







引言
前面已经介绍过RNN的基本结构,最基本的RNN在传统的BP神经网络上,增加了时序信息,也使得神经网络不再局限于固定维度的输入和输出这个束缚,但是从RNN的BPTT推导过程中,可以看到,传统RNN在求解梯度的过程中对long-term会产生梯度消失或者梯度爆炸的现象,这个在这篇文章中已经介绍了原因,对于此,在1997年
的Grave大作[1]中提出了新的新的RNN结构:Long Short Term Dependency。LSTM在传统RNN的基础上加了许多的“门”,如input gate、forget gate、output gate等,因为这些门的引入,使得LSTM在BPTT的过程中避免了梯度爆炸或者消失的缺点,主要原因是LSTM在链式求导过程中从原来RNN的连乘改进到了连加。介绍LSTM的比较详细的博文见[2],关于LSTM的推导可以参看[3],或者看博文[4] GRU(Gated Rucurrent Unit)是2014年年首先被应用[5].GRU和LSTM差不多,不过是“门”不同罢了,基本思想差不多。关于GRU和LSTM孰好孰坏这个问题,也没有明确的答案,在不同的数据集上双方各有优劣吧。另外LSTM在这么多年的进展过程中,产生了很多的变体,这里不一而足,只是希望读者在看到不同的LSTM网络之后不要惊呼跟之前看到的LSTM网络结构不一样。PS:一入机器学习深似海,从此时间似路人…
语言模型
语言模型在NLP领域中有着重要的应用,传统的N-Gram语言模型虽然在一些方法中得到了应用,但是N-Gram存在着计算复杂度大且只能学习到N个word的上下文,对长序列文本建模效果并不好。神经网络语言模型(Neutral NetWork Language Model)最早在[6]被提出,从此神经网络语言模型呈星火燎原之势,在NLP领域大展身手,尤其是在机器翻译领域。后来RNN神经语言模型被提出来,RNN能够学习序列的特征被应用到语言建模中,而其中以LSTM和GRU应用的最为广泛,本文着重就对LSTM为基本结构来对语言进行建模。
LSTM语言模型构建
如果对LSTM不熟悉的话可以先看看[2],LSTM的变体很多,光[2]里面提到的就有好几个,但是对于选用什么结构的LSTM,因为没有实验依据,所以我就是随便选一个进行实验,本次实验选取的LSTM的单元cell结构如下:
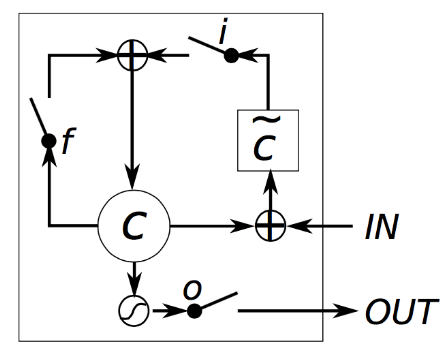
而根据上面的LSTM单元结构,其计算公式如下:
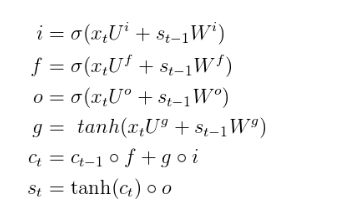
然后我们回到语言建模上,明确LSTM的输入输出。
所谓语言建模,也就是在给定一个单词序列之后,预测下一个词产生的概率,比如在进行训练之后,给定一句话”I Love“,那么这句话下个词的概率分布可能是[“you”:0.6, “China”:0.05, “Food”:0.1 ,”NewYork”:0.05, “Mom”:0.1, “game”:0.1] (当然这是一个假设)。根据概率分布,那么这句话下个词很可能是“You”。了解到这点之后就可以进一步明白LSTM的输入输出了。
假设现有的词表大小vocab_size是2000个,将每句话的前面加上特殊的单词“SENTENCE_START_TOKEN”以及在结尾加上”SENTENCE_END_TOKEN”,然后将句子的每个单词转换成词向量,也就是word embedding,我们可以得到下面的输入输出:
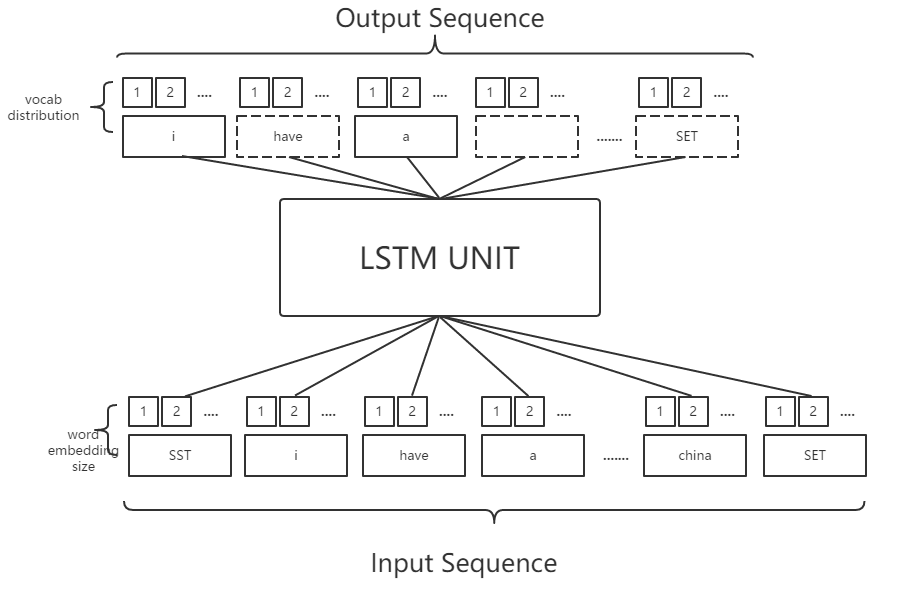
注:SST为SENTENCE_START_TOKEN
SET为SENTENCE_END_TOKEN
从上面的图中可以看出,输入序列中,每个单词都做了word_embedding,也就是转换成了向量,这个过程可以随机初始化,亦可以使用Google的word2vec这个开源工具进行提前训练。转换成词向量之后,经过LSTM运算,以”i”这个词为例,得到的是i的下一个词的分布情况,如果正确的话,其词分布应该是“have”这个词的概率最高。我们亦可以知道输出层的维度应该是词表的维度。
明白了这个就很好理解了下面的程序代码了。
实验
实验基于博文[7]稍加改进的,需要说明的是,原文中使用的是GRU结构,我改成了LSTM结构。
实验数据:15000条 Google’s BigQuery数据集上的Reddit Comment
实验系统:windows7
语言:python
工具:theano等
GPU型号:GT720
LSTM主要代码:
# -*- coding:utf-8 -*-
import numpy as np
import theano
import theano.tensor as T
import operator
import time
class LSTM_Theano:
def __init__(self, word_dim, hidden_dim=128, bptt_truncate=-1):
#初始化参数
self.word_dim=word_dim
self.hidden_dim=hidden_dim
self.bptt_truncate=bptt_truncate
E=np.random.uniform(-np.sqrt(1./word_dim), np.sqrt(1./word_dim), (hidden_dim, word_dim))
U = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (4, hidden_dim, hidden_dim))
W = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (4, hidden_dim, hidden_dim))
V = np.ra 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









