







DIGITS: Deep Learning GPU Training
System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统。目的在于整合现有的Deep
Learning开发工具,实现深度神经网络(Deep Neural
Network,DNN)设计、训练和可视化等任务变得简单化。DIGITS是基于浏览器的接口,因而通过实时的网络行为的可视化,可以快速设计最优的DNN。DIGITS是开源软件,可在GitHub上找到,因而开发人员可以扩展和自定义DIGITS。
Github界面:https://github.com/NVIDIA/DIGITS/tree/master/docs
笔者还有话说: 笔者是从传统统计学过来的,我觉得Nvidia
DIGITS就是接下来深度学习的SPSS,这是一个开端,笔者觉得接下来会有很多框架会有这样的可视化操作界面。
特别是Tensorflow是基于节点流进行编译算法,编译起来又特别麻烦,笔者觉得tensorflow如果可以效仿SPSS
Modeler一样流运作,也是极好的~
一、安装基本环境
本节会简单介绍一下安装需求,其实如果有GPU,后续也就顺理成章的可以安装出来了。一般在安装、并配置好caffe之后,直接再安装DIGITS即可。
- 1、如官方所述,DIGITS现在仅支持Ubuntu,当然也在其它Linux系统上测试成功,未见有在Windows上配置的案例;
- 2、DIGITS尝试囊括更多的开源Deep Learning 框架,当前(digits-2.0)仅包括:Caffe, Torch, Theano, and BIDMach.
采用源码安装DIGITS前,事先要安装CUDA(必须)、cuDNN(用于GPU加速,建议安装),Caffe(运行DIGITS至少要有一个Deep Learning framework,也可以安装Theano,这里不介绍)。
- 操作系统:Ubuntu 14.04 LTS 64 bit(ubuntu-14.04.3-desktop-amd64.iso)
- CUDA:CUDA-7.0(cuda-repo-ubuntu1404-7-0-local_7.0-28_amd64.deb),支持CUDA的GPU
- cuDNN:cuDNN-7.0(cudnn-7.0-linux-x64-v3.0-rc.tgz)
- Caffe:Caffe-0.13.0(caffe-master.zip,必须是NVIDIA’s fork,原因点此)
- DIGITS:DIGITS-2.0(源码安装,DIGITS-master.zip)
二、详细的安装过程
本文只是笔记,就不累述安装配置过程。可见博客以下几类博客:
- 1、NVIDIA DIGITS 学习笔记(NVIDIA DIGITS-2.0 + Ubuntu 14.04 + CUDA 7.0 + cuDNN 7.0 + Caffe 0.13.0)
http://blog.csdn.net/enjoyyl/article/details/47397505#安装digits - 2、Ubuntu下安装CAFFE-Digits
http://blog.csdn.net/striker_v/article/details/53096279 - 3、Ubuntu14.04 CUDA/cuDNN/caffe/DIGIT 安装备忘录
http://www.lryb.net/?p=849
还有一个BUG!就是supervessel超能云服务器上已经帮你配置好DITIGS,不过笔者在尝试的时候并没有尝试成功,之后会开贴说一下supervessel: supervessel-免费云镜像︱GPU加速的Caffe深度学习开发环境
三、一些DIGITS实际运行案例
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
http://www.cnblogs.com/denny402/p/5136155.html - Caffe学习系列(22):caffe图形化操作工具digits运行实例
http://www.cnblogs.com/denny402/p/5136262.html - DIGITS: Deep Learning GPU Training System
https://devblogs.nvidia.com/parallelforall/digits-deep-learning-gpu-training-system/ - NVIDIA DIGITS
Interactive Deep Learning GPU Training System
https://developer.nvidia.com/digits - Fine Tuning,微调 AlexNet:机器学习初学者入门实践:怎样轻松创造高精度分类网络
http://www.jiqizhixin.com/article/2087
其中机器之心翻译文章很棒!!强推!!:机器学习初学者入门实践:怎样轻松创造高精度分类网络,非常棒,入门级!!
四、可视化界面介绍
几个比较好的功能点,贴图贴真相:
- 1、点击式菜单界面
- 2、而且可视化了深度学习训练过程
- 3、报错都直接帮你显示出来
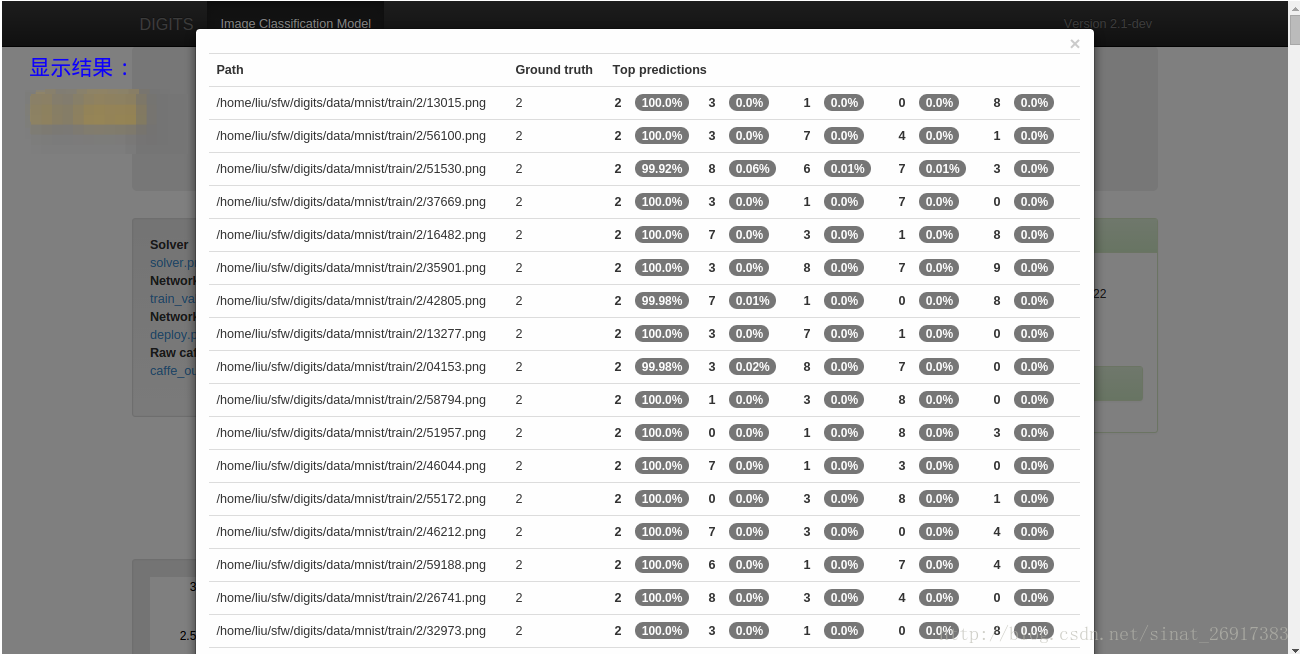
- 4、分类结果的可视化
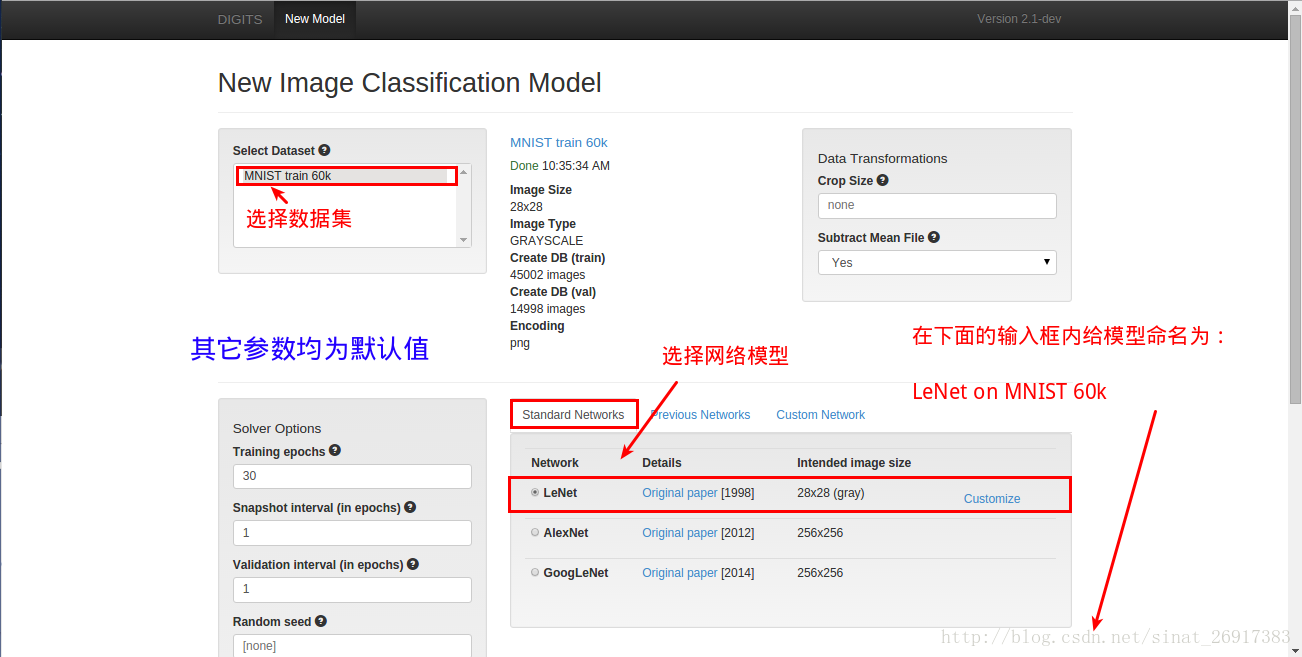
点击式菜单界面,而且可视化了深度学习训练过程。
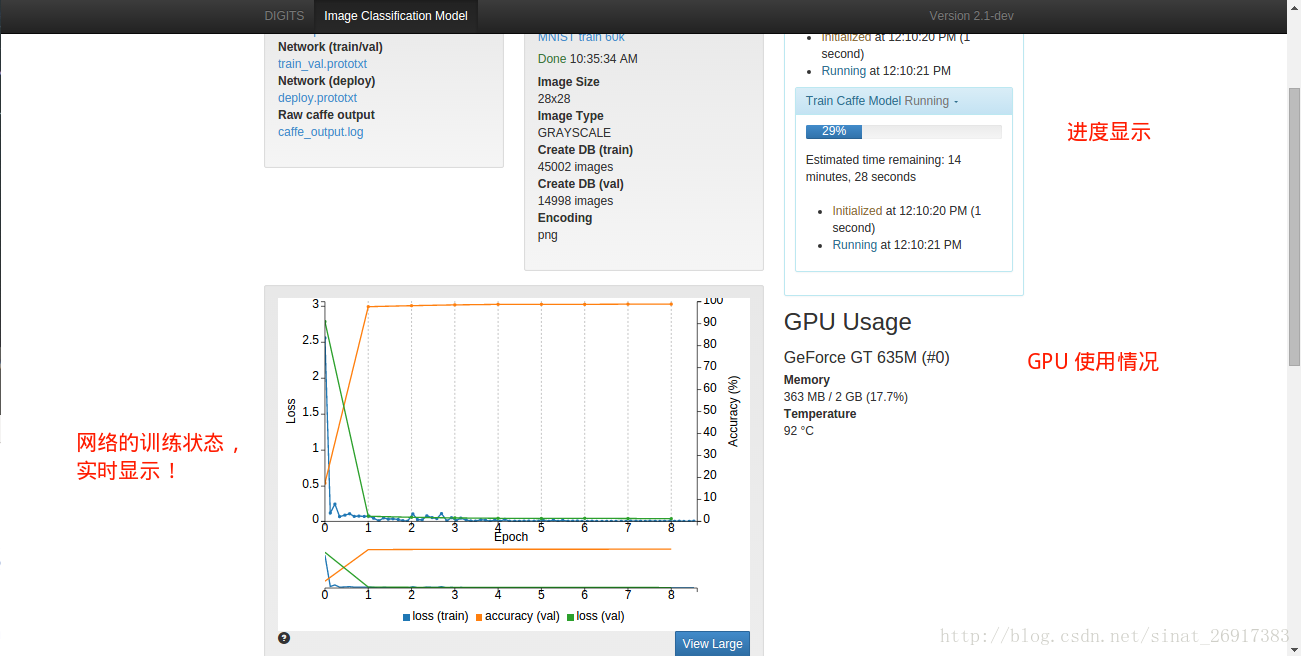
报错都直接帮你显示出来,以便查看出错在哪:
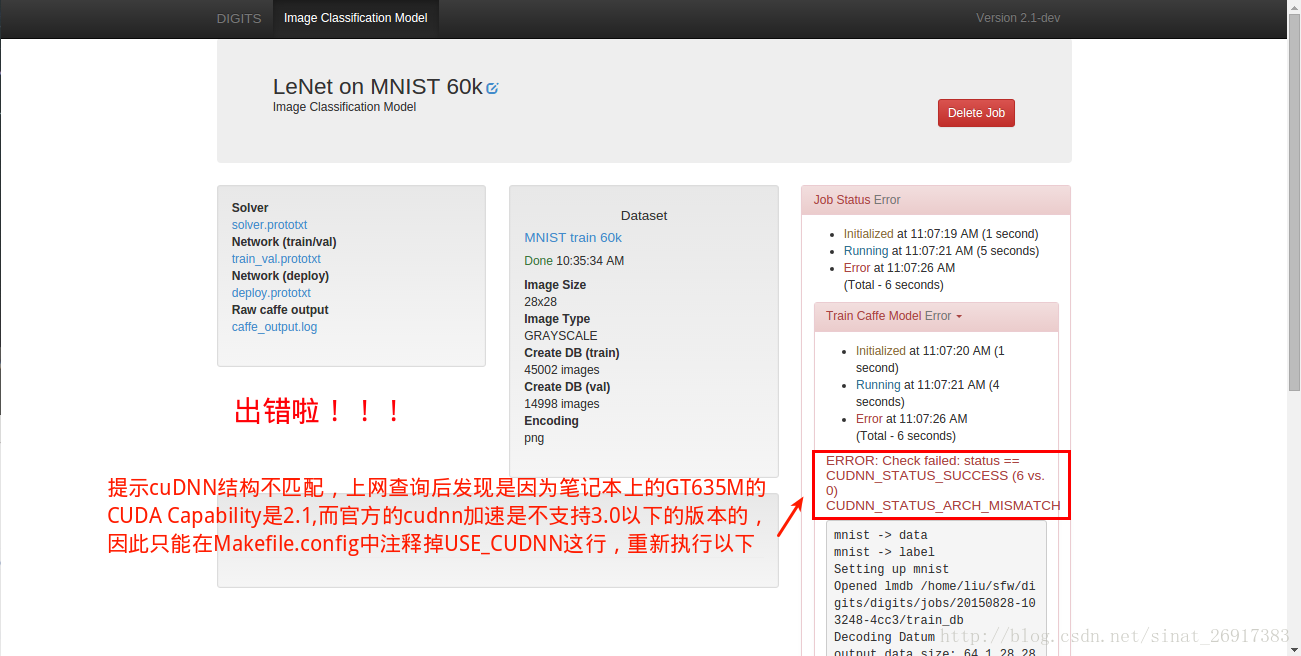
分类结果的可视化:
参考文献:
NVIDIA DIGITS 学习笔记(NVIDIA DIGITS-2.0 + Ubuntu 14.04 + CUDA 7.0 + cuDNN 7.0 + Caffe 0.13.0)
http://blog.csdn.net/enjoyyl/article/details/47397505#安装digits
.
.
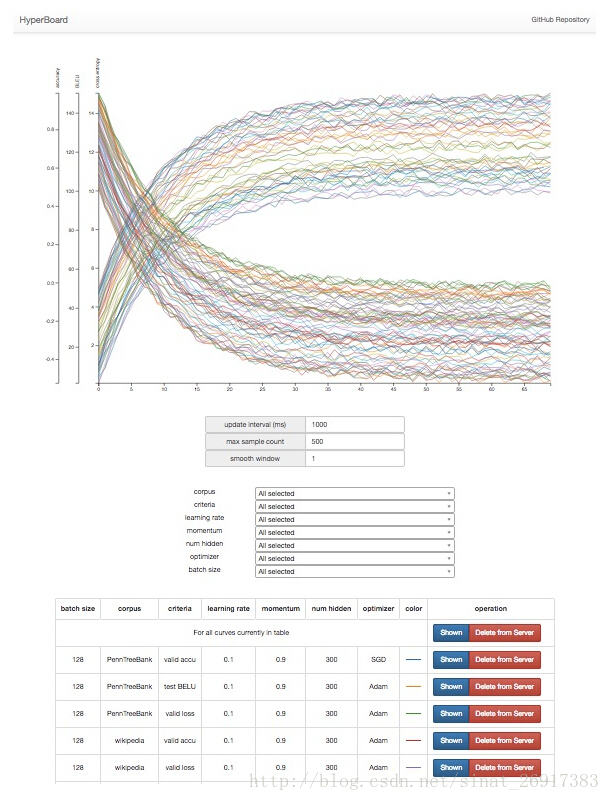
延伸一:深度学习调参网页版HyperBoard
HyperBoard 是一个辅助深度学习调参的网页端可视化工具,不依赖于特定的深度学习框架(如 Tensorflow),能够在远程服务器训练模型的同时在本地浏览器进行可视化。
目前支持训练曲线的实时更新,可以方便地按照超参数组合对几十上百条训练曲线进行筛选和隐藏,下一步计划支持动态的统计直方图和向量可视化功能。
项目源码及文档地址:
https://github.com/WarBean/hyperboard
界面局部如下所示:
延伸二:DIGITS安装实践
安装的官方网址参考链接:
https://github.com/NVIDIA/DIGITS/blob/master/docs/UbuntuInstall.md
开始的方式,在浏览器键入,或者有以下几种方式:
http://localhost/
http://<EC2_INSTANCE_PUBLIC_IP>
#参考:https://github.com/bitfusionio/amis/tree/master/awsmrkt-ubuntu-digits启动Digits服务:
% sudo start nvidia-digits-server关闭Digits服务:
% sudo stop nvidia-digits-server可参考博客:
http://blog.csdn.net/striker_v/article/details/53096279
- 报错一:
/usr/share/lua/5.1/cunn/THCUNN.lua:7: libcusparse.so.7.5: cannot open shared object file: No such file or directory最简单的修复的方式:
sudo apt-get install cuda-cusparse-7-5
sudo ldconfig- 报错二:
now i have a new problem ,like tihs
user@user-ProLiant-DL380-Gen9:~/digits$ ./digits-devserver
Default value for caffe_root "<PATHS>" invalid:
caffe binary not found in PATH
==================================== Caffe =====================================
Where is caffe installed?
Suggested values:
(P*) [PATH/PYTHONPATH] <PATHS>
>> ~/caffe
ERROR: Library at "libcaffe.so.1.0.0-rc3" does not have expected suffix "-nv". Are you using the NVIDIA/caffe fork?
Invalid input无解Ing,谁来help,怎么输链接,都没用。
参考链接:
https://github.com/NVIDIA/DIGITS/issues/1292
.
延伸三:一般服务器使用步骤
一般在公司服务器,只要连接的是公司的网络,只要服务器一直开着并启动digits就可以公司内服务器连用。
1、启动
来到digits文件夹的寻找并键入:
sudo ./digits-devserver2、键入地址
如果是服务器本机,键入:
0.0.0.0:5000/如果其他机器访问,则先得到该服务器的内网IP
http://xxx.xxx.xxx.xxx:5000/














 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









