







使用caffe主要分为三大步:
【1】用convert_imageset.exe把图片数据库转换为.lmdb或者.leveldb的格式。
【2】用compute_image_mean.exe进行取均值的预处理,生成.binaryproto文件
【3】用caffe.exe跑CNN。
1)数据准备
下载的一个比较小的ImageNet图片数据集,共120种,每种不到200张。
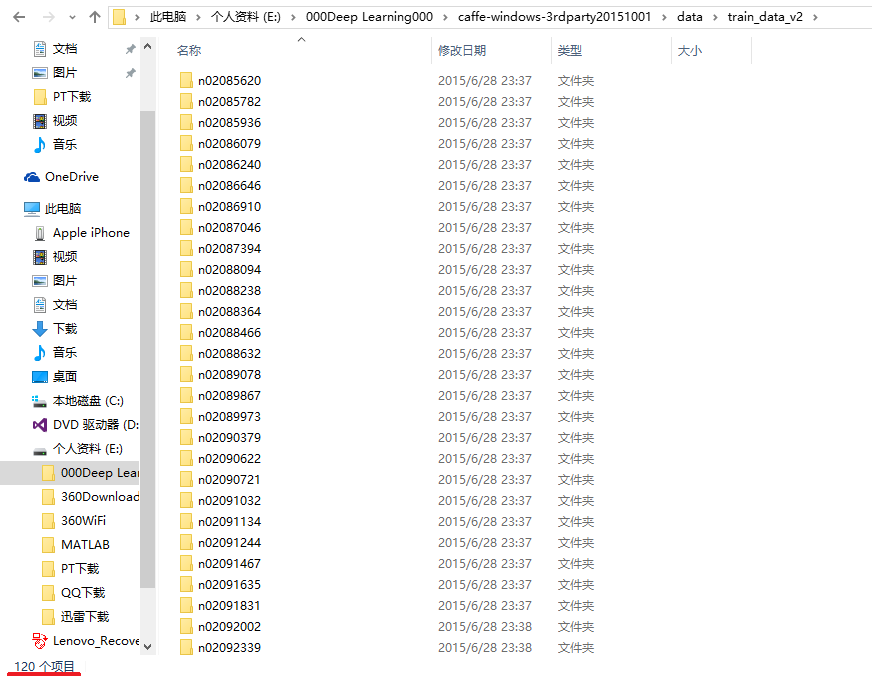
2)生成train.txt文件
对于train.txt文件的格式,网上有明确的介绍。
来自:http://blog.csdn.net/u012878523/article/details/41698209
是这样的格式:
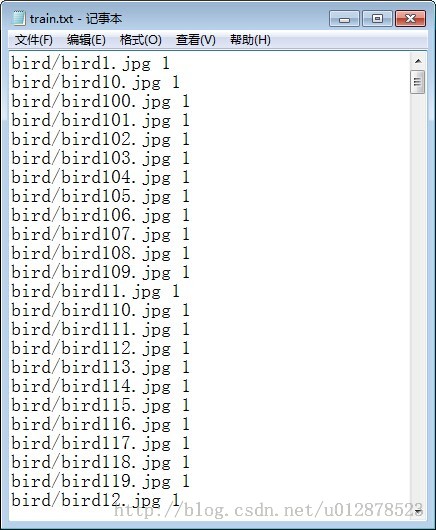
我自己写了一个matlab的小程序,直接生成train.txt文件:
clear all
clc
foodDir='E:\000Deep Learning000\caffe-windows-3rdparty20151001\data\train_data_v2';
numClasses=10;
classes=dir(foodDir);
classes = classes([classes.isdir]) ;
classes = {classes(3:numClasses+2).name};
imageName={};
fp = fopen('train.txt','a');
for ci = 1:length(classes)
ims = dir(fullfile(foodDir, classes{ci}, '*.jpg'))' ;
for ii=1:length(ims)
fprintf(fp,classes{ci});
fprintf(fp,'/');
fprintf(fp,ims(ii).name);
fprintf(fp,' ');
fprintf(fp,'%d',ci);
fprintf(fp,'\r\n');
end
end
fclose(fp);
下面开始使用caffe:
【1】用convert_imageset.exe把图片数据库转换为.lmdb或者.leveldb的格式。
网上流传的大多是Linux的shell命令,我仿着caffe自带的example里面的imagenet的shell文件写了一个批处理命令,可以直接用的。
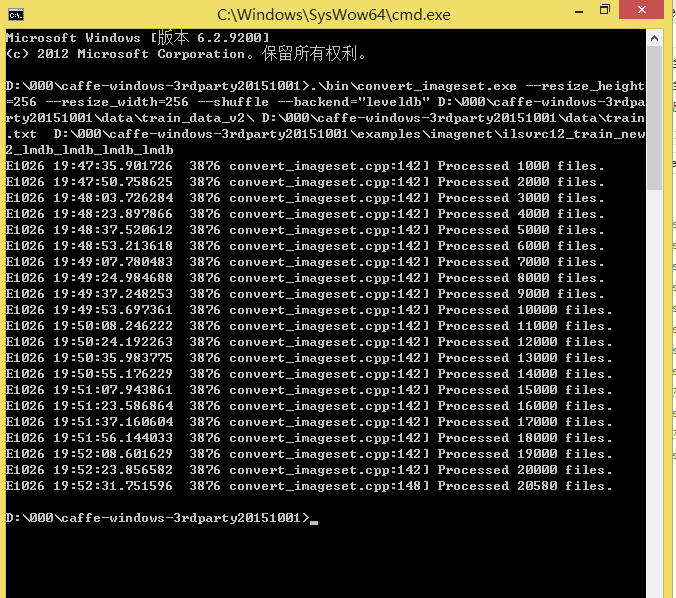
.\bin\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend="leveldb" D:\000\caffe-windows-3rdparty20151001\data\train_data_v2\ D:\000\caffe-windows-3rdparty20151001\data\train.txt D:\000\caffe-windows-3rdparty20151001\examples\imagenet\ilsvrc12_train_new2_lmdb_lmdb_lmdb_lmdb
注意这里的backend用是leveldb,默认的是lmdb。
如果这里生成的是leveldb文件,后面预处理 计算均值图像的时候也要用leveldb。我一开始生成的是lmdb文件,结果后面运行compute_image_mean的时候报错:
set end of file error
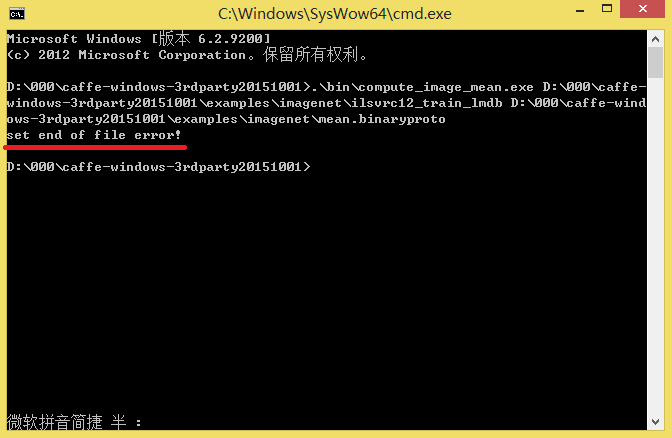
后来改成leveldb,一切正常。
这是lmdb

这是leveldb
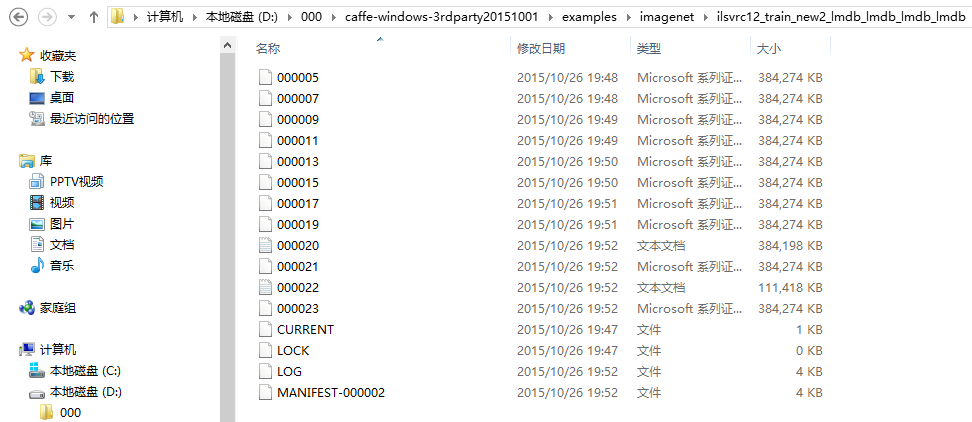
跑出来的结果是这样的:
【2】用compute_image_mean.exe进行取均值的预处理,生成.binaryproto文件
.\bin\compute_image_mean.exe --backend="leveldb" D:\000\caffe-windows-3rdparty20151001\examples\imagenet\ilsvrc12_train_lmdb D:\000\caffe-windows-3rdparty20151001\examples\imagenet\mean.binaryproto
pause
跑出来的结果是这样的:

【3】用caffe.exe跑CNN
先看看caffe.exe 的help
C:\Users\connor>D:\000\caffe-windows-3rdparty20151001\bin\caffe.exe -help
D:\000\caffe-windows-3rdparty20151001\bin\caffe.exe: command line brew
usage: caffe <command> <args>
commands:
train train or finetune a model
test score a model
device_query show GPU diagnostic information
time benchmark model execution time
Flags from ..\..\src\gflags.cc:
--flagfile (load flags from file)
type: string default: ""
--fromenv (set flags from the environment [use 'export FLAGS_flag1=value'])
type: string default: ""
--tryfromenv (set flags from the environment if present)
type: string default: ""
--undefok (comma-separated list of flag names that it is okay to specify on
the command line even if the program does not define a flag with that
name. IMPORTANT: flags in this list that have arguments MUST use the
flag=value format)
type: string default: ""
Flags from ..\..\src\gflags_completions.cc:
--tab_completion_columns (Number of columns to use in output for tab
completion)
type: int32 default: 80
--tab_completion_word (If non-empty, HandleCommandLineCompletions() will
hijack the process and attempt to do bash-style command line flag
completion on this value.)
type: string default: ""
Flags from ..\..\src\gflags_reporting.cc:
--help (show help on all flags [tip: all flags can have two dashes])
type: bool default: false currently: true
--helpfull (show help on all flags -- same as -help)
type: bool default: false
--helpmatch (show help on modules whose name contains the specified substr)
type: string default: ""
--helpon (show help on the modules named by this flag value)
type: string default: ""
--helppackage (show help on all modules in the main package)
type: bool default: false
--helpshort (show help on only the main module for this program)
type: bool default: false
--helpxml (produce an xml version of help)
type: bool default: false
--version (show version and build info and exit)
type: bool default: false
Flags from ..\..\tools\caffe.cpp:
--gpu (Optional; run in GPU mode on given device IDs separated by ','.Use
'-gpu all' to run on all available GPUs. The effective training batch
size is multiplied by the number of devices.)
type: string default: ""
--iterations (The number of iterations to run.)
type: int32 default: 50
--model (The model definition protocol buffer text file..)
type: string default: ""
--sighup_effect (Optional; action to take when a SIGHUP signal is received:
snapshot, stop or none.)
type: string default: "snapshot"
--sigint_effect (Optional; action to take when a SIGINT signal is received:
snapshot, stop or none.)
type: string default: "stop"
--snapshot (Optional; the snapshot solver state to resume training.)
type: string default: ""
--solver (The solver definition protocol buffer text file.)
type: string default: ""
--weights (Optional; the pretrained weights to initialize finetuning,
separated by ','. Cannot be set simultaneously with snapshot.)
type: string default: ""
C:\Users\connor>有两个主要的参数:
solver
和
snapshot
solver是指向solver.prototxt配置文件的。
snapshot是将屏幕上输出的东西写进一个txt文件里。
下面看prototxt文件里的内容,在 E:\000Deep Learning000\caffe-windows-3rdparty20151001\models\bvlc_alexnet 里.
net: "models/bvlc_alexnet/train_val.prototxt"
test_iter: 1000
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "models/bvlc_alexnet/caffe_alexnet_train"
solver_mode: GPU
下一部分引自caffe下自己的数据训练和测试
我们还有一个运行的协议solver.prototxt,复制过来,将第一行路径改为我们的路径net: “examples/myself/train_val.prototxt”,从里面可以观察到,我们将运行256批次,迭代4500000次(90期),每1000次迭代,我们测试学习网络验证数据,我们设置初始的学习率为0.01,每100000(20期)次迭代减少学习率,显示一次信息,训练的weight_decay为0.0005,每10000次迭代,我们显示一下当前状态。
以上是教程的,实际上,以上需要耗费很长时间,因此,我们稍微改一下
test_iter: 1000是指测试的批次,我们就10张照片,设置10就可以了。
test_interval: 1000是指每1000次迭代测试一次,我们改成500次测试一次。
base_lr: 0.01是基础学习率,因为数据量小,0.01就会下降太快了,因此改成0.001
lr_policy: “step”学习率变化
gamma: 0.1学习率变化的比率
stepsize: 100000每100000次迭代减少学习率
display: 20每20层显示一次
max_iter: 450000最大迭代次数,
momentum: 0.9学习的参数,不用变
weight_decay: 0.0005学习的参数,不用变
snapshot: 10000每迭代10000次显示状态,这里改为2000次
solver_mode: GPU末尾加一行,代表用GPU进行
打开 models/bvlc_alexnet/train_val.prototxt 看看
先只看数据层:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: leveldb
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: leveldb
}
}这里backend: LMDB要改成backend: LEVELDB,注意要全部大写,不然会报错。
下面就可以直接运行caffe.exe跑CNN了,cmd命令如下:
D:\000\caffe-windows-3rdparty20151001\bin\caffe.exe train --solver=models\bvlc_alexnet\solver.prototxt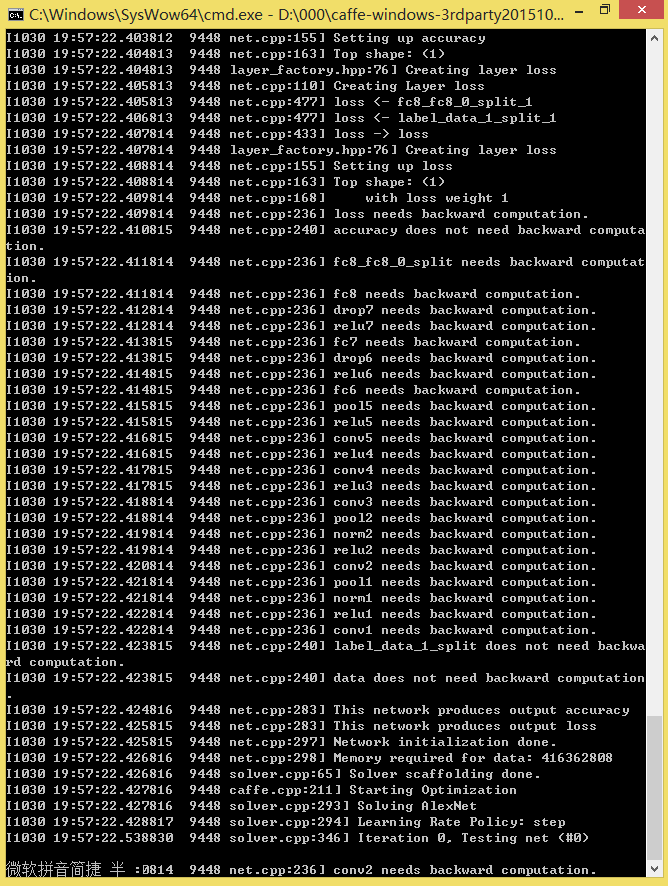
本文实验过程中承蒙实验室孙满利师兄指导,撒花感谢~














 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









