








在使用朴素贝叶斯(NB)对文档进行分类时,会使用到文档的生成模型,为什么呢?还是从贝叶斯公式出发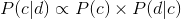
多元贝努利分布模拟文档生成:
现在假设词汇表是V,它包含M个词,那么使用多元贝努利模型生成一篇文档可以看作是这样的一个过程:
从头至尾遍历一遍词汇表,并指定某个词tk是否在文档d的中出现,这样就生成了一篇文档!
这样一个过程生成一篇文档其实是相当粗糙的,准确的说它其实只是指定了该文档中包含词汇表中的哪些单词而已。
可以看出该模型忽略了词项出现的次数、词项出现的位置和词项之间的相关性(NB的特性)。
所以一篇文档可以表示为一个bool向量,即:
该模型需要估计的参数为
决策规则:最大化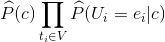
注意:这个决策函数跟多元贝努利有一些区别,即它没有考虑词不出现的情况,可以看出当对同一篇文档进行分类时,这个值是没有必要计算的。
多项式分布模拟文档生成:
使用多项式模型生成一篇文档可以看作是这样一个过程:
假设你有一个骰子,每个面是一个词项,当然每个面出现的概率是不一样的,同时对于不同的类别,骰子也是不一样的,即各个面的概率分布不同。
然后对于一篇文档d的每个位置,你就掷骰子就可以了。它会以一定概率产生一个词项,最终所有词项组成一篇文档!
可以看出使用多项式分布生成一篇文档相比于使用多元贝努利生成一篇文档好像不那么粗糙了,因为:
该模型忽略了不同位置的差异性和词项之间的相关性(NB的特性)。即某个词项t出现在位置a和出现在位置b是没有区别的(词袋模型)!
多项式模型对词项出现的次数进行了建模!
所以一篇文档可以看作是一系列词项组成的向量
该模型需要估计的参数为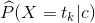
决策规则:最大化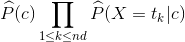
注意:这个决策函数与多项式分布也有一些不同,即省略了系数,因为对于同一篇文档,该系数是常数。
多元贝努利vs多项式:
那么问题来了,这两个模型哪个好呢?肯定是个有所长了!
1. 贝努利模型不考虑词项出现的次数,而多项式模型考虑;
2. 贝努利模型适合处理短文档,而多项式模型适合处理长文档;
3. 贝努利模型在特征数较少时效果更好,而多项式模型在特征较多时效果更好;
4. 多于词项“the”的估计:
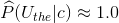
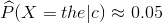
第4条可以明显感觉两个模型的不同,也很好理解:对于词项“the”,几乎每篇文档都出现,所以在多元贝努利模型中它的概率接近1。而在多项式模型中“the”只是骰子的一面!其出现的概率很大,但是也只有0.05!

















 4344
4344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









