



 本文探讨了ReLU激活函数的使用及其在训练过程中可能遇到的问题,如‘死ReLU’现象,并介绍了几种改进方案,如LeakyReLU和ParametricReLU,以提高其在深度学习任务中的表现。
本文探讨了ReLU激活函数的使用及其在训练过程中可能遇到的问题,如‘死ReLU’现象,并介绍了几种改进方案,如LeakyReLU和ParametricReLU,以提高其在深度学习任务中的表现。
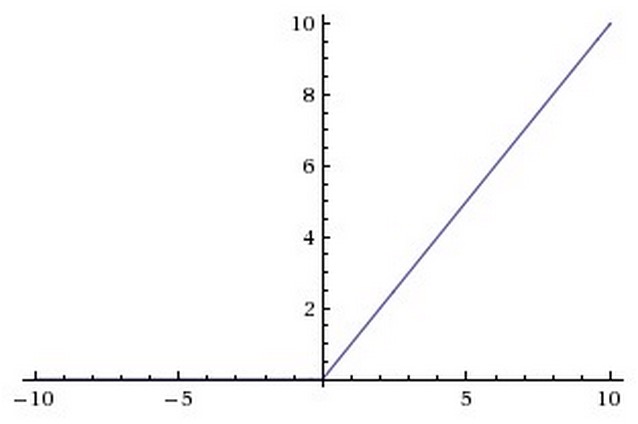
There are several pros and cons to using the ReLUs:
- (Pros) Compared to sigmoid/tanh neurons that involve expensive operations (exponentials, etc.), the ReLU can be implemented by simply thresholding a matrix of activations at zero. Meanwhile, ReLUs does not suffer from saturating.
- (Pros) It was found to greatly accelerate the convergence of stochastic gradient descent compared to the sigmoid/tanh functions. It is argued that this is due to its linear, non-saturating form.
- (Cons) Unfortunately, ReLU units can be fragile during training and can “die”. For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% of your network can be “dead” (i.e., neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.
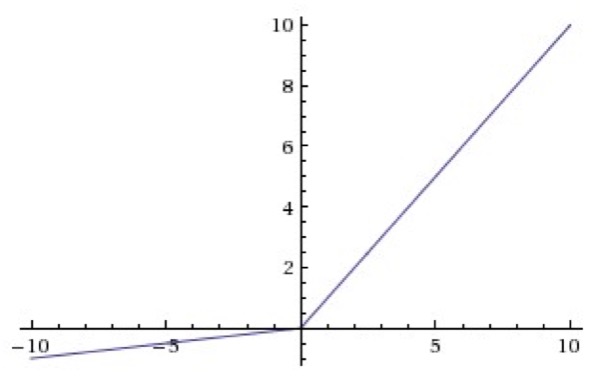
Leaky ReLU
Parametric ReLU
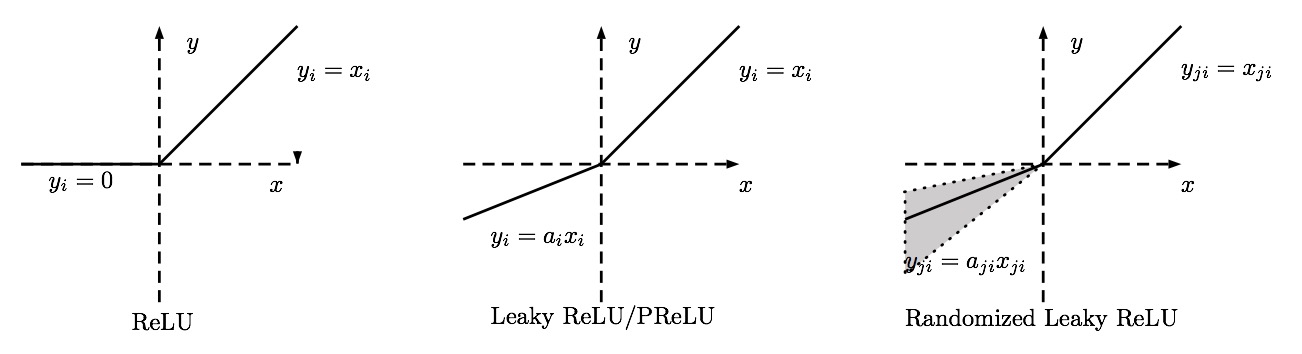
The first variant is called parametric rectified linear unit (PReLU). In PReLU, the slopes of negative part are learned from data rather than pre-defined.
Randomized ReLU
In RReLU, the slopes of negative parts are randomized in a given range in the training, and then fixed in the testing. As mentioned in [B. Xu, N. Wang, T. Chen, and M. Li. Empirical Evaluation of Rectified Activations in Convolution Network. In ICML Deep Learning Workshop, 2015.], in a recent Kaggle National Data Science Bowl (NDSB) competition, it is reported that RReLU could reduce overfitting due to its randomized nature. Moreover, suggested by the NDSB competition winner, the random
In conclusion, three types of ReLU variants all consistently outperform the original ReLU in these three data sets. And PReLU and RReLU seem better choices.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









