







 本文介绍了机器学习中的 Bagging 和 Boosting 方法,重点讲解了 GBDT 和 RF 模型。接着探讨了特征值分解、奇异值分解及PCA,最后讨论了 L1 范式和 L2 范式在正则化中的作用,强调了它们在特征选择和防止过拟合中的重要性。
本文介绍了机器学习中的 Bagging 和 Boosting 方法,重点讲解了 GBDT 和 RF 模型。接着探讨了特征值分解、奇异值分解及PCA,最后讨论了 L1 范式和 L2 范式在正则化中的作用,强调了它们在特征选择和防止过拟合中的重要性。
baging和boosting
baging是从原始数据集选择S次后得到S个新数据集的一种技术,新数据集和原始数据集大小相等,这些数据集都是通过原始数据集中随机选择一个样本,然后随机选择一个样本来替换这个样本(放回抽样)。这一性质允许新数据集中又可以重复的值,而原始数据中的某些值在新数据集中不再出现。
S个数据集建立好之后,将某个学习算法分别作用于每个数据集中就得到了S个分类器,当我们要对新数据进行分类时,就可以应用这S个分类器进行分类投票。
boosting方法与bagging方法相似,但是bagging所有权重都一样,boosting方法的分类器是串行训练的,每个新的分类器是根据已经训练出的分类器的性能来进行训练,降低成功的权重,提高失败的权重。
GBDT
Gradient Boost Decision Tree,Boosting是提升的意思,每一次新的训练都是为了改进上一次的结果。迭代的思想。在Gradient Boosting中,每一次计算都是为了减少上一次的残差,而为了消除残差,我们可以在残差减少的梯度方向上建立新的模型,所以,GBDT中,新的模型建立是为了使得之前模型的残差往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
RF
Random Forest,随机方式建立一个森林,由许多决策树组成,随机森林的每棵树之间是没有关联的,当有一个新的输入样本进入时,就让随机森林中的每一棵树进行一下判断,看看这个样本属于哪一类,然后看哪一类投票比较多,则预测这个样本属于哪一类。
特征值分解
如果一个向量V是方阵A的特征向量,可以表示成下面的形式:
Av=λv
这时候 λ 就是特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:
A=Q∑Q−1
其中Q是这个矩阵A的特征向量组成的矩阵, ∑ 是一个对角阵,每一个对角线上的元素就是一个特征值,由大到小排列,这些特征值所对应的特征向量就是描述这个矩阵变换的方向。
特征值分解可以得到特征值和特征向量,特征值表示这个特征有多重要,而特征向量表示这个特征是什么,可以将每个特征向量理解为一个线性的子空间。
特征值分解的局限:变换的矩阵必须是方阵。
奇异值分解
奇异值分解是一个能适应于任意矩阵的分解方法:
A=U∑VT
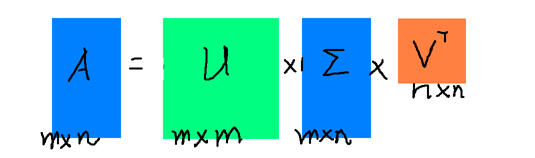
矩阵 ∑ 的对角线元素即为奇异值,也是由大到小排列,而且减少得特别快,在很多情况下,前10%甚至是1%的奇异值的和就占了全部奇异值之和的99%以上了,所以,可以用以下的公式来近似奇异值分解:
Am∗n≈Um∗r∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









