







 本文深入探讨支持向量机(SVM),从优化目标出发,揭示其为何被称为大间距分类器。解释SVM如何通过最大化间隔来构建决策边界,以及核函数在构造非线性分类器中的作用。同时,介绍了参数C和σ2对模型的影响,并提供了SVM在实际应用中的选择和使用建议。
本文深入探讨支持向量机(SVM),从优化目标出发,揭示其为何被称为大间距分类器。解释SVM如何通过最大化间隔来构建决策边界,以及核函数在构造非线性分类器中的作用。同时,介绍了参数C和σ2对模型的影响,并提供了SVM在实际应用中的选择和使用建议。
一.支持向量机的引入
支持向量机(SVM)是一种极受欢迎的监督学习算法,为了引入支持向量机,我们首先从另一个角度看逻辑回归。
1.从单个样本代价考虑
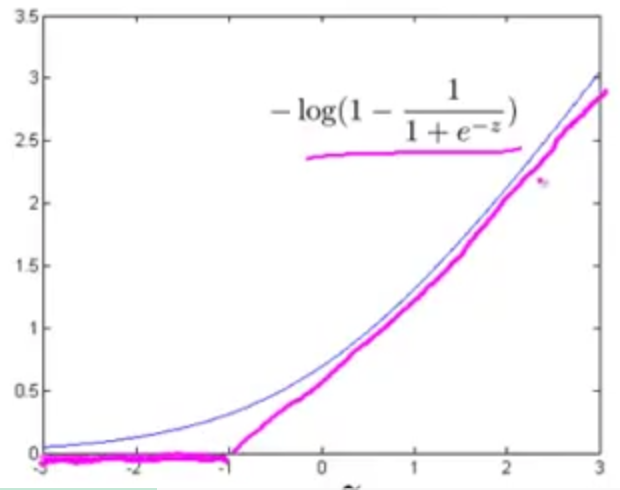
假设函数 hθ(x)=11+e−θTx 。由于S型函数有如下图的特性,
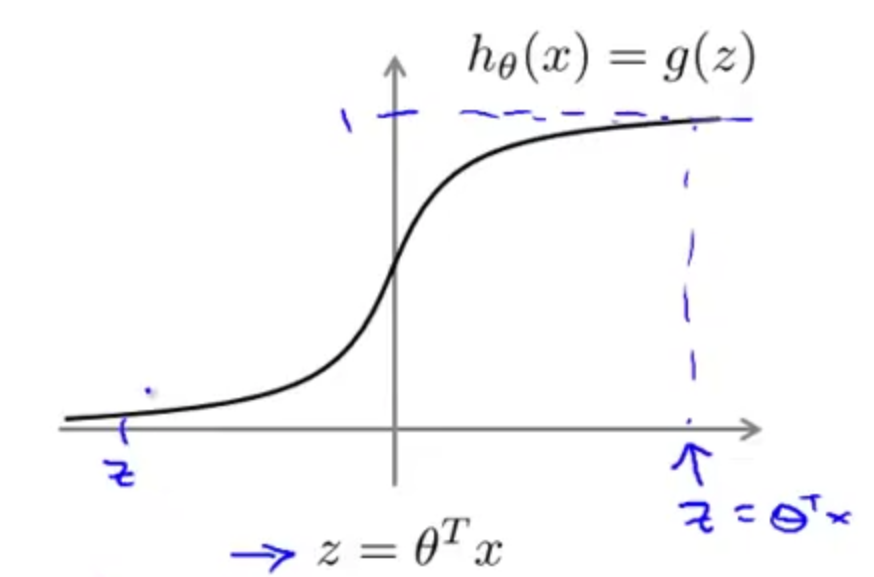
则,如果 y=1 ,那我们希望 hθ(x)≈1 ,即 θTx>>0 ;如果 y=0 ,那我们希望 hθ(x)≈0 ,即 θTx<<0 。
对于逻辑回归,对于单个样本 (x,y) ,其代价为
①如果 y=1 ,上述单个样本代价函数中只有第一项起作用,第二项为 0 。
令
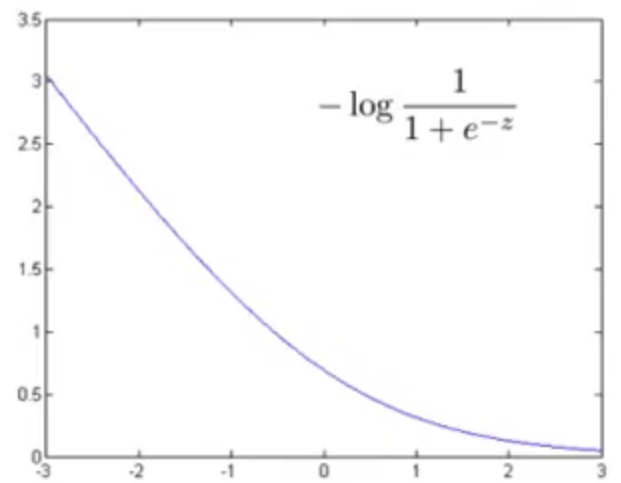
结合此图也可以看出对于正样本(即,
在支持向量机中这种情况可以用两条线段作为新的代价函数
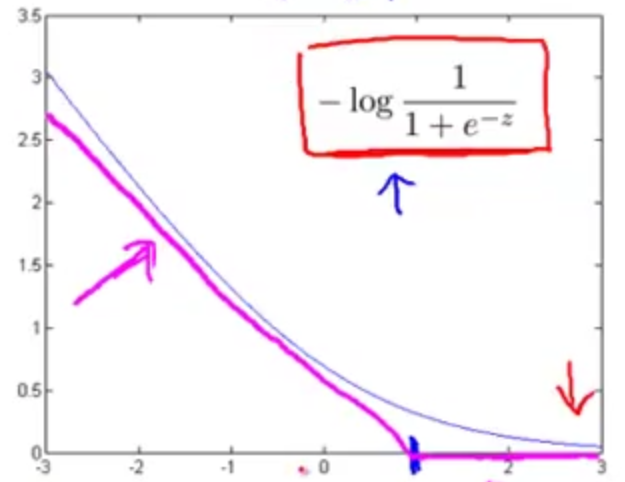
②如果 y=0 ,上述单个样本代价函数中只有第二项起作用,第一项为 0 。
此时代价随
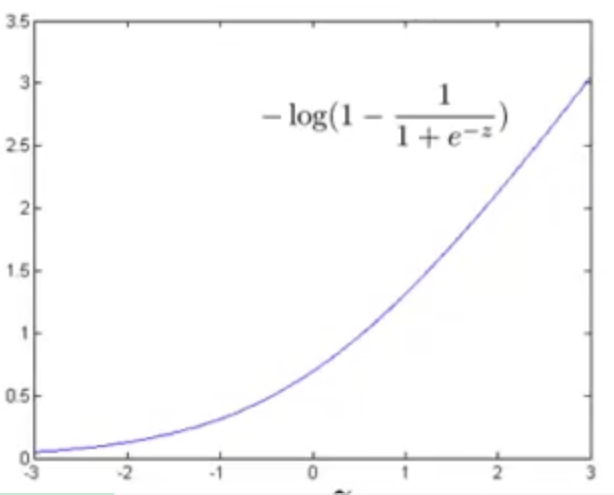
结合此图也可以看出对于负样本(即, y=0 ),为了使代价 −log(1−11+e−θTx) 最小,我们将设置 θTx 比较大,这时代价接近于 0 。
在支持向量机中可以用两条线段作为新的代价函数
2.从优化目标考虑
对于逻辑回归,优化目标是
支持向量机就是要将其中的 (−loghθ(x(i))) 换成前面 y=1 时新的单个样本代价 cost1(θTx(i)) ,将 (−log(1−hθ(x(i)))) 换成前面 y=0 时新的单个样本代价 cost0(θTx(i)) ,即
又由于无论是否有 1m 都不会影响最小化的结果,故可以忽略 1m ;
同时正则化逻辑回归总的代价函数包括两项,即 A+λB (通过 λ 控制 A,B 间的平衡),SVM则通过另一种方式控制 A,B 间的平衡,即 CA+B 。
综上,SVM的优化目标为
二.SVM的决策边界
1.SVM优化目标进一步研究
为了最小化代价函数, y=1 时,我们希望 θTx⩾1 ,而不仅仅像逻辑回归那样只要 θTx⩾0 ,就可以预测 hθ(x)=1 ;
同理, y=0 时,我们希望 θTx⩽−1 ,而不仅仅像逻辑回归那样只要 θTx<0 ,就可以预测 hθ(x)=0 。
可以看出SVM相比逻辑回归而言要求更高,相当于多了一个安全的间距因子。故人们也会将SVM看作是大间距分类器。
当 C 为一个很大的值时,为了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2780
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









