







本文为学习总结,主要参考PRML[1]和cnblogs[2]上的那篇博客。
线性判别式分析,又称为Fisher线性判别。
二分类情况
假设有一个D维输入向量x,然后用下式投影到一维空间
对y设置一个阈值Thre,然后把y大于Thre的归为1类,把其余的归为2类这样就是得到一个标准的线性分类器。一般地,向一维投影会造成很多信息丢失,因此在原本D维空间能完美分离的样本可能在一维空间中互相重叠。但是,通过过调整权重向量 w ,可以选择让类别之间区分最大的一个投影。在二分类情况下,设1类有
如果投影w上,最简单的度量类别之间分开程度的方式就是类别均值向量投影之后的距离。可以选择w使式子 m2−m1=wT(m2−m1) 取得最大值(等号左边的是均值向量投影后的值),其中 mk=wTmk 表示类别 Ck 的投影数据的均值。求解这个最大化问题,需将w限制为单位长度,即 ∑iw2i=1 。然后使用拉格朗日乘数法来进行求解。但是投影存在一定的重叠现象,如下图。
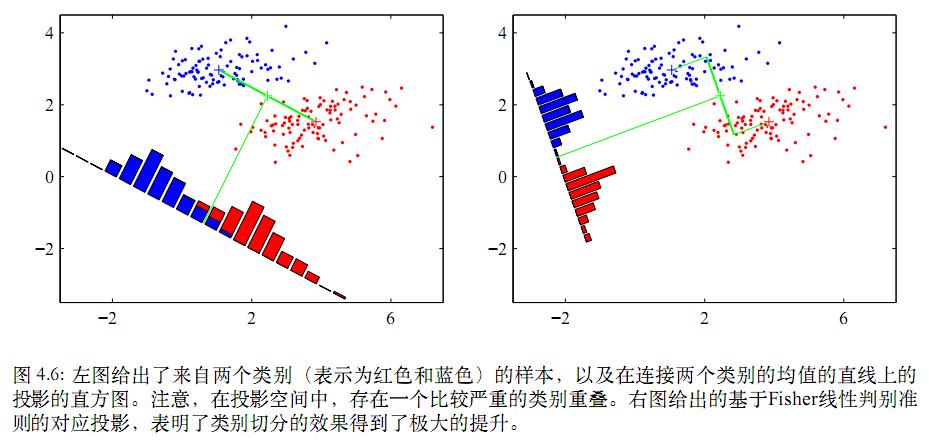
LDA的思想是最大化一个函数使类间均值的投影分得很开,同时让类内方差小,最小化类间重叠。
类内方差: s2k=∑n∈Ck(yn−mk)2 ,其中 yn=wTxn 是第n个样本投影后的值。整个数据集的总类内方差定义为 s21+s22 。
Fisher准则根据类间方差和类内方差的比值定义,即
将 y=wTx , mk=wTmk , s2k=∑n∈Ck(yn−mk)2 代入上式子,可以将 J(w) 重写为:
(m2−m1)2=(wTm2−wTm1)2=wT(m2−m1)(m2−m1)T=wTSBw
SB=(m2−m1)(m2−m1)T 是类间(between-class)协方差矩阵,是两个向量的外积,虽未矩阵,但秩为1;
SW=∑n∈C1(xn−m1)(xn−m1)T+∑n∈C2(xn−m2)(xn−m2)T 是类内(within-class)协方差矩阵;
在求导之前,需要对分母进行归一化,令|| wTSWw ||=1,加入拉格朗日乘子后,关于w求导:
c(w)=wTSBw−λ(wTSWw)⇒dcdw=2SBw−2λSWw=0⇒SBw=λSWw
这里用来矩阵微积分,求导时把 wTSBw 看成 SBw2 。
如果 SW 可逆,上面结果两边同时乘以 S−1W ,得
从上式可知,w就是矩阵 S−1WSB 的特征向量
令 SBw=(m2−m1)(m2−m1)Tw=(m2−m1)∗λw
则 S−1WSBw=S−1W(m2−m1)∗λw=λw
由于对w缩放大小不影响结果,因此可以约去两边的未知常数 λw 和 λ ,得到
这个结果就是Fisher线性判别函数,严格来说只是对于数据向一维投影的方向的一个具体选择而已。投影的数据可以接下来被用于构建判别函数。
多分类情况
假设输入样本数据的维度D大于类别数K。然后引入D’>1个线性”特征”
yk=wTkx
,其中k=1,…,D’。将这些特征组成向量y。权重向量
wk
也构成矩阵W的每一列,得到
类内协方差矩阵推广到K类,有
其中
为了找到类间协方差矩阵的推广,先求整体的协方差矩阵
m为全体数据的均值 m=1N∑Nn=1xn=1N∑Kn=1Nkmk
整体的协方差矩阵可以分解为之前给的类内协方差矩阵再加上另一个矩阵 SB ,它可以看成类间协方差矩阵。
其中
以上是定义在原始的x空间中。现在在投影到D’维的y空间中定义类似的矩阵:
其中
SW=WTsWW,SB=WTsBW
W是基向量矩阵,
问题又回到求 J(W) 的最大值上,得到结论 s−1WsBwi=λwi
最终本质问题还是求矩阵的特征值,首先求出 s−1WsB 的特征值,然后取前K个特征向量组成W矩阵。
SB
中的
(mk−m)
秩为1,因为矩阵的秩小于等于各个相加矩阵的秩之和,所以
SB
的秩至多为K。知道前K-1个
mk
之后,最后一个
mK
可以用前面的
mk
来线性表示,所以S_B的秩最多为K-1。LDA的使用有限制,至多可生成K-1维子空间,不适合对非高斯分布样本进行降维,样本分类信息依赖方差而不是均值时,效果不好。
S−1WSB
不一定是对称阵,得到的D’个特征向量不一定正交,这与PCA不同。PCA 是无监督的,它所做的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息用主要的特征代替其他相关的非主要的特征,所有特征之间的相关度越高越好。 但是分类任务的特征可能是相互独立的,LDA是有监督的,使得类别内的点距离越近越好(集中),类别间的点越远越好[5]。
原文链接http://blog.csdn.net/u011285477/article/details/51086285
参考资料:
[1]Pattern Recognition and Machine Learning(PRML)
[2]http://www.cnblogs.com/jerrylead/archive/2011/04/21/2024384.html
[3]http://blog.csdn.net/yihaizhiyan/article/details/7579506
[4]http://blog.csdn.net/warmyellow/article/details/5454943
[5]http://blog.csdn.net/jojozhangju/article/details/19652453?utm_source=tuicool&utm_medium=referral















 8809
8809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









