






Adam 这个名字来源于adaptive moment estimation,自适应矩估计,如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。TensorFlow提供的tf.train.AdamOptimizer可控制学习速度。Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。it does not require stationary objective, works with sparse gradients, naturally performs a form of step size annealing。AdamOptimizer通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整。
SGD介绍
假如我们要优化一个函数
 ,即找到它的最小值, 常用的方法叫做Gradient Descent (GD), 也就是最速下降法. 说起来很简单, 就是每次沿着当前位置的导数方向走一小步, 走啊走啊就能够走到一个好地方了.
,即找到它的最小值, 常用的方法叫做Gradient Descent (GD), 也就是最速下降法. 说起来很简单, 就是每次沿着当前位置的导数方向走一小步, 走啊走啊就能够走到一个好地方了.
,即找到它的最小值, 常用的方法叫做Gradient Descent (GD), 也就是最速下降法. 说起来很简单, 就是每次沿着当前位置的导数方向走一小步, 走啊走啊就能够走到一个好地方了.
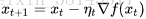
什么是鞍点

自适应优化算法通常都会得到比SGD算法性能更差(经常是差很多)的结果,尽管自适应优化算法在训练时会表现的比较好,因此使用者在使用自适应优化算法时需要慎重考虑!(终于知道为啥CVPR的paper全都用的SGD了,而不是用理论上最diao的Adam)















 7649
7649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









