




直接插入排序的平均复杂度是 \(O(n^2)\),因此应用场景较少。
直接插入排序的思路是: 每次处理一个数据,将其插入到一个已经排好序的子序列中,直到数据处理完毕。
下面给出一个动画示例:
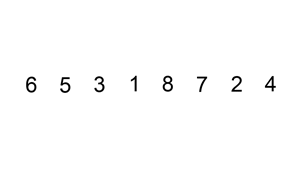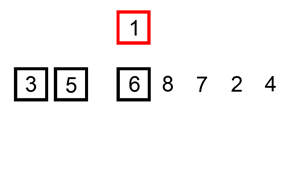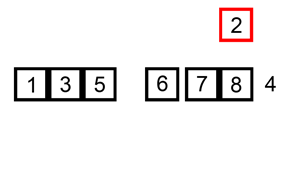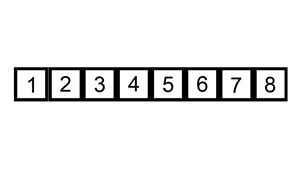
从上面来看我们也可以发现一些优点:
(1) 实现简单,比其它 \(O(n^2)\) 排序算法高效;
(2) 当数据已经基本有序时,效率较高;
(3) 排序稳定,并且需要的额外存储空间小;
(4) 可以快速处理新增加的数据;
参照动画我们可以很容易的理解下面的c++代码:
void insertsort (int data[], int n){
int j, temp;
// 外层循环负责依次处理每一个元素(忽略第一个)
for (int i = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4160
4160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









