







 这篇博客介绍了社交网络中的社区检测,重点讲解了Affiliation Graph Model(AGM)和BigCLAM模型。AGM模型生成网络,BigCLAM扩展了社区的概念,引入节点在社区的活跃度。通过极大似然估计求解矩阵F,利用图谱聚类算法如拉普拉斯矩阵进行社区划分。此外,还提到了数据流挖掘中的滑动窗口和计数问题。
这篇博客介绍了社交网络中的社区检测,重点讲解了Affiliation Graph Model(AGM)和BigCLAM模型。AGM模型生成网络,BigCLAM扩展了社区的概念,引入节点在社区的活跃度。通过极大似然估计求解矩阵F,利用图谱聚类算法如拉普拉斯矩阵进行社区划分。此外,还提到了数据流挖掘中的滑动窗口和计数问题。
Communities in Social networks
Community Detection in Graphs
The Affiliation Graph Model(AGM)
Plan:
1. 由给定的模型生成网络
2. 对给定的网络找到“best”model
Model of network
Goal:Define a model that can generate networks
这个model将有一系列的参数,后续需要估计和检测community
问题是:给定一系列节点后,communities是如何产生network的边的呢?
这里我们讨论的模型就称为Community-Affiliation Graph Model它是图的生成模型。如下图:
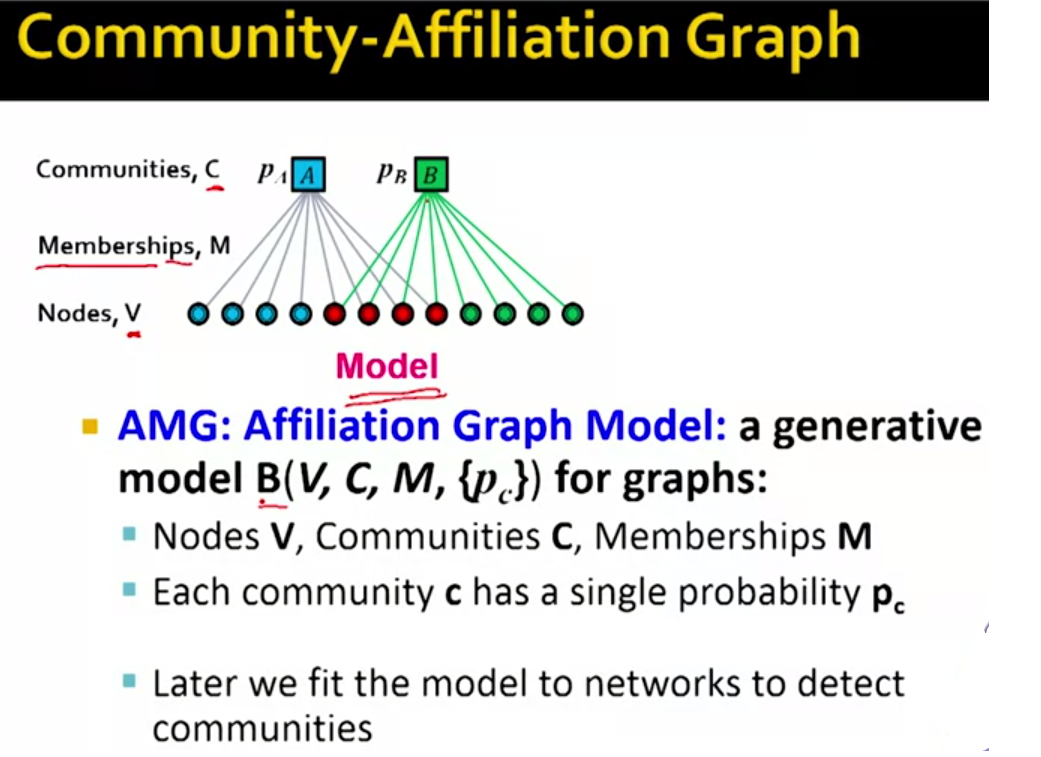
回到我们的plan计划项中第一条,我们如何根据这个AGM模型生成network呢?
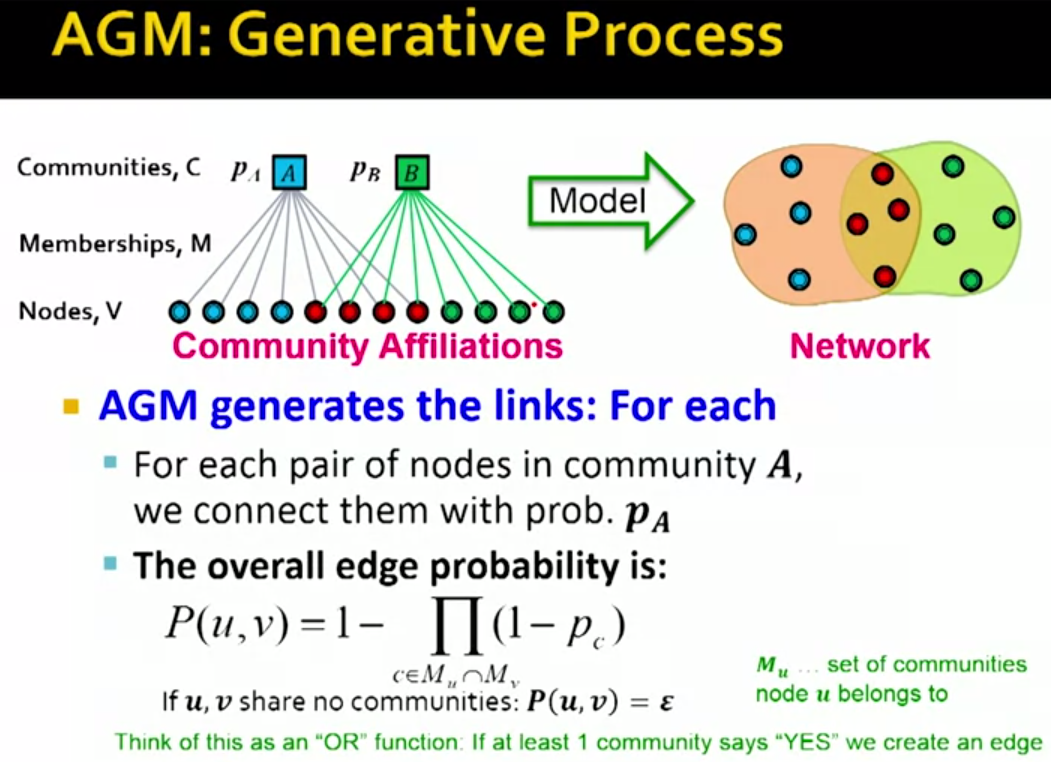
由AGM模型的式子可以看出,只要两个节点在某一个共同的Community中有边,则认为这两个节点之间是边的。
下面这张slide表明了AGM模型的灵活性

From AGM toBigCLAM
前面AGM模型中节点要么是某个Community的成员要么不是,即要么要边要么没有边,下面我们讨论的是如果edge表示的不仅仅是成员从属关系,而是成员在这个Community中的活跃度之类的信息,那么边的值就是一个>=0的值,等于0表示不是其成员,其它>0的值是一个degree。
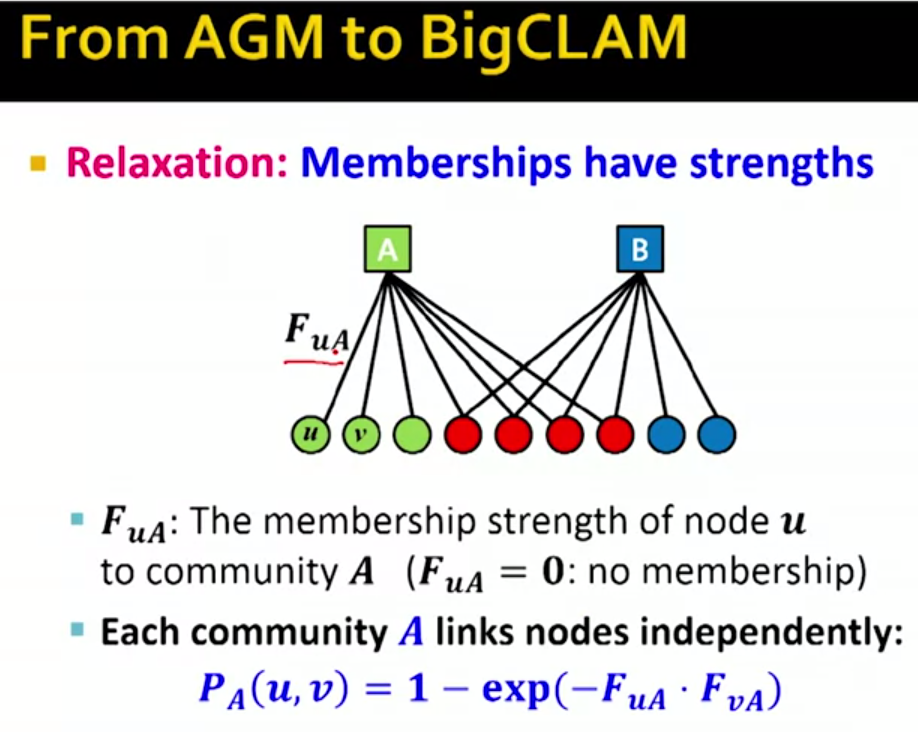
对于一个特定的Community A ,A中的两个节点u,v 之间有联系的概率计算如上图所示,不难理解其意义,如果两个节点都的degree in A都接近0,即都和Community A 的联系不紧密,那么上式结果也近似为0,那么这两者之间有联系的概率也很小,degree都接近1时反之。
上面讨论的是两个节点只共同出现在一个CommunityA里面,那么如果两个节点分在多个不同的Community都有重合呢
为了解决这个问题我们首先要介绍Community Membership Strength matrix F
如下图左边是matrix F,行表示各个节点,列表示Community

和AGM类似,两个节点间有link的概率也是至少有一个Community C links these nodes的概率。于是有

Solving The BIGCLAM
BigCLAM:How to Find F
有前面我们已经知道如果已知matrix F,求network的边的概率是可行的,
那么如何获得这个矩阵F呢?

这里使用的是极大似然估计,通常我们采用取对数的极大似然函数。

通俗来说就是找到参数F使得获得的网络图形尽可能类似于给定的网络图G。根据参数F我们知道可以获得一个网络图,这个网络图恰好就是给定的G的概率如上式argmax…因此求得这个概率的极大值即为估计的F矩阵。使用梯度上升法求极大值。

上式中每一次迭代都需要计算所有的节点,因此很浪费时间,改进如下:

Detecting Communities as Clusters
我去,手贱了一下把写好的东西都弄没了,还没上传,那这部分就直接总结大意好了,反正Week3的东西总体都很好理解。
What Makes a good Cluster?

一个good cluster,它内部的connection要尽可能多,与外界的联系要尽可能少。因此我们定义了一个Graph Cut的概念。
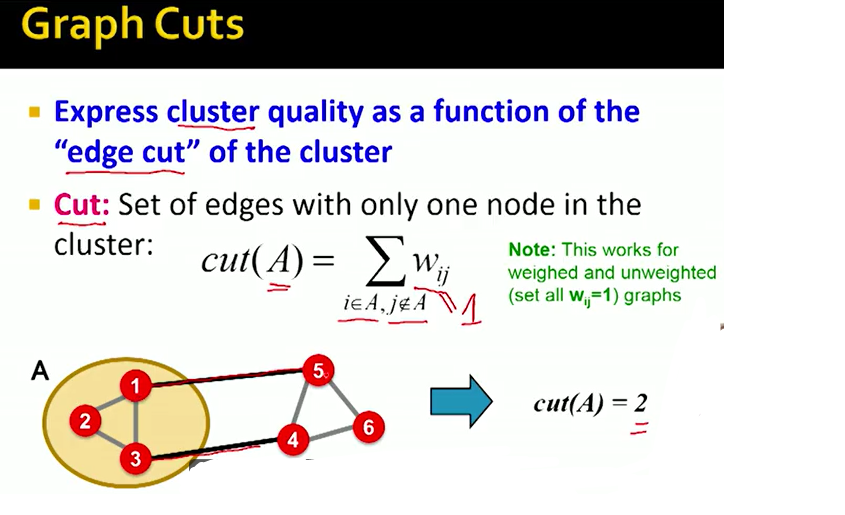
Cut指的是有且只有一个点在clusterA中的边,如图中黑色边
那么Cut score也就可以代表cluster quality中一个重要的部分了。即上张图中minimum的部分,即与外界的联系尽可能少。
但是单纯使用Cut score还不够,原因如下图最右边的绿色节点划分问题。
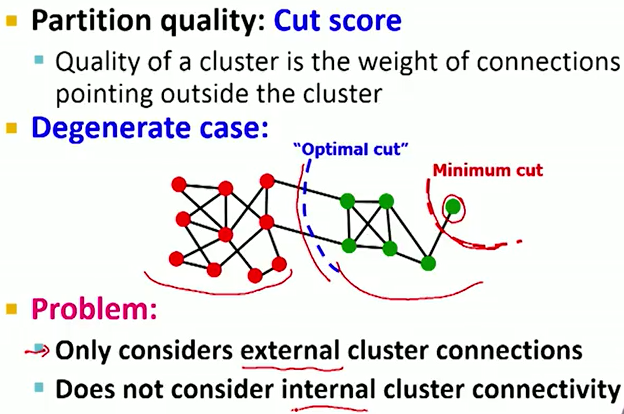
因此我们需要在此基础上进行改进。
Graph Partitioning Criteria

如上图, ϕ(A)=Cut(A)Vol(A)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









