







感知机算法
感知机(Perceptron)算法是一种很好的二分类在线算法,它要求是线性可分的模型,感知机对应于在输入的空间中将实例划分成正负样本,分离它们的是分离超平面,即判别的模型。
如下图所示:可用一个决策边界w*x+b将正负样本进行区分。其中w为权重,b为偏置项。(w*x1+b)>0被分为正样本,否则为负样本。
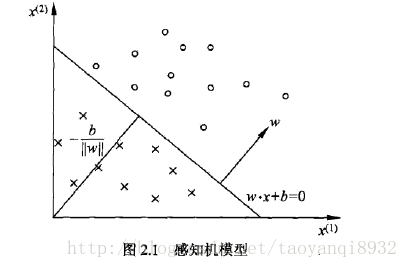
来源:统计学习方法
感知机学习策略
假定要本线性可分,感知机的学习目标就是求的能将正负要本完全正确分开的分离超平面,即要寻找w,b,因此要确定一个学习策略,即定义损失函数并使其最小化。而感知机所采用的损失函数为所有误分点到超平面的距离。
推到过程如下:

当没有误分点是,L(w,b)=0,表示没有损失,而且误分点越少,误分点离超平面越近,其损失越小。感知机的学习策略就是选择(w,b)使得损失函数最小。
感知机学习算法
感知机的学习算法也就是对损失函数L(w,b)进行求解的过程。
感知机算法是由误分类点驱动的,采用随机梯度下降法进行求解,过程如下图所示:

从上述学习过程中,我们可以看到,感知机学习出来的超平面w*x+b并不是唯一的,其由于选择了
1.不同的初值
2.在训练中是随机的选择一个误分类点进行更新w,b
因此,其解的w,b结果并不唯一,熟悉SVM的可能会知道,其解是唯一的。
在线性可分的时候,感知机是收敛的,具体的证明过程可以参考<统计学习方法>,如果是不可分的,感知机是不收敛的,迭代的结果会发生震荡。
感知机学习算法的对偶形式
其实感知机学习算法的对偶形式也很简单,因为在原始的问题中我们对w,b进行反复的修改,加上修改了n次,则最后学习到的w,b可以表示为:
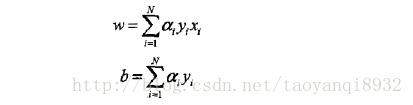
原始问题中通过学习w,b使其收敛,对偶问题输出的结果是alpha,b,算法过程如下:

来源:统计学习方法
感知机的缺点
感知机是线性的模型,其不能表达复杂的函数,不能出来线性不可分的问题,其连异或问题(XOR)都无法解决,因为异或问题是线性不可分的,怎样解决这个问题呢,通常有两种做法。
其一:用更多的感知机去进行学习,这也就是人工神经网络的由来。
其二:用非线性模型,核技巧,如SVM进行处理。
下面将对人工神经网络进行介绍。
人工神经网络
如下图所示一个典型的神经网络:
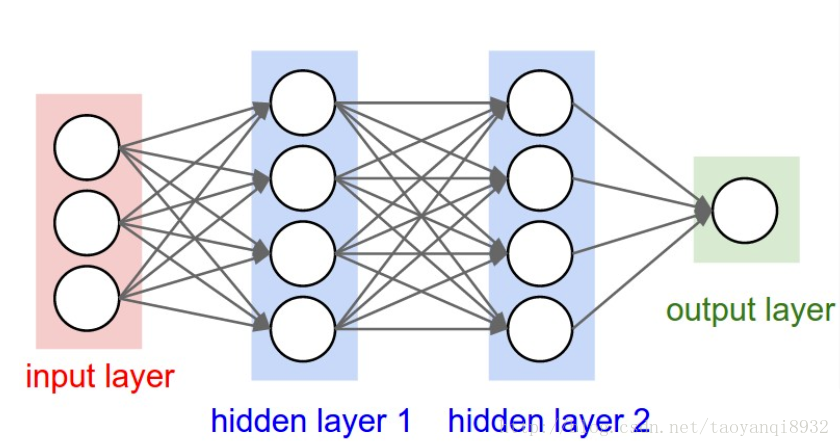
一个神经网络有许多小的感知器组成。
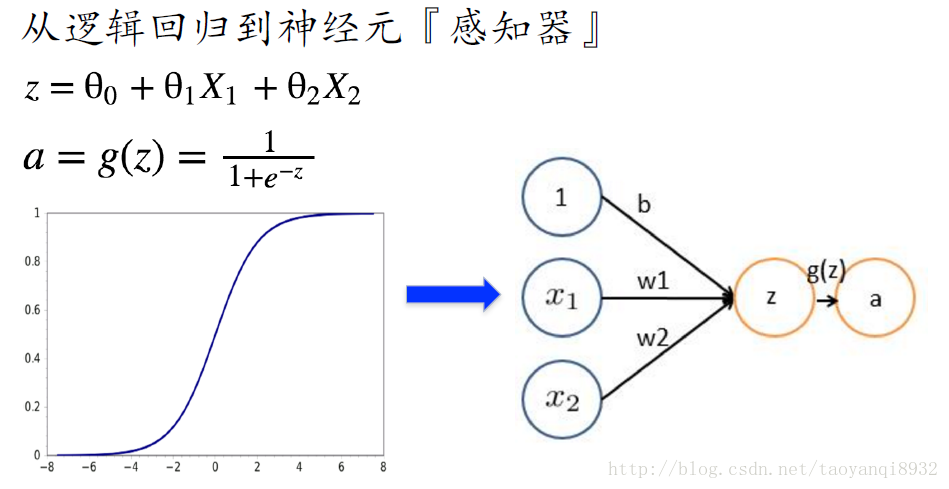
z为一个简单的线性分类器,g(z)为对其加上激活函数(Active function)。
神经网络激活函数
激活函数也叫传递函数,它有许多的种类如下图所示:
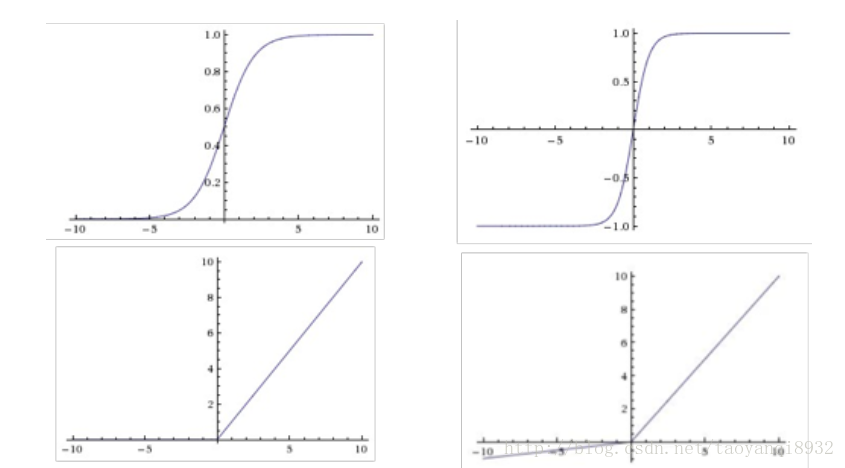
上图分别为sigmoid,tanh,relu,leaky relu,其中在人工神经网络中常用的是sigmoid函数,卷积神经网络中常用的是relu.
为什么需要激励函数?
简单的来说有两个原因:
- 让不让当前的信号传递过去,或者以多大的信号传递过去
- 使其变成非线性
我们不能将所有的信号都传递到下一层,因此要有选择的进行传递,即激励函数可以做到这一点。同时如果不加激励函数,直接让信号过去,那么相当于线性分类器,并没有改变分类器的本质。
神经网络如何处理线性不可分问题
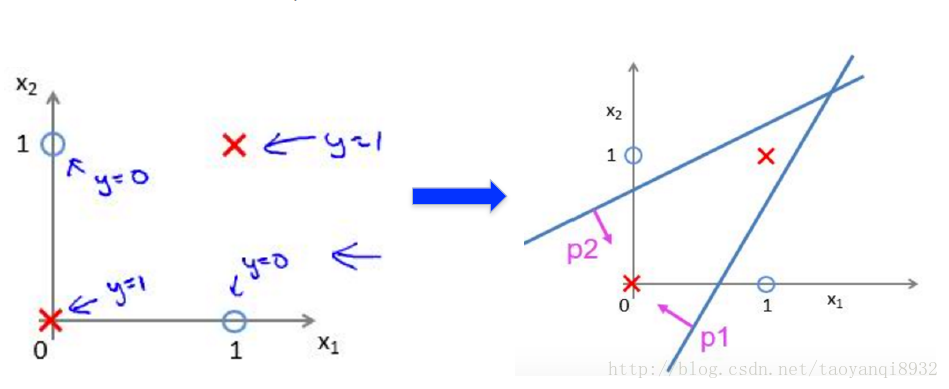
如下图所示,一个异或问题,单纯的用感知机是不能解决的,因为在平面中我们找不到一条直线将其区分,但是我们可以组合两个感知机,然后去他们的交集,从而可以完美的解决这个问题。
神经网络过拟合问题
神经网络的表达能力是非常强大的,只有给予足够多的神经元,通常其都面临着过拟合的问题。

因此,过多的隐含层和神经元的节点,会带来过拟合的问题。同常来说不应该通过降低神经网络的参数量来减少过拟合,可以用正则化项对其进行惩罚或者时通过dropout进行一部分神经元的随机失活。
神经网络BP算法
反向传播算法(Back Propagation)分二步进行,即正向传播和反向传播。这两个过程简述如下:
1.正向传播
输入的样本从输入层经过隐单元一层一层进行处理,传向输出层;在逐层处理的过程中。在输出层把当前输出和期望输出进行比较,如果现行输出不等于期望输出,则进入反向传播过程。
2.反向传播
反向传播时,把误差信号按原来正向传播的通路反向传回,逐层修改连接权值,以望代价函数趋向最小。
误差推导过程:


算法过程如下:

来源:机器学习
标准BP算法,累计BP算法
从上述的推导计算法可以看出其实基于一个训练要本给出的更新权值的过程,其被称为标准bp算法,如果类似的基于累积误差最小化的更新原则,得到的是累积的更新算法,即累积BP算法。
一般来说,标准的BP算法每次更新只针对于单个样例,参数更新较为频繁,同时他还有可能出现对不同样例更新出现“抵消”现象,因此其往往需要更多次数的迭代,累积BP算法直接针对累积误差最小化,它将完整训练集读取一遍后才进行参数的更新,其参数频率更新的低得多,但是其累积误差下降到一定的程序后,进一步的下降会非常的缓慢,这是标准BP往往会更快得到较好的解,尤其是在训练集较大的时候。
人工神经网络的特点


来源:数据挖掘导论
参考资料
1.《统计学习方法》 李航
2.《机器学习》 周志华
3. 《数据挖掘导论》Pang-Ning Tan
4. 部分图片来源七月在线的视频















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









