







本文测试的Spark版本是1.3.1
在使用Spark的机器学习算法库之前,需要先了解Mllib中几个基础的概念和专门用于机器学习的数据类型
特征向量Vector:
Vector的概念是和数学中的向量是一样的,通俗的看其实就是一个装着Double数据的数组
Vector分为两种,分别是密集型和稀疏型
创建方式如下:
val array:Array[Double] = ...
val vector = Vector.dense(array)//创建密集向量
val vector = Vector.sparse(array)// 创建稀疏向量注意:Scala默认引用的是scala.collection.immutable.Vector,为了使用Mllib中的Vector,必须显示引入org.apache.spark.mllib.linalg.Vector
密集向量和稀疏向量的却别:
密集向量的值就是一个普通的Double数组
而稀疏向量由两个并列的 数组indices和values组成
例如:向量(1.0,0.0,3.0)用密集格式表示为[1.0,0.0,3.0],用稀疏格式表示为(3,[0,2],[1.0,3.0])
第一个3表示向量的长度,[0,2]就是indices数组,[1.0,3.0]是values数组
表示向量0的位置的值是1.0,而2的位置的值是3.0
含类标签的点 LabeledPoint:
一个含类标签的点由一个类标签(Double型)和一个向量(密集或者稀疏)组成
在Mllib中,监督学习算法会用到LabeledPoint,比如:回归和分类等
LabeledPoint通过case class LabeledPoint来创建
val pos = LabeledPoint(1.0,Vector.dense(1.0,0.0,3.0))
val neg = LabeledPoint(1.0,Vector.sparse(3,Array(0,2),Array(1.0,3.0)))矩阵 Matrix:
矩阵分为本地矩阵和分布式矩阵两种
本地矩阵创建方式如下:
val dm:Matrix = Matrices.dense(3,2,Array(1.0,3.0,5.0,2.0,4.0,6.0))//创建一个3*2的密集矩阵可以看到,其存储的方式是一个矩阵大小(3,2)和一维数组[1.0,3.0,5.0,2.0,4.0,6.0]
分布式矩阵:
一个分布式的矩阵由一个Long型的行列索引和Double型的数据组成,分布式存储在一个或多个RDD中
最基本的RowMatrix:面向行的分布式矩阵,其行索引是没有具体含义的,其通过一个RDD来代表所有的行,每个行都是一个本地向量
RowMatrix创建方式:
val rows:RDD[Vector] = ...//RowMatrix可以从一个RDD[Vector]类型创建出来
val mat:RowMatrix = new RowMatrix(rows)
//获得RowMatrix的size
val r = mat.numRows()
val c = mat.numCols()行索引矩阵IndexedRowMatrix:和RowMatrix类似,但是其行索引是有含义的,可以通过其来检索信息
创建方式:
val rows:RDD[IndexedRow] = ...//IndexedRowMatrix可以从一个RDD[IndexedRow]中创建,IndexedRow其实就是一个(Long,Vector)的封装类,就是比创建RowMatrix时多需要了一个Long类型的行索引
val mat:IndexedRowMatrix = new IndexedRowMatrix(rows)
//获得IndexedRowMatrix 的size
val r = mat.numRows()
val c = mat.numCols()
//如果剔除掉IndexedRowMatrix 的行索引,就会变为一个RowMatrix
val rowMatrix = mat.toRowMatrix()三元组矩阵 CoordinateMatrix:其实体集合是一个RDD,每个实体是一个(i:Long,j:Long,value:Double)三元组,其中i表示行索引,j为列索引,value为对应的数据。一般只有当矩阵很大,而且很稀疏时才使用
CoordinateMatrix创建方式如下:
val enties:RDD[MatrixEntry] = ...//CoordinateMatrix可以从一个RDD[MatrixEntry]中创建,MatrixEntry其实就是一个(Long,Long,Double)的封装类
val mat:CoordinateMatrix = new CoordinateMatrix(enties)
//获得mat:CoordinateMatrix 的size
val r = mat.numRows()
val c = mat.numCols()
//将其转换成IndexedRowMatrix,但是这个IndexedRowMatrix的行是稀疏的
val indexedRowMatrix = mat.toIndexedRowMatrix()其实从RowMatrix,IndexedRowMatrix到CoordinateMatrix,是一步一步的升级的,三者都是有一个RDD来表示所有的实体,只是其中的实体不同而已
RowMatrix的每个实体是本地向量
IndexedRowMatrix的每个实体都是Long类型的行索引加+本地向量
CoordinateMatrix的每个实体是两个Long类型的行列索引+本地向量
三者的创建方式也都是类似的
RowMatrix通过一个RDD[Vector]来创建,而一个Vector其实就是表示一个Double型的数组而已,在将其转换成RDD即可
IndexedRowMatrix通过一个RDD[IndexedRow]来创建,IndexedRow就是封装好了的(Long,Vector)类型,相信能够通过Vector来创建RowMatrix的,使用IndexedRow创建IndexedRowMatrix也不是什么难事
CoordinateMatrix通过一个RDD[MatrixEntry]来创建,MatrixEntry就更简单了,直接就是一个(Long,Long,Double)的封装类,连Vector都不需要了
三者的概念的联系就是如此而已,不要被他们的名字吓到了
以上是Mllib中几个基本概念和数据类型介绍,更多相关的操作如:对矩阵的汇总统计和相关性计算,分层抽样,假设检验,随机数据生成等请参考官方文档(其实就是提供了一个类似静态的工具类,调用其方法即可)
下面例举Mllib中线性回归,KMeans和协同过滤三种算法的来演示
线性回归:
在本例中使用到的Mllib专用数据类型为LabelPoint
测试数据如下:
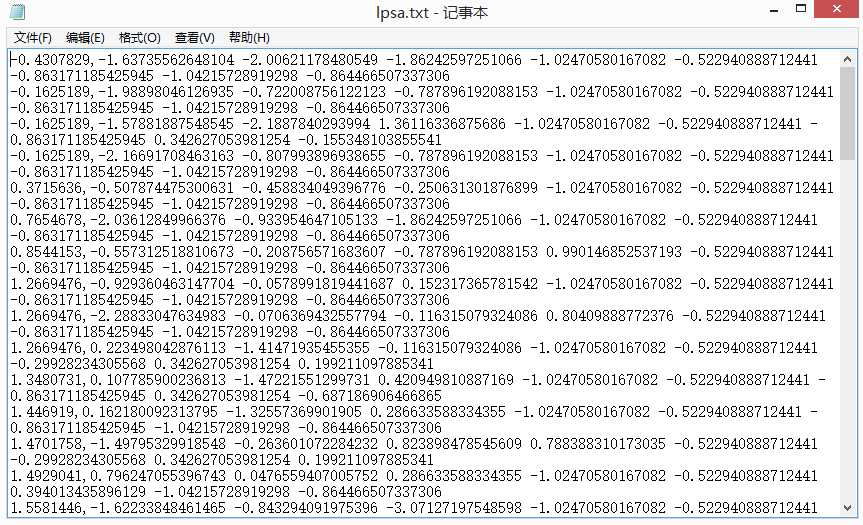
object LinearRegression {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage : <master> <hdfs path>")
System.exit(1)
}
val conf = new SparkConf().setMaster(args(0)).setAppName("LinearRegression")
val sc = new SparkContext(conf)
//读取hdfs上的测试数据,并将其转化为LabeledPoint类型
val data = sc.textFile(args(1)).map { lines =>
val parts = lines.split(",")
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(" ").map(_.toDouble)))
}
//设置算法的迭代次数
val numIterations = 100
//使用LinearRegressionWithSGD类的train,将数据(LabeledPoint)传进去进行模型训练,得到一个评估模型
val model = LinearRegressionWithSGD.train(data, numIterations)
//使用模型的predict方法来进行预测,将LabeledPoint的features(也就是value部分)当做预测数据,并将预测结果和LabeledPoint的label(类标签)部分,组成一个元组返回
val result = data.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
//输出元组内容
result.foreach(println)
//计算模型评分星级MSE
val MSE = result.map { case (v, p) => math.pow((v - p), 2) }.mean()
println("train result MSE:" + MSE)
}KMeans算法:
KMeans算法中用到的Mllib专用数据类型有:Vector
object KMeans {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage : <master> <hdfs path> <file save path>")
System.exit(1)
}
val conf = new SparkConf().setMaster(args(0)).setAppName("KMeans")
val sc = new SparkContext(conf)
//读取数据,并转化成密集向量
val data = sc.textFile(args(1)).map { lines =>
Vectors.dense(lines.split(" ").map(_.toDouble))
}
//实例化KMeans类,该类用来做算法的一些设置和运行算法
val km = new KMeans()
//设置聚类中心点个数为2,最大迭代次数为20,run方法开始运算,传入测试数据集
val model = km.setK(2).setMaxIterations(20).run(data)
//输出得到的模型的聚类中心
println("cluster num :" + model.k)
for (i <- model.clusterCenters) {
println(i.toString)
}
println("----------------------------------------")
//使用自定义的数据对模型进行测试,让其判断这些向量分别属于哪个聚类中心
println("Vector 0.2 0.2 0.2 is closing to : " + model.predict(Vectors.dense("0.2 0.2 0.2".split(" ").map(_.toDouble))))
println("Vector 0.25 0.25 0.25 is closing to : " + model.predict(Vectors.dense("0.25 0.25 0.25".split(" ").map(_.toDouble))))
println("Vector 8 8 8 is closing to : " + model.predict(Vectors.dense("8 8 8".split(" ").map(_.toDouble))))
println("----------------------------------------")
//将测试数据再次作为预测数据传入模型中进行预测
val result0 = model.predict(data).collect().foreach(println)
println("----------------------------------------")
//数据得到的结果,保存在hdfs中(直接打印也可以)
val result = data.map { lines =>
val res = model.predict(lines)
lines + " clustingCenter: " + res
}.saveAsTextFile(args(2))
}
}协同过滤:
在此算法中有一个Rating数据类型是专门用来运算协同过滤的
Rating的定义如下:Rating(user:Int,product:Int,rating:Double)
user:用户id
product:产品id(可以是电影,商品等各种各样)
rating:该用户对该产品的评分
测试数据如下:
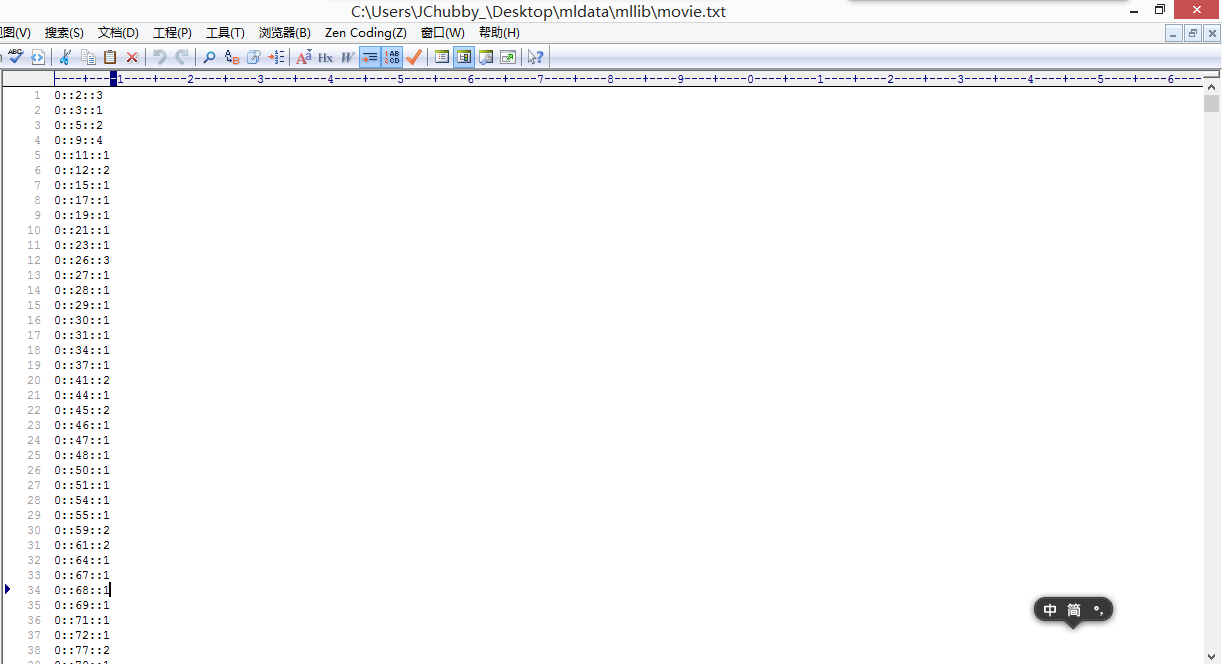
object CF {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage : <master> <hdfs path>")
System.exit(1)
}
val conf = new SparkConf().setMaster(args(0)).setAppName("Collaborative Filtering")
val sc = new SparkContext(conf)
//读取文件,并转化为Rating类型
val ratings = sc.textFile(args(1)).map(_.split("::") match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble) })
//设置隐形因子个数,迭代次数
val rank = 10
val numIterations = 5
//调用ALS类的train方法,传入要训练的数据等进行模型训练
val model = ALS.train(ratings, rank, numIterations, 0.01)
//将训练数据转换成(user,item)格式,以作为测试模型预测的数据(协同过滤的模型预测时是传入(user,item),然后预测出每个user-item对应的评分)
val usersProducts = ratings.map { case Rating(user, item, rate) => (user, item) }
//调用model的predict,传入(user, item)格式的测试数据进行预测,得到的结果为(user,item,rating)
val prediction = model.predict(usersProducts).map { case Rating(user, item, rate) => ((user, item), rate) }
//将得到的预测评分结果和原先的数据进行join操作,以便观察预测的准确度
val result = ratings.map { case Rating(user, item, rate) => ((user, item), rate) }.join(prediction)
result.collect().foreach(println)
}
}其实通过官方文档的example照葫芦画瓢,调用Mllib中各个算法就可以很方便快速的进行机器学习,但是这仅仅是会调用算法库而已,机器学习中的各种算法原理还是需要深入了解和掌握的。不然使用Mllib可以如此简单的调用机器学习的算法,那么和别人相比,怎么能够突出你的优势所在呢?















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









