







 本文探讨了视觉注意力模型在计算机视觉领域的应用,特别是在图片主题生成上的作用。通过引入注意力机制,模型能够更好地捕捉图像的关键信息,避免信息丢失。文章详细介绍了基于RNN的视觉注意力模型、Encoder-Decoder结构以及硬注意力和软注意力两种不同的实现方式,展示了如何动态地从图像中提取信息以生成准确的图片描述。
本文探讨了视觉注意力模型在计算机视觉领域的应用,特别是在图片主题生成上的作用。通过引入注意力机制,模型能够更好地捕捉图像的关键信息,避免信息丢失。文章详细介绍了基于RNN的视觉注意力模型、Encoder-Decoder结构以及硬注意力和软注意力两种不同的实现方式,展示了如何动态地从图像中提取信息以生成准确的图片描述。
引言
Attention model 在序列end to end问题上广泛应用,结合RNN、LSTM、GRU等常用递归神经网络可以取得很好的效果;在计算机视觉领域也有非常广泛的利用,因为序列因素的存在,所以通常在图文转换或者视频描述等应用中出现。
Visual attention model的意义
- 在引入Attention(注意力)之前,图像识别或语言翻译都是直接把完整的图像或语句直接塞到一个输入,然后给出输出。
- 而且图像还经常缩放成固定大小,引起信息丢失。
- 而人在看东西的时候,目光沿感兴趣的地方移动,甚至仔细盯着部分细节看,然后再得到结论。
- Attention就是在网络中加入关注区域的移动、缩放、旋转机制,连续部分信息的序列化输入。
- 关注区域的移动、缩放、旋转采用强化学习来实现。
Recurrent model of visual attention
Recurrent Models of Visual Attention
基于Attention的图片主题生成
参考Show, Attend and Tell: Neural Image Caption Generation with Visual Attention(2015)

模型
之前Encoder过程中的输入是一个个词向量,而在visual attention model中便是通过CNN抽取的各个图像特征之后展平的一维特征向量,如下图所示:
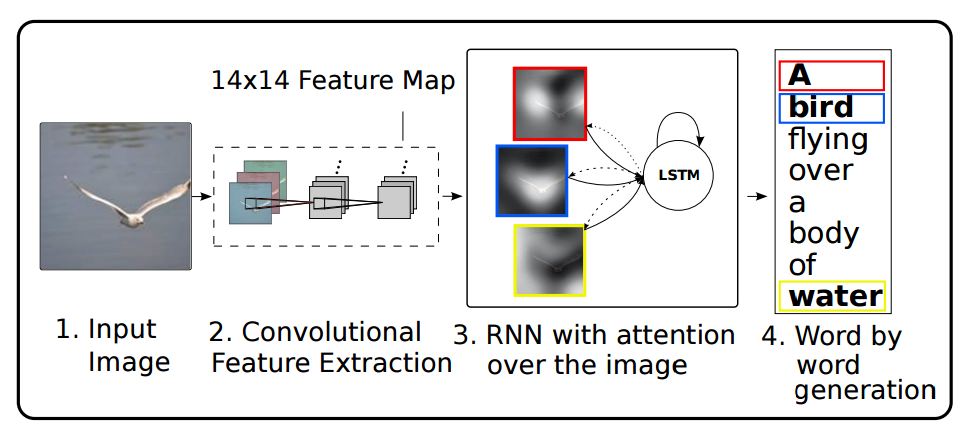
Encoder
特征图均匀切割成若干个区域,表示为
a={
a1,a2,...,aL},ai∈RD
L表示特征数,D表示特征的维数,在论文中为 D=14×14=196 ,每一个特征向量代表了图像一个局部窗口的特征。这里的特征提取用的是一个低层的卷积网络,而不是一个完整的CNN网络,因为一个完整的网络最终把一个图片融合成一个很高维的特征向量。而用低层的卷积网络就可以选择集中于某些局部区域。
输出的主题 y 可以编码为
其中K是字典的单词个数,C输出的句子长度。 yi 用one-hot编码,形式为 (0,0,...,0,1,0,...0,0) ,即只有一处为1,其他都为0。
Decoder
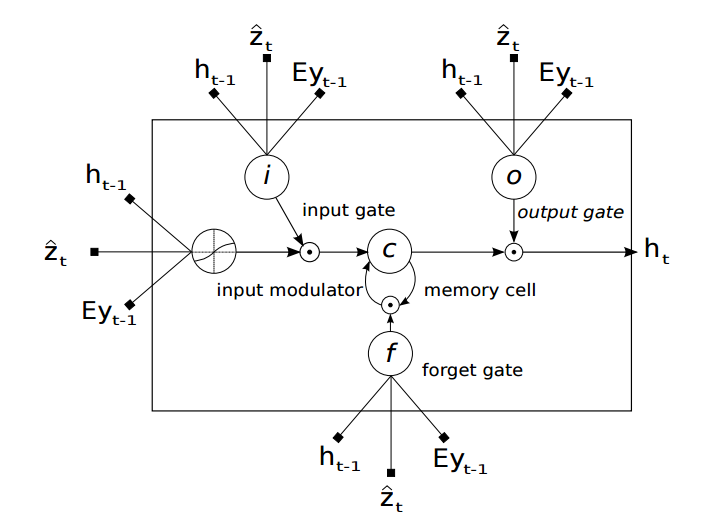
论文中利用LSTM来进行解码,LSTM的结构如下图所示
计算公式为
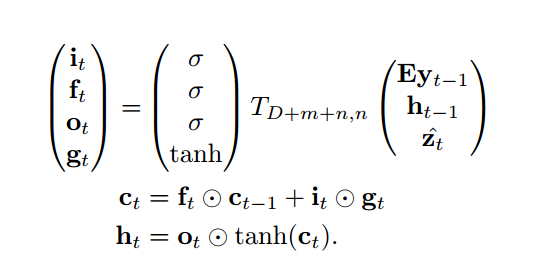
其中 σ 是sigmoid激活函数, ⨀ 表示同位置的元素相乘。
it,ft,ot 分别表示输入门、遗忘门、输出门, gt 是对输入的转化, ct 是cell状态, ht 是隐藏状态。
E∈Rm×K 是embedding层训练出来的参数矩阵。
z^t 是上下文向量,是t时刻图片部分信息的动态表示。
z^t=ϕ({
ai},{
αi})
ϕ 函数根据hard模式和soft模式有不一样的定义,后面会有具体的介绍。另外还有
eti=fatt(ai,ht−1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









