







 本文探讨了跨模态搜索的方法,实现了PAMI2016和arxiv.org 2017.2上的两篇论文。主要目标是将图片和文本特征映射到同一子空间,通过凸优化处理目标函数,确保优化过程的稳定性。实验在Windows环境下使用MATLAB2016a进行,以MAP作为评估标准,结果显示与原始论文结果一致,证明了方法的有效性。
本文探讨了跨模态搜索的方法,实现了PAMI2016和arxiv.org 2017.2上的两篇论文。主要目标是将图片和文本特征映射到同一子空间,通过凸优化处理目标函数,确保优化过程的稳定性。实验在Windows环境下使用MATLAB2016a进行,以MAP作为评估标准,结果显示与原始论文结果一致,证明了方法的有效性。
1、实验基本信息
跨模态搜索研究的基本内容是寻找不同模态样本之间的关系,实现利用某一种模态样本,搜索近似语义的其他模态样本。
2.1 论文《Joint Feature Selection and SubspaceLearning for Cross-Modal Retrieval》(JFSSL)(PAMI2016)
代码连接:https://github.com/2012013382/JFSSL-Cross-Modal-Retrieval
此论文是对于论文《Spectral Regression for Efficient Regularized Subspace Learning》(ICCV2007)和论文《L21Regularized Correntropy for Robust Feature Selection》的结合。其主要的目的是为了最优化目标函数(1)。
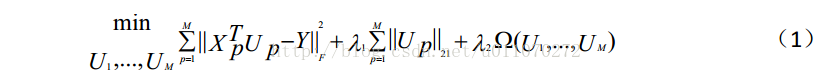
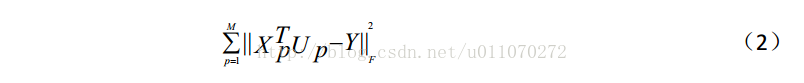
如公式(2)所示,它的形式是一个基本的均方误差,最小化这个均方误差,便可以使得映射矩阵朝着理想的方向变化。
公式( 1) 的第二项为一个 L2,1 范数约束项,
跨模态搜索研究的基本内容是寻找不同模态样本之间的关系,实现利用某一种模态样本,搜索近似语义的其他模态样本。
本文实现了论文《Joint Feature Selection and Subspace Learning for Cross-Modal Retrieval》(PAMI2016)和论文《Simple to Complex Cross-modal Learning to Rank》(arxiv.org 2017.2)。并对实现的结果进行了一些讨论。
2.1 论文《Joint Feature Selection and SubspaceLearning for Cross-Modal Retrieval》(JFSSL)(PAMI2016)
代码连接:https://github.com/2012013382/JFSSL-Cross-Modal-Retrieval
此论文是对于论文《Spectral Regression for Efficient Regularized Subspace Learning》(ICCV2007)和论文《L21Regularized Correntropy for Robust Feature Selection》的结合。其主要的目的是为了最优化目标函数(1)。
其中,M为模态的类别数,在此,我们只考虑图片和文本之间互相搜索的情况,因此M=2;Up表示对应模态的映射矩阵;Xp表示输入的训练样本;Y表示样本的标签;第三项为模态间/模态内相似度函数;lambda1和lambda2为两个设定的阈值。
最优化这个目标函数的目的就是为了得到映射矩阵Up。通过映射矩阵,便可以将不同模态的特征数据映射到相同的子空间中,再通过cosine相似度度量,即可得到不同模态数据之间的相似度。
如公式(2)所示,它的形式是一个基本的均方误差,最小化这个均方误差,便可以使得映射矩阵朝着理想的方向变化。
公式( 1) 的第二项为一个 L2,1 范数约束项,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3202
3202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









