







转的,如果有问题,及时联系我删除。
大雨临城,大数据给你最温暖的怀抱
烦躁的雨天
北京持续多日的强降水终于结束,打开uber看到界面上的小船又重新回归熟悉的汽车,真是让人大松一口气。
大雨下北京的优步打船
要说暴雨这几天无论对于是坐公共交通系统上下班,还是打车或者开车上班上学的大家最担心的是什么,那肯定就是交通问题了。
凡雨天必堵,我们路上耗费的时间常常比平时多出一倍两倍甚至更多,这种路况着实让大家心情烦躁。
可是天要下雨,这只能预测不能阻止,面对雨天或者是极端天气,我们既然无法避免那就只能积极应对。
那么,如何预测交通状况,进而应对交通拥堵,合理规划出行时间与路径呢?
怎么又提到大数据了,难道,大数据能挽救糟糕的路况吗?
很显然,大数据不能减少路上的车辆也不能凭空拓宽车道,但是大数据能够做的你肯定不陌生。
身为一个市民,当你走出家门,打开手机地图app想要选择一条较为通畅的路段时,最想知道的莫过于从走出家门到抵达公司的路况,以及选择最快最便捷地抵达目的地。
现在大家已经离不开实时路况的帮助,那么在这么一张红绿交错的地图后面,普林科技利用大数据作了怎样的工作呢?
于是我们假设了一个这样的情景
普林的科学家们面对这样的情景又做了怎样的工作呢?
◆ ◆ ◆
建立历史交通数据库
◆ ◆ ◆
预测当前时刻未来4个15min车速的情况
◆ ◆ ◆
预测未来某天24h的车速情况
下面我们来一条条看:
建立历史交通数据库
这块内容分为两部分,分别是提取道路信息,和提取车辆信息。
道路信息的提取:首先,从GIS数据库中导出北京市路网数据,这些数据包括道路的起点终点,中轴线经纬度,道路等级,车道数目等等。
根据这个信息,以中轴线为中心,按照车道数向两边延拓,得到每条路的坐标范围;然后将北京市五环30km*30km的范围,用1m*1m的小方格进行离散化,并与道路坐标相对应,对网格进行标记。
接下来是车辆信息的提取:我们的数据来源是北京市6万辆出租车每天的GPS数据,出租车每50s生成一条GPS信息,包括经纬度,车上是否载客等。
首先我们由GPS信息得到车辆的坐标,然后将坐标与之前的道路网格映射,确定车辆所属道路;再根据交通部门的经验和数据特征,以红绿灯、桥梁等对道路进行分段;最后进行速度的计算,时间间隔是15min。
如图是我们提取的一块区域的速度状况。
接下来是速度预测部分,主要从历史速度数据入手。
影响交通状况的因素很多,比如天气状况,车辆数量,交通事故等,但最终都表现在速度,速度包涵的信息量时足够的。
速度预测我们采用的是非参数回归预测法,其核心思想,简单说就是历史数据中最相似的情况,从而进行预测。
熟悉机器学习的话,会发现这种方法与k近邻,也就是KNN方法有些类似,KNN算法的思想是k个特征最近邻的样本大多数属于一个类别,这里非参数的思想是,最近邻的车速曲线,未来时刻的变化也可能相似。
非参数回归法的特点是精度高和可移植性强,只依靠数据驱动,不对数据进行任何假设,例如车辆分部等,只关注历史数据中输入对输出的影响,从而进行预测。
这种方法分为四个组成部分:
状态向量的选取
相似度的度量准则
相似曲线数量选择
预测方法,下面我会结合我们的具体做法,介绍这四个组成部分。
方法一
第一种方法,状态向量的选取就是需要拿去进行相似度匹配的特征向量。
由于考虑到车速变化存在大的变化趋势,以及小波的震荡噪声,便想到了小波分析出色的分解能力,于是想把它们结合在一起。
我们选择当前时刻的速度,以及前三个时刻的速度,进行小波分解,得到低频CA和高频CD部分。
如图所示,低频部分主要包含着速度变化的趋势,高频部分包含的是不规则的波动。这里我们只用低频的CA作为状态向量。
得到这两部分后,我们需要有一个指标来衡量状态向量与历史数据的相似度,这里采用了扩展欧式距离法。
一般的欧式距离是进行相应时刻的匹配,如图中蓝色距离,即今天8点的车速与历史8点的车速求距离。
但是,考虑到现实生活中可能存在这样一种情况,即速度曲线可能存在“提前”或者“滞后”的错位相似。
所谓错位的相似就是两条曲线可能形状非常相似,但是时间轴上并不是对齐的。具体可以看这幅图,一般欧式距离求得时间轴对齐的蓝色部分的距离,而从图中可以看出,黑色距离连接的点形态更相似,黄色的点是更早一个时刻的点,这就是相似的“提前”。
于是我们在匹配时,向前和向后扩展了两个点,进行距离计算。如图中黑色和红色的距离。
这样的话,与K条曲线一次匹配得到3N个距离,将这3N个距离排序即得相似排序,这样保证了保证了相似曲线的精确性以及较大的权重,因为同一条曲线的3个距离可能都很像,那么就能这条曲线会被取三次,对整条曲线来说,被赋予更多的权重,从而实现一定程度的排除噪声,增强鲁棒性。
相似度的度量准则则使用了扩展欧式距离。
相似曲线数量选择:取CA的扩展欧式距离作为相似度指标,寻找最相似的K条CA,这里令K=10。
预测方法则是,取相似的低频CA t+1时刻的小波系数进行带权重的赋值,权重即是距离倒数与距离总和的比值,即PPT中的bi,从而得到预测值。
我们看看这种方法的预测效果,这里以北京四环为例,将四环按照立交桥分为24段,速度时间间隔为15min,以三个月的历史交通数据作为检索库,预测2013年7月连续17天,预测时间间隔为15min,可以看到,系统平均误差为11.56%,计算速度每条路每天96个点耗时10s。预测效果不错。
预测结果:系统平均误差11.56%,计算速度每段路10s/天(96个点)
但同时,考虑到我们需要对北京市五环内的主路路网都进行预测,要实现实时预测,计算量很大,所以我们希望找出一种更简单,更快,精度更高的方法。
于是我们尝试了方法二和方法三。
方法二和三

这时取了当前时刻和前3个时刻的速度直接做状态向量,采用了一种新的相似度度量准则,动态时间弯曲距离,又称DTW,也是考虑到速度“提前”和“滞后”的错位匹配,这是基于动态规划思想的方法,通过构造邻接矩阵,以最短路径之和作为距离。从图中可以直观了解到DTW距离的特点。

相似曲线取了最相似的10条速度曲线,取他们t+1时刻的速度进行带权重的赋值,得到预测的速度。
我们看看这种方法的预测效果,这里以北京四环为例,将四环按照立交桥分为24段,速度时间间隔为15min,以三个月的历史交通数据作为检索库,预测2013年7月连续17天,预测时间间隔为15min。
预测结果:
扩展欧氏距离:系统平均误差—9.57% ;计算速度—每段路0.2s/天
DTW距离:系统平均误差—9.60%;计算速度—每段路2s/天
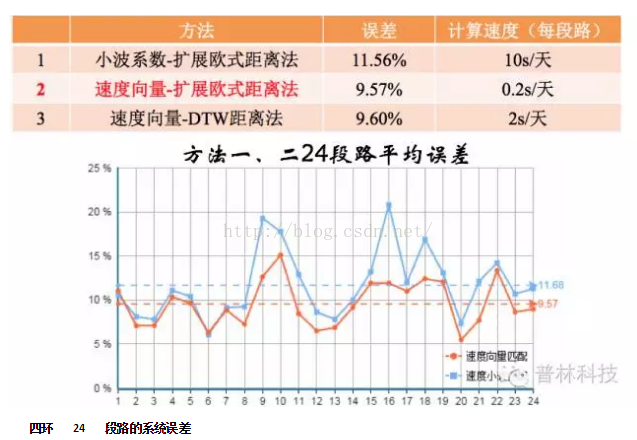
可见,三种方法进行对比,发现速度作为状态向量,扩展欧式距离进行匹配,带权重赋值的方法预测效果最好,精度高且计算速度快,能够适应北京市路网预测的需求。
同理,我们可以用同样的方法对30min,45min,60min的车速进行预测。
那么,未来24h呢?
> > > > 未来某天24h车速预测
第三部分我们进行未来某天24h的车速预测。主要方法还是非参数回归法。
这时候我们把天气作为主要因素加入到模型当中。
每半小时有一条天气数据,数据包括天气状态,降水量,温度,湿度等。
考虑到天气预报的准确性,我们这里的某天24小时,一般指的是3天内。
对于这些变量我们采用假设检验进行显著性的判断。
首先,按照天气状态分类,做车速均值与晴天相等的假设检验,结论是下雨下雾对天气的影响是较为显著的。
对于另一部分变量,按照某边界划分为两组,做车速相等的假设检验,发现温度和湿度对车速的影响较为显著。
这时我们还对降水数据进行了一个预处理,我们降水量只有全天的数据,但会标注出哪个时刻有降水,所以我们假设降水在降水时段是均匀分布的,所以
——每时段降水量=全天降水量/降水时段数量。
因为只有历史真实的天气数据,我们假设每天的分时天气预报是准确的,从而进行预测。
方法是也是非参数预测法,在这之前加入了一个判断步骤,将天气进行好天气,下雨,下雾三类判别。状态向量取t时刻的降水、湿度和湿度。
相似度度量准则采用欧式距离,相似曲线数量选择三条,取t时刻的速度进行带权重的预测算法。
预测结果,同样以北京四环为例,三个月的历史交通数据作为匹配库,预测7月连续一周的车速,预测时间间隔为30min,系统误差为12.7%。
四环24段路平均误差
通过以上几个方向的努力,我们成功实现了道路未来道路未来4个15min车速预测,误差仅为9.57% ;而道路未来某天24h车速预测,误差为12.7%。
同时还对出行方案进行三种路径规划(念叨了这么久,这里就省略啦):
一是路程最短路径,
二是道路最优路径,
三是时间最短路径。
三种路径的规划全方面满足不同的出行需求,无论是求快还是求稳,都能满足你的要求。
雨天再也不怕赴约迟到啦!
北京作为一个特大城市,交通问题一直是困扰着大家的问题,一旦堵车可能行车时间动辄加倍,大数据在解决大家出行问题时,不仅仅帮助大家有效规划出最便捷最优化的路线更能缓解交通拥堵,引导车辆躲避拥堵避免堵上加堵。
大数据下的出行方案,实时反馈交通状况预测,精准预测未来路况,更关注每一个人的出行,缓解交通压力。














 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









