







逻辑回归–《机器学习》课程学习笔记
分类问题(Classification)
如前所述,在分类问题中,我们要预测的变量y是一些离散的值。
我们之前已经学过了线性回归的变化形式来解决分类问题的方法,我们接下来会介绍一种更广泛使用的学习算法–逻辑回归(Logistic Regression)
值得注意的是,逻辑回归算法不是回归问题,而是分类问题。
首先我们从二元的分类问题开始讨论:
我们将因变量(dependent variable)可能属于的两个类分别称之为负向类和正向类,则因变量
y∈{0,1}
, 其中0表示负向类,1表示正向类。
由于我们使用线性回归时不能够保证一个分类问题的因变量值始终在0到1之间,但是我们使用逻辑回归则可以满足条件:
我们使用的逻辑韩式g为:
g(z)=11+e−z
另外,我们知道:
hθ(x)=g(θTX)
则有:
逻辑回归模型
hθ(x)=11+e−θTx
hθx 的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性(estimated probablity),即
hθ(x)=P(y=1|x;θ)
代价函数(Cost Function)
Training set:{(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
m examples:
x∈⎡⎣⎢⎢⎢⎢⎢x0x1x2...xn⎤⎦⎥⎥⎥⎥⎥(x0=1,y∈{0,1})
hθ(x)=11+e−θTx
我们将逻辑函数带入之前求解线性回归时的代价函数时,发现得到的代价函数是非凸函数(non-convex function),因此它有很多个极小值点,因此需要代价函数
ȷ(θ)=1m∑m(i=1)12(hθ(x(i))−y(i))2
进行修正:
我们对逻辑回归的代价函数进行重新定义:
ȷ(θ)=1m∑m(i=1)Cost(hθ(x(i))−y(i))
Cost(hθ(x(i))−y(i))={−log(hθ(x)) if y=1−log(1−hθ(x)) if y=0
我们可以将新得到的Cost函数进行简化:
Cost(hθ(x(i))−y(i))=−y log(hθ(x))−(1−y)log(1−hθ(x))
带入代价函数得到:
ȷ(θ)=−1m[∑m(i=1)y(i) log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))]
则可以得到逻辑回归的梯度下降算法为:
Repeat{
θj:=θj−αϑϑθjȷ(θ0,θ1...,θn)
}
也即:
Repeat{
θj:=θj−αϑϑθj12m∑m1(hθ(x(i))−y(i))2
}
求导后得到:
Repeat{
θj:=θj−αϑϑθj1m∑m1(hθ(x(i))−y(i))∗x(i)j
simultaneously update θj
}
高级优化
我们通过推导过程可以看成,如果需要计算代价函数,那么必须先计算出
ȷ(θ)
和其对
θj
的偏导,但是这是一定的吗?
当然,我们可以使用其他更加高级同时也更加复杂的算法来进行求解代价函数的优化,如共轭梯度法,BFGS(变尺度法),L-BFGS(限制变尺度法)。
这三个算法既然很复杂,那么他们本身有着怎样的优势呢?
首先是其中的任何一种算法你都不需要手动选择学习率
α
,另外他们的收敛速度比使用梯度下降要快得多。
我们可以通过Octave的相关函数调用在不需要知道它们实现细节的基础上对函数进行调用。
如:
function [jVal, gradient]=costFunction(theta)
jVal=(theta(1)-5)^2+(theta(2)-5)^2;
gradient=zeros(2,1);
gradient(1)=2*(theta(1)-5);
gradient(2)=2*(theta(2)-5);
end
options=optimset('GradObj','on','MaxIter',100);
initialTheta=zeros(2,1);
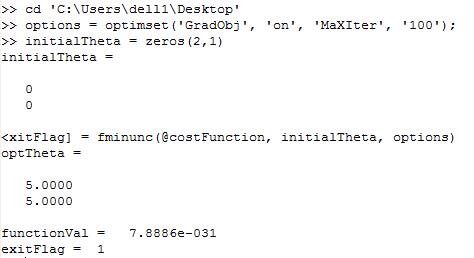
[optTheta, functionVal, exitFlag]=fminunc(@costFunction, initialTheta, options);
这就是计算求解 θ 使用的高级方法。
运行结果:
多类别分类:一对多(Multiclass Classifaction_One-vs-all)
如果我们的数据中X是一个矩阵,也就是每一组的实验数据不是一个,而是一组,那么可以使用下面讲道的分类方法。
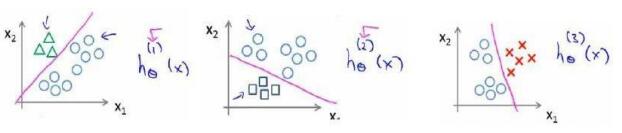
h(i)θ(x)
为逻辑回归分类器:
h(i)θ=p(y=i|x;θ),i=1→k
h(i)θ(x)=(max)ih(i)θ(x)















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









