







数据的标准化、中心化、归一化以及R语言中的scale
本文参考:
Gower (1985), Johnson and Wichern (1992), Everitt (1993), and van Tongeren (1995)
https://www.biomedware.com/files/documentation/Preparing_data/Methods_for_data_standardization.htm
http://www.dataminingblog.com/standardization-vs-normalization/
http://www.360doc.com/content/14/0408/20/7673502_367328521.shtml
在进行数据处理是经常会遇到两组或多组数据不对等的情况,比如一组数据均值为12,另一组数据为均值为320,这时候如果希望比较这两组数据就需要对数据进行处理。至于归一化、标准化、中心化需要根据实际问题进行处理。
归一化(Normalization)
数据的归一化一般认为是:
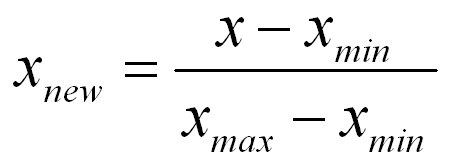
这样数据的范围在[0,1]之间
有时候我们需要针对不同的问题进行不同的归一化,比如在处理基因芯片数据时为了让每个芯片的数据在同一个范围内可以根据均值和中位数进行标准化。
标准化(Standardization)
数据的标准化一般认为是:
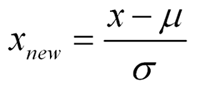
这样数据的均值为0,标准差为1,也成为z-score
标准化数据可以使用R语言的scale函数
data <- c(1, 2, 3, 6, 3)
scale(data, center=T,scale=F)
[,1]
[1,] -2
[2,] -1
[3,] 0
[4,] 3
[5,] 0
attr(,”scaled:center”)
[1] 3
数据标准化
scale(data, center=T,scale=T)
[,1]
[1,] -1.06904
[2,] -0.53452
[3,] 0.00000
[4,] 1.60357
[5,] 0.00000
attr(,”scaled:center”)
[1] 3
attr(,”scaled:scale”)
[1] 1.8708
scale方法中的两个参数center和scale的解释:
1.center和scale默认为真,即T或者TRUE
2.center为真表示数据中心化(只减去均值不做其他处理)
3.scale为真表示数据标准化
















 4259
4259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











