







 本文介绍了使用Python实现基于LeNet的单隐层多层感知机(MLP)模型,详细讲解了模型公式、激活函数、权值初始化以及代价函数。通过添加规则化项防止过拟合,最终应用于MNIST手写数字识别任务。
本文介绍了使用Python实现基于LeNet的单隐层多层感知机(MLP)模型,详细讲解了模型公式、激活函数、权值初始化以及代价函数。通过添加规则化项防止过拟合,最终应用于MNIST手写数字识别任务。
本文主要参考于:Multilayer Perceptron
python源代码(github下载 CSDN免费下载)
本文主要介绍含有单隐层的MLP的建模及实现。建议在阅读本博文之前,先看一下LR的实现。因为LR是简化版的MLP。LR不含有单隐层,则其输入层直接连接到输出层。从何处可以看出LR是输入层直接连接输出层?借用上一博文的公式: P(Y=i|x,W,b)=softmaxi(Wx+b) 。其中, x 是输入层,
那么MLP的模型公式和LR又有什么不同呢?下面来看一下MLP的模型建立。
一、模型
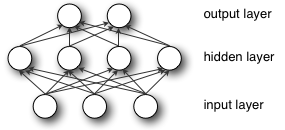
从MLP的结构图中可以看出输入层与隐藏层全连接,然后,隐藏层与输出层全连接。那么整体的函数映射就是 f:RD→RL ,其中 D 是输入向量
f(x)=G(W(2)(S(W(1)x+b(1)))+b(2))
其中, b(1),b(2) 分别是三层之间(输入层与隐层、隐层与输出层之间)的偏置向量; W(1),W(2) 分别是三层之间的权值矩阵;而 S,G 是分别是三层之间的激活函数。
对于连接单隐层的的表达式 h(x)=Φ(x)=S(W(1)x+b(1)) ,其激活函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









