







Objective
after completing this lesson, you should be able to do the following:
1.List the advantages of distributing different Oracle file types
2.Diagnose tablespace usage problesm
3.List reasons for partitioning data in tablespaces
4.Describe how checkpoints work
5.Monitor and tune checkpoints
6.Monitor and tune redo logs
Oracle I/O Architecture

Oracle Processes and Files

Performance Guidelines
Basic performance rules are as follows:
1.Keep disk I/O to a minimum
2.Spread your disk load across disk devices and controllers
3.Use temporary tablespaces where appropriate.
Distributing Files
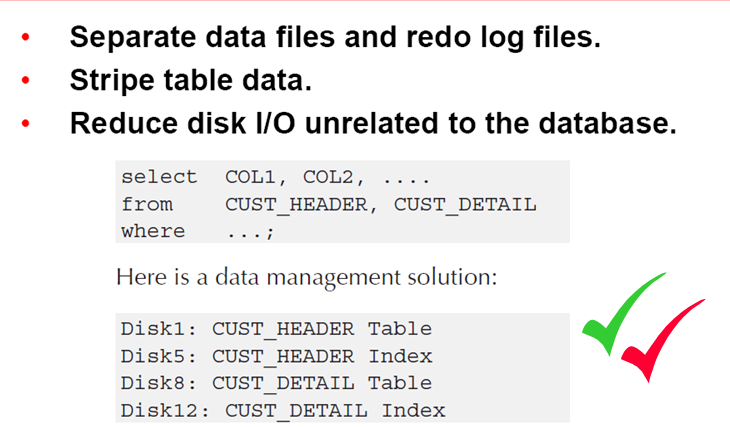
redo log files: 要选速度最快的磁盘
Tablespace Usage
1.Reserve the system tablespace for data dictionary objects
2.Create Locally managed tablespaces to avoid space management issues
3.Split tables and indexes into separate tablespaces
4.Create rollback segments in their own tablespaces
5.Store very large objects in their own tablespace.
6.Create one or more temporary tablespaces
Locally Managed SYS TS

Tools for I/O Statistics

Using v$filestat View
The view displays the number of physical reads and writes done and the total number of single-block and multiblock I/Os done at file level.
SQL> col name format a51;
SQL> select f.phyrds, f.phywrts, d.name from v$datafile d, v$filestat f where d.file#=f.file# order by d.name;
PHYRDS PHYWRTS NAME
---------- ---------- ---------------------------------------------------
10 2 /u01/app/oracle/oradata/king/backup/app02_01.dbf
14 2 /u01/app/oracle/oradata/king/backup/app1_01.dbf
9 2 /u01/app/oracle/oradata/king/backup/app3_01.dbf
0 1088 /u01/app/oracle/oradata/king/backup/perfstat_01.dbf
1389 2140 /u01/app/oracle/oradata/king/backup/sysaux01.dbf
6240 853 /u01/app/oracle/oradata/king/backup/system01.dbf
45 1189 /u01/app/oracle/oradata/king/backup/undotbs01.dbf
9 2 /u01/app/oracle/oradata/king/backup/users01.dbf
8 rows selected.I/O Statistics
SQL>col tablespace format a10;
SQL> col FILE_NAME format a40;
SQL> select d.tablespace_name tablespace, d.file_name, f.phyrds,f.phywrts from v$filestat f, dba_data_files d where f.file#=d.file_id;
TABLESPACE FILE_NAME PHYRDS PHYWRTS
---------- ---------------------------------------- ---------- ----------
SYSTEM /u01/app/oracle/oradata/king/backup/syst 6240 862
em01.dbf
UNDOTBS1 /u01/app/oracle/oradata/king/backup/undo 45 1208
tbs01.dbf
SYSAUX /u01/app/oracle/oradata/king/backup/sysa 1389 2154
ux01.dbf
USERS /u01/app/oracle/oradata/king/backup/user 9 2
s01.dbf
File Striping
1.Operating system striping:
a.Use operating system striping software of a redundant array of indexpensive disks(RAID)
b.Determine the right stripe size
2.Manual striping :Use the Create TABLE or ALTER TABLE command with the ALLOCATE clause.
Tuning Full Table Scan Operatings
1.Investigate the need for full table scans.
2.Configure the DB_FILE_MULTIBLOCK_READ_COUNT initialization parameter to:
a.Determine the number of database blocks the server reads at once.
b.Influence the execution plan of the cost-based optimizer
3.Monitor long-running full table scans with v$session_longops view
DB_FILE_MULTIBLOCK_READ_COUNT:进行全表扫描,一次读的数据库块数 ,受底层操作系统限制
Table Scan Statistics
SQL> select name , value from v$sysstat where name like '%table scan%';
NAME VALUE
--------------------------------------------------- ----------
table scans (short tables) 20580
table scans (long tables) 6
table scans (rowid ranges) 0
table scans (cache partitions) 0
table scans (direct read) 0
table scan rows gotten 6867533
table scan blocks gotten 335358
7 rows selected.
table scans (long tables) 如果这个值对应的 value比较大,则需要调整
Monitoring FTS Operations
1.Determine the progress of long operations using:
SQL> select sid, serial#,opname, to_char(start_time,'hh24:MI:SS') as "START" , (sofar/totalwork)*100 AS PERCENT_COMPLETE from v$session_longops;
2.Use SET_SESSION_LONGOPS to populate v$session_longops

Checkpoints
1.Incremental checkpoints
a.CKPT updates the control file.
b.During a log switch CKPT updates the control file and the data file headers
2.Full checkpoints
a.CKPT updates the control file and the data file headers
b.DBWn writes out all buffers on the checkpoint queue.
Full Checkpoints
Two categories of full checkpoints
1.Complete
2.Tablespace
SQL> show parameter log_checkpoints_to_alert;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_checkpoints_to_alert boolean FALSE这个参数 为true时,检查点信息记录到alert里边
Regulating Checkpoint Queue
Requlate the checkpoint queue with the following initailization parameters:
1.FAST_START_IO_TARGET
2.LOG_CHECKPOINT_INTERVAL //过时
3.LOG_CHECKPOINT_TIMEOUT //过时
4.FAST_START_MTTR_TARGET //恢复到正常工作的时间
Fast Start Checkpointing
use v$instance_recovery to obtain the following information :
1.RECOVERY_ESTIMATED_IOS
2.LOG_FILE_SIZE_REDO_BLKS
3.LOG_CHKPT_TIMEOUT_REDO_BLKS
4.LOG_CHKPT_INTERVAL_REDO_BLKS
5.TARGET_MTTR
6.ESTIMATED_MTTR
Rodo Groups and Members
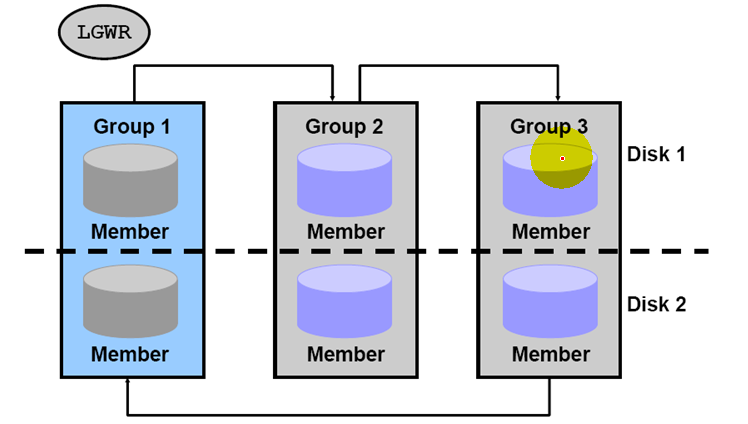
1.Size redo log files to minimize contention.
2.Provide enough groups to prevent waiting.
3.Store redo log files on separate, fast devices
4.Monitor the redo log file configuration with:
a.V$LOGFILE
b.V$LOG
c.V$LOG_HISTORY
Checkpoint not complete current
log# 3 seq# 1465 mem# 0 : /home/ora10g/oradata/ora10g/redo03.log
出现这个就是DBwn还木有把数据写入到磁盘,改组redo log不能被重用
Archiving Performance
1.Allow the LGWR process to write to disk different form one the ARCn process is reading
2.Share the archiving work during a temporary increase in workload:
ALTER SYSTEM ARCHIVE LOG ALL TO <log_archive_dest>
3.Increase the number of archive processes
4.Change archiving speed:
a.LOG_ARCHIVE_MAX_PROCESSES
b.LOG_ARCHIVE_DEST_n
Diagnostic Tools
v$archive_dest
v$archived_log
v$archive_processes
LOG_ARCHIVE_DEST_STATE_n















 3891
3891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









