






原文:
https://builtin.com/machine-learning/adam-optimization
1. 原始SGD
2. 带冲量的SGD:
vt: mementum(冲量)
γ:momentum decay
η:Learning rate
减少反复震荡;在之前保持的正确的方向上,加速收敛;冲出”坑“;
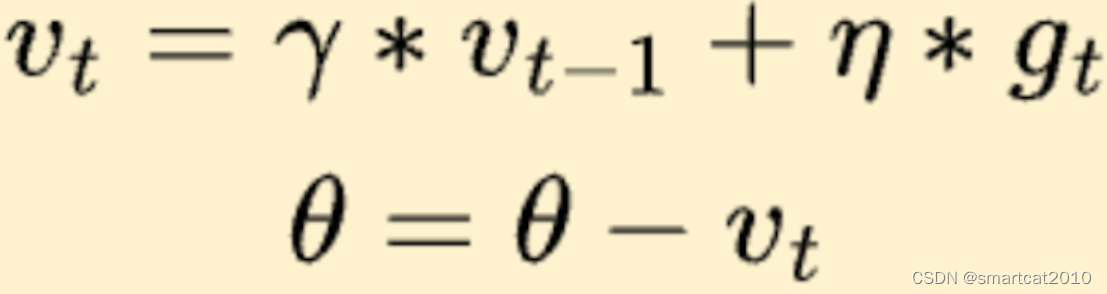
3. RMSProp
E[gt^2]: 梯度平方的带权Moving average;
可把E这个机制,视为自适应学习率。对梯度太大的w,把收敛速度拉得慢一些;梯度太小的w,把收敛速度拉的快一些;(太快了,怕出事故,拉慢些;太慢了,要助力,拉快些)
这样理解更直观:有些特征的g一直很大,有些特征的g一直很小,造成训练的震荡;除以自己这个特征的g的历史的加权平均,可以使得所有特征的g都相近,减少震荡。
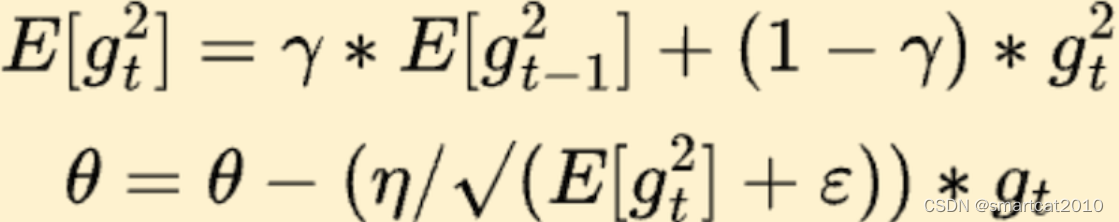
4. 简化版Adam
将Momentum和自适应学习率,相结合了;
mt: 冲量;
vt: 自适应学习率;
ε:防止被0除;
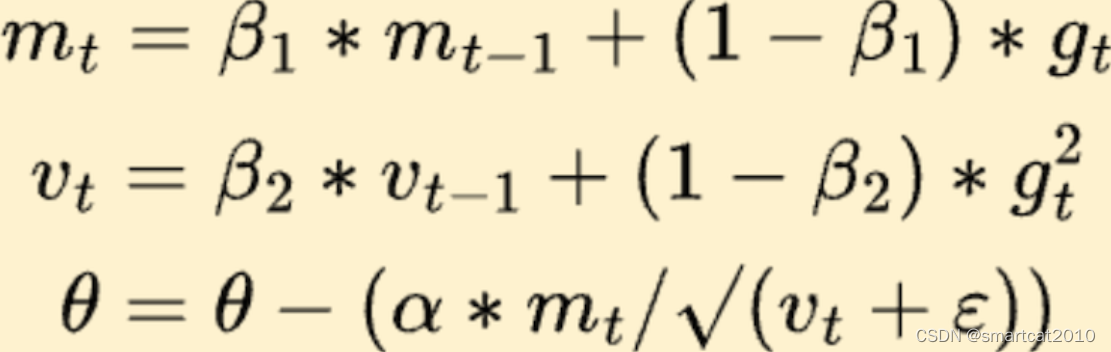
5. 最终版Adam
β1^t和β2^t:warm startup;一上来几轮,m和v太小了接近0(因为m和v的初始值都是0),收敛太慢;加上除以小的数,使得m和v在前几轮比较大;后面随着t增大,该分母趋近于0,可忽略;
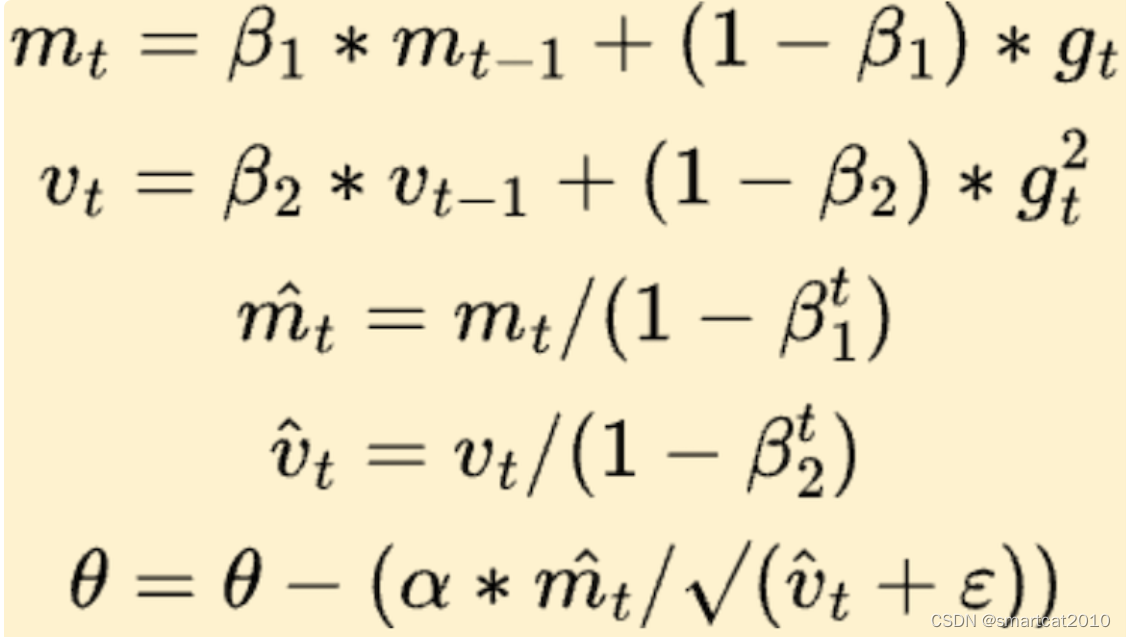

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









