







打开一些神经网络的网络描述文件,可以看到不同的层,其中就有一种层的类型,叫做ReLU。今天正好有小伙伴问起,虽然是基础部分但是还是来总结一下吧。首先看网络结构描述的形式:
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 96
pad: 3
kernel_size: 7
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}这里截取Faster R-CNN的模型文件一小部分,可以看到,在卷积层后面紧接着是一个ReLU层,主要定义了name,type,bottom,top,其属于非线性激活函数的一种,同类型的函数还有sigmoid函数,tanh函数,softplus函数等等。对于ReLU函数,其公式即为个ReLU(x)=max(0, x),而sigmoid函数为sigmoid(x)= 1/(1+e^-x),而Softplus(x)=log(1+ex)。有一个经典的4种函数图形表示如下:
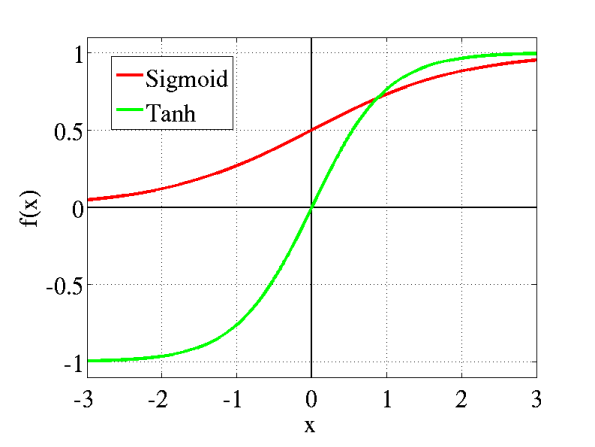
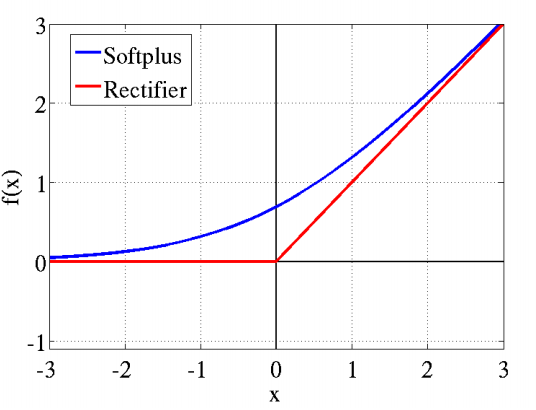
从图形可以看出,后图中的ReLU与softplus函数与前图中的传统sigmoid系激活函数相比,主要变化有三点:①单侧抑制 ②相对宽阔的兴奋边界 ③稀疏激活性(重点,可以看到红框里前端状态完全没有激活)。
那么为什么现在这么多网络都更多地使用ReLU函数呢?
一个重要原因就是上面提到的,其稀疏激活性。
标准的sigmoid函数输出不具备稀疏性,需要用一些惩罚因子来训练出一大堆接近0的冗余数据来,从而产生稀疏数据,例如L1、L1/L2或Student-t作惩罚因子。因此需要进行无监督的预训练。
而ReLU是线性修正,是purelin的折线版。它的作用是如果计算出的值小于0,就让它等于0,否则保持原来的值不变。这是一种简单粗暴地强制某些数据为0的方法,然而经实践证明,训练后的网络完全具备适度的稀疏性。而且训练后的可视化效果和传统方式预训练出的效果很相似,这也说明了ReLU具备引导适度稀疏的能力。
因此,ReLu的使用,使得网络可以自行引入稀疏性,同时大大地提高了训练速度。下面贴出一些不同函数下的训练结果对比数据:
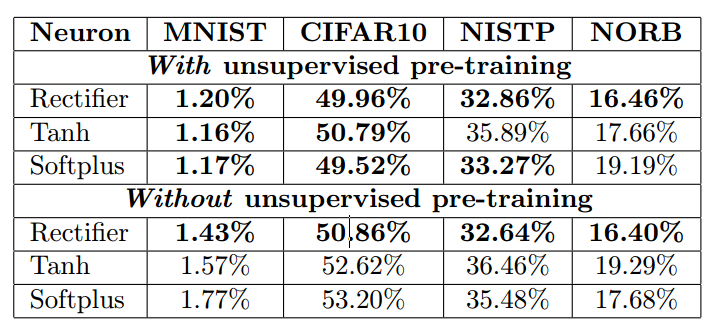
ReLU因而在深度网络中已逐渐取代sigmoid而成为主流。














 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









