







 本文介绍了Eulerian Video Magnification (EVM)算法的Python实现,包括论文解读、算法流程和具体步骤,如Spatial Decomposition、Temporal Filter和Reconstruction。EVM算法能放大视频中的微小变化,适用于心率检测等场景。文章提供了使用OpenCV3进行视频处理的代码示例,并展示了色彩和运动放大的结果。
本文介绍了Eulerian Video Magnification (EVM)算法的Python实现,包括论文解读、算法流程和具体步骤,如Spatial Decomposition、Temporal Filter和Reconstruction。EVM算法能放大视频中的微小变化,适用于心率检测等场景。文章提供了使用OpenCV3进行视频处理的代码示例,并展示了色彩和运动放大的结果。
EVM算法的实现
EVM(Eulerian Video Magnification,欧拉视频放大或欧拉影像放大)是一种将视频中的微小变化进行放大的算法,正如论文标题所说《Eulerian Video Magnification for Revealing Subtle Changes in the World》,该算法可以将视频中的微小变化转变为肉眼可以观察的变化。这个算法可以应用在从视频中提取心率信息,也可以放大视频中细小的运动变化。
1 论文解读
这篇论文的方法非常简单,如论文中图二所示:
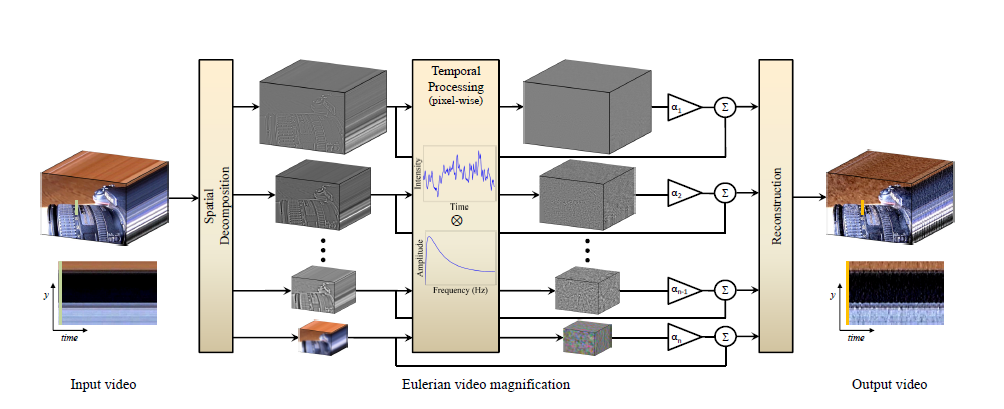
左侧输入的是原始视频,视频首先经过Spatial Decomposition,随后进行Temporal Filter,最后再将视频进行Reconstraction。下面,本文将具体介绍每一步的做法。
1.1 欧拉视角和拉格朗日视角
Because the two methods take different approaches to motion—Lagrangian approaches explicitly track motions, while our Eulerian approach does not—they can be used for complementary motion domains.
概括一下,拉格朗日视角是将运动精确到物体本身,比如要研究视频中某个物体的运动,我们就需要首先检测到这个物体,随后使用跟踪算法进行跟踪。这样做的一个问题是,难以准确找到运动的像素,优点是可以使用更大的放大系数。欧拉视角认为,局部的运动可以从整体的观察中获得。比如,要检测视频中吉他琴弦的震动,拉格朗日视角是先找到运动的琴弦,然后跟踪。而欧拉视角是从视频整体出发,在吉他视频中通过恰当方法提取到琴弦运动的信息,而不去关注琴弦在哪里,琴弦的运动信息隐藏在连续的视频之中。欧拉方法更适合观察小的变化。
1.2 算法流程
从原文的描述来看,这篇论文中提到的方法非常简单。
Spatial Decomposition
就是将视频中的每一帧进行下采样,形成图像金字塔。这里图像金字塔有两种组件方式,一种是高斯金字塔,还有一种是拉普拉斯金字塔。高斯金字塔常常用于放大色彩,而拉普拉斯金字塔用于放大运动。
Temporal Filter
视频可以看做连续的图片,从图片中的单个像素点的角度看,视频每个像素点的变化可以看成时域信号。而物体运动的信息就隐藏在单个像素点的变化之中。论文采用的方法是进行带通滤波(bandpass filter),放大颜色的时候采用理想带通滤波器,放大运动的时候采用IIR滤波器,论文中主要使用了巴特沃斯滤波器(Butterworth filter)。
Reconstraction
最后一步流程就是将分解成图像金字塔的图片再复原回去。这篇论文中,高斯金字塔的复原方法是将高斯金字塔中最低一级(图片最小的那张)进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









