








然后,我们接着计算词条的先验概率部分
#计算词条先验概率
print u"\n计算词条概率"
ybgl={}
for my_word in wordybcount.keys():
ybgl.setdefault(my_word,np.repeat(0.,len(yb_txt)).tolist())
for ybii in xrange(0,len(yb_txt)):
ybgl[my_word][ybii]=wordybcount[my_word][ybii]/float(lbcount[ybii])
print ".",
本博客所有内容是原创,如果转载请注明来源
http://blog.csdn.net/myhaspl/
计算先验概率后,我们来看公式。

我们已经得到了
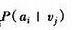
余下的事情就是读入待分类的样本,分词后,代入
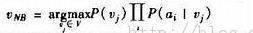
计算出其所属类别概率中的最大值,输出目标值即所属概率最大的类















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









