







 Fast R-CNN由Ross Girshick提出,它将特征提取、分类和边界框回归集成到一个框架中,提高了目标检测的效率。通过RoI池化层和多任务损失函数,实现了端到端的训练。网络结构包含AlexNet或VGGNet作为基础,使用RoI pooling层处理不同大小的候选区域,并采用层次抽样和数据增强进行训练。Fast R-CNN解决了尺度不变问题,且通过SVD压缩全连接层,加速了运算速度。
Fast R-CNN由Ross Girshick提出,它将特征提取、分类和边界框回归集成到一个框架中,提高了目标检测的效率。通过RoI池化层和多任务损失函数,实现了端到端的训练。网络结构包含AlexNet或VGGNet作为基础,使用RoI pooling层处理不同大小的候选区域,并采用层次抽样和数据增强进行训练。Fast R-CNN解决了尺度不变问题,且通过SVD压缩全连接层,加速了运算速度。
《Fast R-CNN》论文解读
本文作者是Ross Girshick,和R-CNN作者一样。
概述
前面提到端到端的检测框架是很难实现的,那么先把除了region proposal的部分统一起来。Fast R-CNN贡献就在于把特征提取,SVM,Bounding box regression统一到一个框架里面了。
Fast R-CNN
先说点题外话,如何阅读一篇论文?对于深度学习方面的论文,我觉得要关注以下几个问题:1、网络结构是什么样子的,也就是说前向传播的路径是什么样的;2、如何进行训练,包括训练的样本是什么,使用了什么样的训练方法,如何选择超参数。对于一些细枝末节的问题,如果不打算重现的话也没有必要深入去研究。从这个角度来说,网上很多的资料质量实在不怎么样,写的没有条理。回到本文来看,我从我的角度给出这篇论文的解读。
网络结构
在Fast R-CNN中,候选区域生成(region proposal)仍然是独立于系统的,本文的贡献在于将特征提取、目标分类、边框回归统一到了一个框架下面。
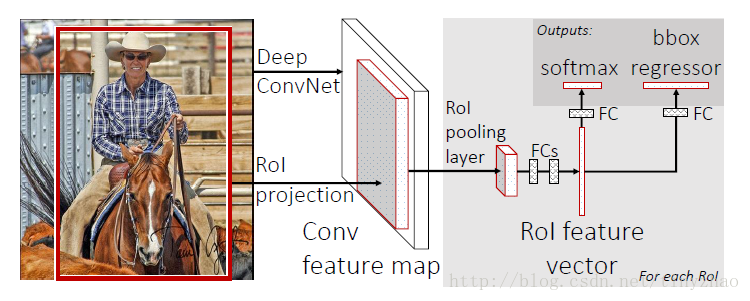
这个网络的输入是原始图片和候选区域RoI位置,输出是分类类别和bbox回归值。将原始图片输入到网络中,在网络的最后一个卷积层根据RoI位置获得对应RoI的特征图,然后输入到Roi pooling layer,可以得到一个固定大小的特征图。将这个特征图经过2个全连接层以后得到RoI的特征,然后将特征经过全连接层,使用softmax得到分类,使用回归得到边框回归。CNN的主体结构可以来自于AlexNet,也可以来自于VGGNet。
这里唯一需要解释的就是RoI pooling layer。如果特征图上的RoI大小是 h∗w ,将这个特征图划分为 h/H∗w/W 个网格,每个网格做max pooling,这样得到pooling以后的大小就是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









