




引言
学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用tensorflow实现了一下,感觉和之前使用的theano还是有很大的区别,有必要总结mark一下
模型说明
这个分类的模型其实也是很简单,主要就是一个单层的LSTM模型,当然也可以实现多层的模型,多层的模型使用Tensorflow尤其简单,下面是这个模型的图
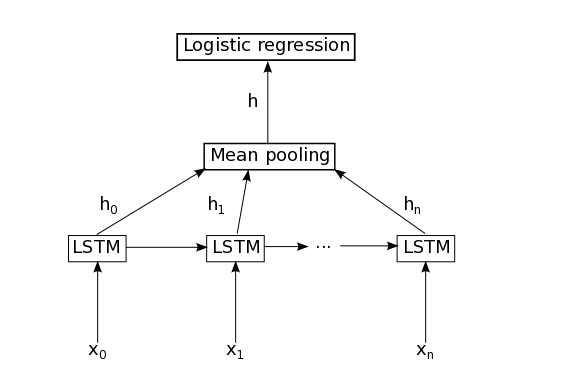
简单解释一下这个图,每个word经过embedding之后,进入LSTM层,这里LSTM是标准的LSTM,然后经过一个时间序列得到的t个隐藏LSTM神经单元的向量,这些向量经过mean pooling层之后,可以得到一个向量 h ,然后紧接着是一个简单的逻辑斯蒂回归层(或者一个softmax层)得到一个类别分布向量。
公式就不一一介绍了,因为这个实验是使用了Tensorflow重现了Theano的实现,因此具体的公式可以参看LSTM Networks for Sentiment Analysis这个链接。
tensorflow实现
鄙人接触tensor flow的时间不长,也是在慢慢摸索,但是因为有之前使用Theano的经验,对于符号化编程也不算陌生,因此上手Tensorflow倒也容易。但是感觉tensorflow还是和theano有着很多不一样的地方,这里也会提及一下。
代码的模型的主要如下:
import tensorflow as tf
import numpy as np
class RNN_Model(object):
def __init__(self,config,is_training=True):
self.keep_prob=config.keep_prob
self.batch_size=tf.Variable(0,dtype=tf.int32,trainable=False)
num_step=config.num_step
self.input_data=tf.placeholder(tf.int32,[None,num_step])
self.target = tf.placeholder(tf.int64,[None])
self.mask_x = tf.placeholder(tf.float32,[num_step,None])
class_num=config.class_num
hidden_neural_size=config.hidden_neural_size
vocabulary_size=config.vocabulary_size
embed_dim=config.embed_dim
hidden_layer_num=config.hidden_layer_num
self.new_batch_size = tf.placeholder(tf.int32,shape=[],name="new_batch_size")
self._batch_size_update = tf.assign(self.batch_size,self.new_batch_size)
#build LSTM network
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_neural_size,forget_bias=0.0,state_is_tuple=True)
if self.keep</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 7799
7799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









