。人类的表现性能是指在每个游戏中练习2小时后,在每个游戏中最多持续 5 分钟,共进行 20 次回合左右的游戏所获得的平均奖励。
在Atari 2600 平台,该平台提供了一系列不同的游戏任务(n=49)。在实验中使用相同的网络架构、超参数值和学习程序,两个学习指标(智能体每个回合的平均得分和平均预测 Q 值)
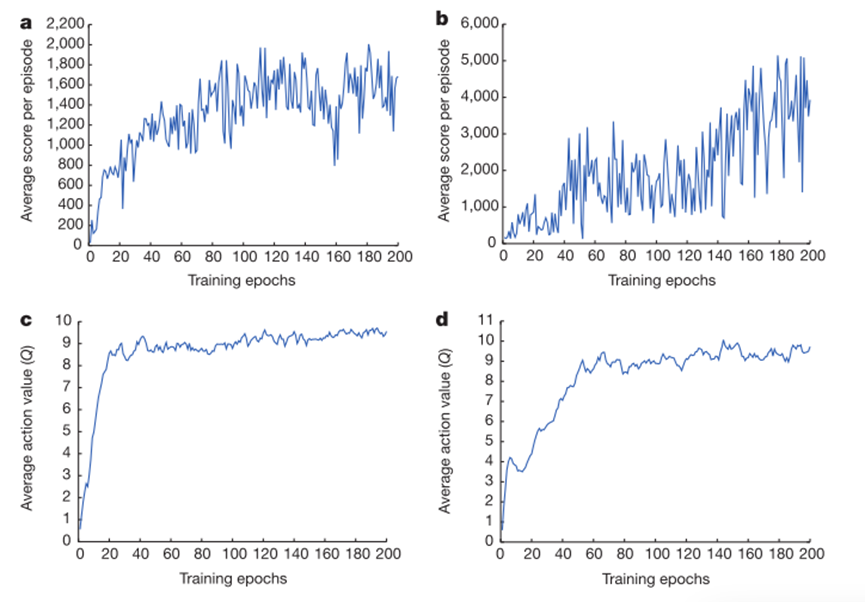 跟踪智能体平均得分和平均预测动作价值的训练曲线。a 每个点都是智能体在《太空侵略者》游戏中使用
跟踪智能体平均得分和平均预测动作价值的训练曲线。a 每个点都是智能体在《太空侵略者》游戏中使用 -greedy 策略(
=0.05)运行 520k 帧后每回合获得的平均分数。b Seaquest 每回合的平均得分。c《太空入侵者》中被保留状态的平均预测动作值。曲线上的每一点都是对保留的状态集计算出的动作值 Q 的平均值。
将 DQN 与强化学习文献中性能最佳的方法进行了比较,还报告了专业人类游戏测试者在受控条件下和统一随机选择行动的策略下的得分
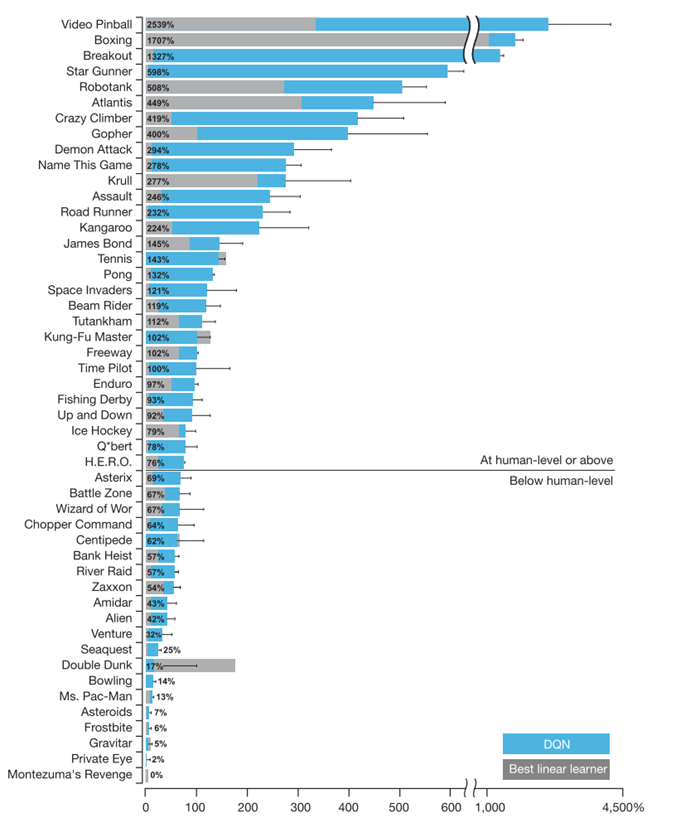
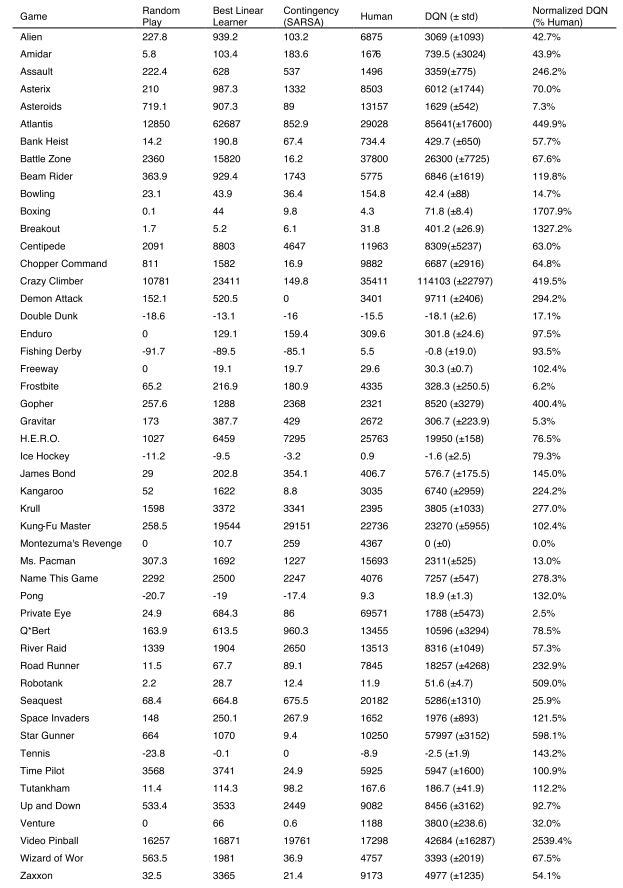
DQN方法在43款游戏中超越了现有的最佳强化学习方法,且无需引入其他方法所使用的关于Atari 2600游戏的额外先验知识。
DQN智能体在49个游戏中的表现与专业人类游戏测试人员的表现不相上下,在超过一半的游戏(29个游戏)中达到了人类得分的75%以上。
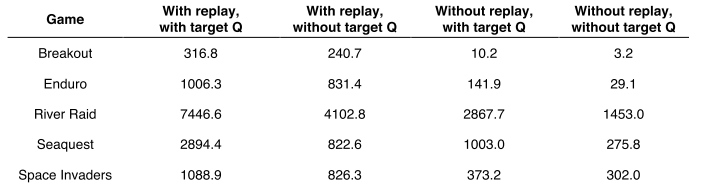
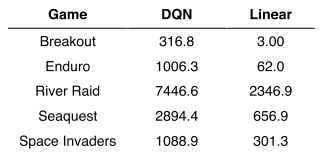
消融实验:DQN 智能体的各个核心组件—经验回放、独立目标Q网络和深度卷积网络架构--的重要性,禁用它们并证明了对性能的不利影响
Double-DQN:将动作选择和价值估计分开,避免价值过高估计
Dueling-DQN:将Q值分解为状态价值和优势函数,得到更多有用信息
Prioritized Replay Buffer:将经验池中的经验按照优先级进行采样
Multi-Step Learning:使得目标价值估计更为准确
Distributional DQN(Categorical DQN):得到价值分布
NoisyNet:增强模型的探索能力

















 8834
8834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









