







 本文介绍了决策树的基本原理,包括信息熵、信息增益的概念,用于特征选择。接着详细阐述了决策树的生成、剪枝过程以及正则化的学习损失函数。此外,还探讨了随机森林的构建方法,强调了随机森林通过行、列采样和完全分裂避免过拟合,以及其诸多优点。
本文介绍了决策树的基本原理,包括信息熵、信息增益的概念,用于特征选择。接着详细阐述了决策树的生成、剪枝过程以及正则化的学习损失函数。此外,还探讨了随机森林的构建方法,强调了随机森林通过行、列采样和完全分裂避免过拟合,以及其诸多优点。
决策树是一种判别式模型。在一颗分类决策树中,非叶子节点时决策规则,叶子节点是类别。当输入一个特征向量时,按照决策树上的规则从根节点向叶节点移动,最后根据叶节点的类别判定输入向量的类别。决策树也可以用来解决回归问题。
建立一个决策树模型主要有三个步骤:特征选择、决策树的生成、决策树的剪枝。而特征选择时要用到信息增益这个概念。
特征选择:
对于一个随机变量X,它的熵可以表示为:
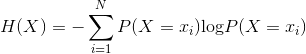
对于两个随机变量X、Y,在已知X的情况下,Y的条件熵为:
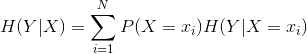
其中,
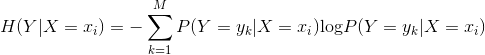
而信息增益(IG)或互信息(MI)的定义是:
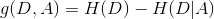
也就是说在已知A的情况下随机变量D的不确定性的减少程度,也就是在我们知道A的情况下获得了多少信息。
如果D是数据类别的随机变量,而A是数据某个特征的随机变量,可以想见使得信息增益最大的特征是最好的特征。因为这个特征可以最大程度上减少我们对类别的不确定性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









