









 本文介绍了如何使用R语言igraph包进行关系网络分析,包括不同数据类型的处理方法、自定义函数构造网络、基本操作及解决重复性问题。
本文介绍了如何使用R语言igraph包进行关系网络分析,包括不同数据类型的处理方法、自定义函数构造网络、基本操作及解决重复性问题。
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
笔者寄语:这里所有的应用代码都来自与igraph包。《R语言与网站分析》书中第九章关系网络分析把大致的框架已经描述得够清楚,但是还有一些细节需要完善,而且该书笔者没找到代码。。。
————————————————————————————————————————
一、关系网络数据类型
关系网络需要什么样子的数据呢? 笔者接触到了两种数据结构,擅自命名:平行关系型、文本型。根据数据关联,也有无向数据、有向数据。
并且关系网络生成之后,R里面就不是用真实的名字来做连接,是采用编号的。例如(小明-小红)是好朋友,在R里面就显示为(1-2),所以需要单独把名字属性加到序号上。
1、平行关系型
(1)无向平行数据。直接上例子比较直观,社交网络中的好友关系,你-我,我-他。这样排列,是无向
id1 di2
小明 小红
小张 小白
小红 小胖
小胖 小蓝
小白 小明
小白 小张
小明 小胖很简单的两列数据,说明了小明-小红、小张-小白的社会关系。当然需要注意,重名问题,名字可能有重叠,可以给每个人一个编号,这样就不会出现重名。
实战中,一般是拿编号作为输入变量,拿名字作为编号的标签,加入到关系网络中。
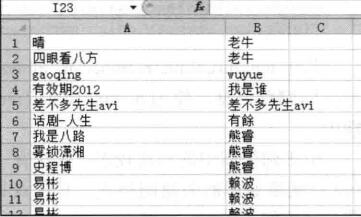
(2)有向平行数据。举一个书(《R语言与网站分析》)上的例子。解读一下这个图,这是一条微博的转发情况,“老牛”用户这个微博号转发,让“晴”、“四眼看八方”两个用户看到了。
“老牛”用户发出,“晴”、“四眼看八方”用户分别接收到。
2、文本型
文本型主要针对的是文本数据,笔者在参赛时就用到这个。文本型也有两种情况:有向型以及词条-文本矩阵。这部分内容跟文本挖掘相关,关于分词内容可以参考中文分词包Rwordseg。
(1)有向型就如同平行关系型有向数据结构一样,人名-词条两个
| 人名 | 词条 |
| 小明 | 小气 |
| 小张 | 帅气 |
| 小红 | 好看 |
| 小胖 | 胖 |
| 小白 | 帅气 |
| 小白 | 阳光 |
| 小明 | 贪吃 |
(2)词条-文本矩阵
文本挖掘中,一般都能获得这个矩阵,可以看一下tm包的博客,文档-词频矩阵。tm包中用DocumentTermMatrix函数可以获得。
| 小气 | 帅气 | 好看 | 胖 | 阳光 | 贪吃 | |
| 小明 | 1 | 0 | 0 | 0 | 1 | |
| 小张 | 0 | 1 | 0 | 0 | 0 | 0 |
| 小红 | 0 | 0 | 1 | 0 | 0 | 0 |
| 小胖 | 0 | 0 | 0 | 1 | 0 | 0 |
| 小白 | 0 | 1 | 0 | 0 | 1 | 0 |
跟上面的对比一下就了解,变成了一个稀疏矩阵,相关的关联规则、随机森林中中也会用到这个矩阵。tm包可以实现,也可以通过reshape包中的cast函数,构造这个函数。
需要原来的数据框调整为以每个词作为列名称(变量)的数据框。也就是一定意义上的稀疏矩阵(同关联规则),也就是将long型数据框转化为wide型数据框。转换可以用的包有reshape2以及data.table。
其中,data.table里的`dcast`函数比reshape2包里的`dcast`好用,尽管他们的参数都一样,但是很多人还是比较喜欢老朋友reshape2包,然而这一步需要大量的内存,本书在服务器上完成的,如果你的电脑报告内存不足的错误,可以使用data.table包里的`dcast`函数试试。转化为稀疏矩阵,1表示访问,0表示未访问。
————————————————————————————————————————
二、构造关系网络
1、自编译函数init.igraph
看到了数据类型,大概知道其实需要两样东西,一个起点数据列、一个终点数据列。那么构造数据就只需要调用一下函数,在这里选用《R语言与网站分析》书中第九章关系网络分析中,李明老师自己编译的函数来直接构造。
在使用之前需要library调用igraph包,该函数的好处就是直接帮你打上点标签以及线标签。
init.igraph<-function(data,dir=F,rem.multi=T){
labels<-union(unique(data[,1]),unique(data[,2]))
ids<-1:length(labels);names(ids)<-labels
from<-as.character(data[,1]);to<-as.character(data[,2])
edges<-matrix(c(ids[from],ids[to]),nc=2)
g<-graph.empty(directed = dir)
g<-add.vertices(g,length(labels))
V(g)$label=labels
g<-add.edges(g,t(edges))
if (rem.multi){
E(g)$weight<-count.multiple(g)
g<-simplify(g,remove.multiple = TRUE,
remove.loops = TRUE,edge.attr.comb = "mean")
}
g
}data,是两列关系数据,前面已经讲过了,只能两列,而且要同等长度;
dir,逻辑值,T代表有向图,F无向图;
rem.multi,逻辑,T删除重复变量并更新线权重weight,F不删除并且线权重为1。
使用方法直接init.igraph(data,dir=T,rem.multi=T)即可。
2、文本型数据
一般数据结构都可以套用上面的函数,包括平行关系型的有向、无向;文本型。其中对于文本矩阵型数据还有一个办法,参考于统计词画番外篇(一):谁共我,醉明月?
利用igragh包中的graph_from_adjacency_matrix函数。
adjm <- matrix(sample(0:1, 100, replace=TRUE, prob=c(0.9,0.1)), nc=10)
g1 <- graph_from_adjacency_matrix( adjm ,weighted=TRUE,mode="undirected")
## 给稀疏矩阵行列进行命名
rownames(adjm) <- sample(letters, nrow(adjm))
colnames(adjm) <- seq(ncol(adjm))
g10 <- graph_from_adjacency_matrix(adjm, weighted=TRUE, add.rownames="row",add.colnames="col")代码解读:adjm是随便构造的一个矩阵,函数;
graph_from_adjacency_matrix中,
weighted=TRUE,是否需要加入权重;
mode有directed, undirected, upper, lower, max, min, plus有这么几种,min代表把无向图中,只选取最小数字的线(1,1)与(1,2)只选择(1,1)。具体请参看函数官方解释。
add.rownames以及add.colnames,因为前面的自编译函数init.igraph可以自定义标签,这里定义名称,可以用add.rownames加入标签列,这样你可以用V(g10)$row以及V(g10)$col直接看到标签。其中还可以自己定义名字,row,col都是笔者自己定义的。
————————————————————————————————————————
三、一些基本操作
关系网络中,每一个点的信息存放在V中,每一个线的信息存放在E中。并且通过自编译的init.igraph函数,V(g)$label以及E(g)$weight都是自带的属性。
可以生成一个空的关系网络。
并且关系网络生成之后,R里面就不是用真实的名字来做连接,是采用编号的。例如(小明-小红)是好朋友,在R里面就显示为(1-2),所以需要单独把名字属性加到序号上。
g<-graph.empty(directed=F)1、关系网络中的点集V
点集就是网络中所有的点,如有向文本型那个数据格式,包括了14个点;7条线。
(1)点集属性
点集与数据框的操作很相似,属性是可以自己赋上去的,比如V(g)$label就是赋上去的,你还可以给点集加上颜色(V(g)$color)、加上每个点的尺寸(V(g)$size),加上分类(V(g)$member)
点集的选择跟数据框操作一样,比如我要选择群落为1的点集,就是V(g)[which(V(g)$member==1)]
比如我要选择点度数大于1的点集,V(g)[degree(g)>1]
如果我想知道一下这两个点之间是否有关系,可以用edge.connectivit函数,edge.connectivity(g, 4,9) 代表着第四个点与第九个点之间是否有连接关系。返回的0/1。0是没有线,1代表有线。
(2)点集加减操作
我想在原来的基础上加入一些点,用add.vertices
g<-add.vertices(g,length(labels))#关系网络中加入“点”g<-g-V(g)[degree(g)==0] (3)相邻点的集合——neighbors(很重要)
neighbors(g.zn,v=which(V(g.zn)$label=="会计"))
V(g.zn)$label[neighbors(g.zn,v=which(V(g.zn)$label=="取向"),mode="total")]
#默认mode设置是out,还有 in,total;其中V(g.zn)$label和V(g.zn)一个返回标签,一个返回值其中mode代表点出度(out)以及点入度(in),还有两个都有的点度(total)。
该函数可以对于点集,做附近的画像,比较好用。
2、关系网络中的线集E
(1)线集的类型
关系网络中线的关系比较多,loop线就是循环到自己的点,1-2-1;multiple代表线的重叠。
which_loop(g) #线是否能够指回自己,1-1就是指回自己
which_multiple(g) #是否有重复线,后面1-1与前面1-1重复了(2)线集属性
g<-set_vertex_attr(g,"name",value=V(g)$label)线集的属性中也可以跟数据集一样进行筛选操作。
temp<-E(g)[order(E(g)$weight>25000)](3)线集加减
线集的加减可以用add.edges以及-来实现
g<-add.edges(g,t(edges)) #edges需要先转置
g<-g-E(g)[(weight>1)] #删除部分线其中需要注意,add.edges中,需要把列数据,转置为行数据,平放id与词条。
同时线集也会有重复性的问题,见下文count.multiple(g) 以及simplify函数。还有一些特别的函数,diameter(g)可以做到最长的链接经过了多少根线。
4、关系网络的重复性问题
在关系网络中,重复是常见的,而且无向线中1-2与2-1是重复的,重复线的数量也可以作为线的权重。也就是E(g)$weight。其中igrarh包中笔者看到两个函数跟重复性问题有关。count.multiple(g) 以及simplify函数。
(1)count.multiple(g) 函数
可以获得网络中线的重复情况。不重复是1,重复一次+1。比如:无向网络(1-2,2-3,2-1)就是(2,1,2)
等价于E(g)$weight
(2)simplify函数
函数常规式:simplify(g,remove.multiple = TRUE,remove.loops = TRUE,edge.attr.comb = "mean")
其中loops是指是否循环回自己,比如1-2-1就是一个循环到自己;multiple是指重复比如1-2,2-1。
h <- graph( c(1,2,1,2,3,3,2,1,4,4) );h
is_simple(h)
simplify(h, remove.loops=FALSE) #线重复,删除a->b,a->b删掉
simplify(h, remove.loops=TRUE) #在线方向性重复基础上删掉点重复,a->a,b->b
simplify(h, remove.multiple=FALSE)#删掉点重复
simplify(h, remove.multiple=TRUE)#删掉点重复同时,删除线a->b,a->b
simplify(h, remove.multiple=TRUE,remove.loops=TRUE) #删掉线重复、点重复simplify函数识别了两种重复方式,一种是线重复,比如1-2,2-1,;一种是点重复比如1-1,2-2就是点重复。
remove.multiple=TRUE,把重复的线删除edge.attr.comb,使用重复次数来更新线权重E(g)$weight
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————

















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









