







Python爬虫
主要使用的是requests库和BeautifulSoup4库分别实现对内容的爬取和解析,展示的部分就显得很简单,我直接写入到文件中了。
介绍
为了能让这部分代码能够重构,因此用面向对象写了一个Python的爬虫类,比较简单,还可以在爬虫内中增加一下对robots.txt的爬取,规避风险。
另外爬虫跑起来速度比较慢,1-3s才能爬取一个页面,对于中、大型的项目需求肯定不能这么使用了。
先把爬虫类的代码放上来。
import requests
from bs4 import BeautifulSoup
import traceback
class MySpider(BeautifulSoup):
def __init__(self):
pass
def getHtmlText(self,url,keyword = ''):
'''
This function use GET to gain html
:param url The url that you want to get
:param keyword This will auto complete the url with ? =
'''
try:
r = requests.request('GET',url,params = keyword)
r.raise_for_status() #触发异常
r.encoding = r.apparent_encoding # 调整编码
return r.text
except Exception as e:
print(traceback.format_exc()) # 输出异常
def getSoup(self,html):
return BeautifulSoup(html,'html.parser') #用python自带的html解析器
这个类的主要内容有用来获得string类型html文档的getHtmlText()函数,需要传入url。其次是一个beautiful解析器,输入一个待解析的html返回一个解析完成的soup。
糗事百科
接下来的任务就是使用这个爬虫类了,大概翻了一下糗事百科的首页,可以看到其结构如下图,包含段子的div标签的属性值和别的内容的属性值不同。
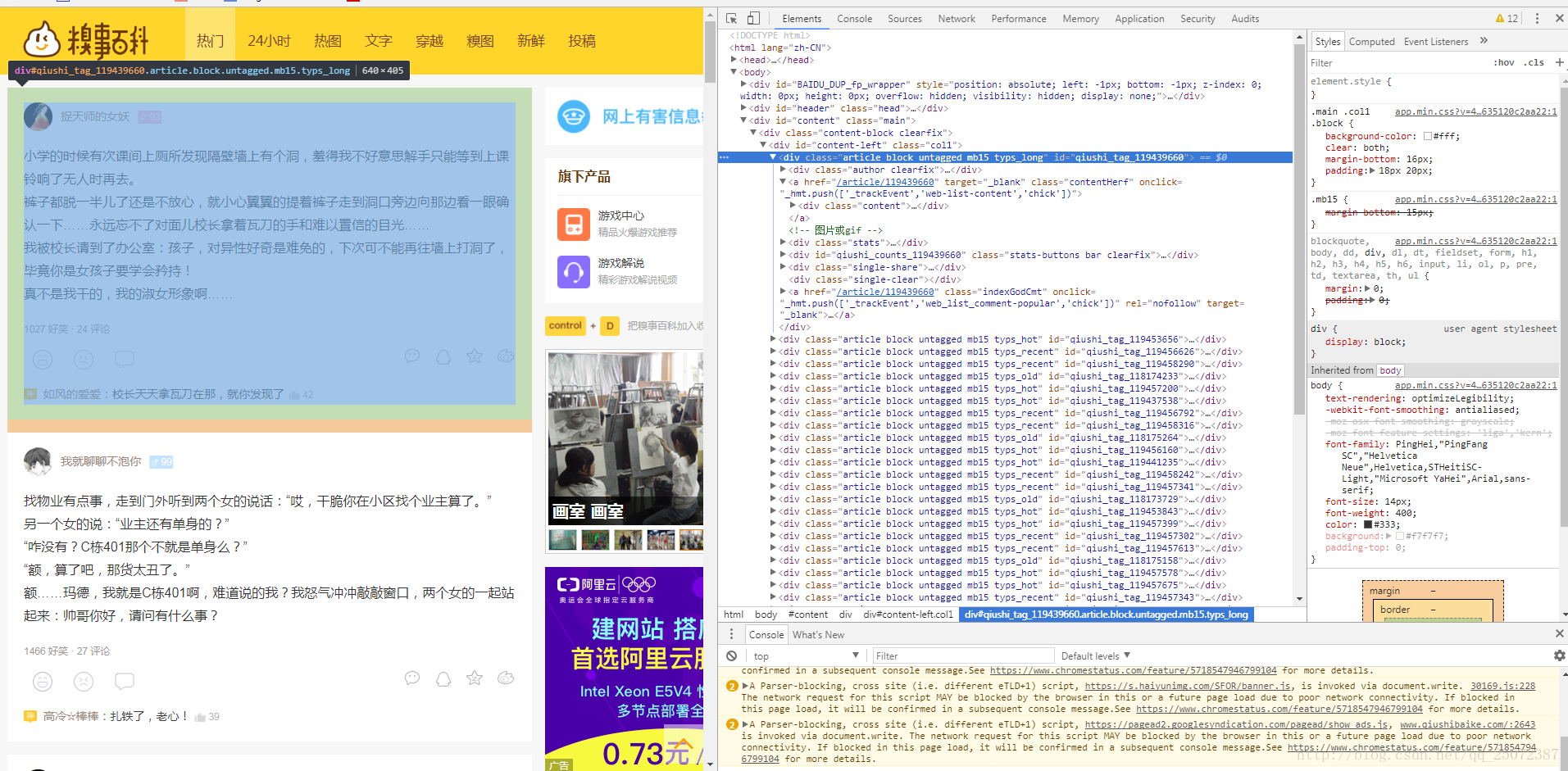
<!-第一个段子->
<div class="article block untagged mb15 typs_long" id="qiushi_tag_119439660">
<!-第二个段子->
<div class="article block untagged mb15 typs_hot" id="qiushi_tag_119453656">
<!-第三个段子->
<div class="article block untagged mb15 typs_recent" id="qiushi_tag_119456626">其中呢发现class是基本上相同的,除了里面的types后面接的词不一样,然后查看下网页源代码,搜索了一下”article block untagged mb15”,数目正好与段子数是一样的,那么就可以直接使用正则来匹配了。
下面贴下获取糗事百科的函数:
def getChowBai():
'This is used to gatherer the ChowBai'
MAXPAGE = 10 # 用于确认爬取的最大页数
base_url = 'http://www.qiushibaike.com/8hr/page/'
# page = 1
spider = MySpider()
errorCount = 0 # 用于统计错误信息,方便爬虫调试
# for i in range(1,MAXPAGE):
for page_number in range(1,MAXPAGE+1):
try:
soup = spider.getSoup(spider.getHtmlText(base_url+str(page_number)))
content_div = soup.body.find('div',attrs={'class':'col1','id':'content-left'}) # 找到包含内容的div,这里只搜索符合attrs的内容
# print(content_div)
article_list = content_div.find_all('div',class_=re.compile(r'^article block'),limit=24) # all in <div id="content-left" class="col1"> 只需要24个
except Exception as e:
with codecs.open('chowbai_error_info.txt', 'a+', 'utf-8') as f:
f.write(str(errorCount) + ':\t' + traceback.format_exc() + '\n')
errorCount += 1
# for i in range(10):
# print('----------------'+str(i)+'-----------------')
# print(article_list[i])
for i in range(len(article_list)):
try:
#print(len(article_list))
with codecs.open('get_chowbai.txt','a+','utf-8') as f:
f.write('---------------' + str(page_number)+'_'+str(i) + '---------------\n')
f.write(article_list[i].find('a',onclick="_hmt.push(['_trackEvent','web-list-content','chick'])").find('span').text+'\n')
f.write(article_list[i].find('div',class_ = 'thumb').img.attrs['src']+'\n')
except Exception as e:
with codecs.open('chowbai_error_info.txt', 'a+', 'utf-8') as f:
f.write(str(errorCount) + ':\t' + traceback.format_exc() + '\n')
errorCount += 1
看着比较复杂,但其实核心的部分只有一句话,得到article的列表,接下来你就可以随心所欲的操作了。
article_list = content_div.find_all('div',class_=re.compile(r'^article block'),limit=24) # all in <div id="content-left" class="col1"> #只需要24个改进方向
做研究可以往爬取的数据怎么去使用,去分析糗百上段子大多数是什么样的。另外还可以去做爬虫的优化,也可以试一试形成一个应用接口,在其它项目中一个一个的获取糗百内容。
全部代码
# coding=utf-8
import bs4
import requests
from bs4 import BeautifulSoup
from bs4.element import *
import re
import traceback
import codecs
class MySpider(BeautifulSoup):
def __init__(self):
pass
def getHtmlText(self,url,keyword = ''):
'''
This function use GET to gain html
:param url The url that you want to get
:param keyword This will auto complete the url with ? =
'''
try:
r = requests.request('GET',url,params = keyword)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(traceback.format_exc())
def getSoup(self,html):
return BeautifulSoup(html,'html.parser')
def getChowBai():
'This is used to gatherer the ChowBai'
MAXPAGE = 10 # 用于确认爬取的最大页数
base_url = 'http://www.qiushibaike.com/8hr/page/'
# page = 1
spider = MySpider()
errorCount = 0 # 用于统计错误信息,方便爬虫调试
# for i in range(1,MAXPAGE):
for page_number in range(1,MAXPAGE+1):
try:
soup = spider.getSoup(spider.getHtmlText(base_url+str(page_number)))
content_div = soup.body.find('div',attrs={'class':'col1','id':'content-left'}) # 找到包含内容的div,这里只搜索符合attrs的内容
# print(content_div)
article_list = content_div.find_all('div',class_=re.compile(r'^article block'),limit=24) # all in <div id="content-left" class="col1"> 只需要24个
except Exception as e:
with codecs.open('chowbai_error_info.txt', 'a+', 'utf-8') as f:
f.write(str(errorCount) + ':\t' + traceback.format_exc() + '\n')
errorCount += 1
# for i in range(10):
# print('----------------'+str(i)+'-----------------')
# print(article_list[i])
for i in range(len(article_list)):
try:
#print(len(article_list))
with codecs.open('get_chowbai.txt','a+','utf-8') as f:
f.write('---------------' + str(page_number)+'_'+str(i) + '---------------\n')
f.write(article_list[i].find('a',onclick="_hmt.push(['_trackEvent','web-list-content','chick'])").find('span').text+'\n')
f.write(article_list[i].find('div',class_ = 'thumb').img.attrs['src']+'\n')
except Exception as e:
with codecs.open('chowbai_error_info.txt', 'a+', 'utf-8') as f:
f.write(str(errorCount) + ':\t' + traceback.format_exc() + '\n')
errorCount += 1
def Test():
'测试用例'
html = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>MyTitle</title>
</head>
<body>
<div class="conten1">
<p>This is the first p</p>
</div>
<div class="conten2">
<h1>My article</h1>
<h2>Python is the best!</h2>
</div>
</body>
</html>
'''
spider = MySpider()
soup = spider.getSoup(html)
print(soup('div',class_='conten1'))
if __name__ == '__main__':
getChowBai()














 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









