







3. 激活函数和损失函数
3.1 激活函数
关于激活函数,首先要搞清楚的问题是,激活函数是什么,有什么用?不用激活函数可不可以?答案是不可以。激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。 那么激活函数应该具有什么样的性质呢?
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
从目前来看,常见的激活函数多是分段线性和具有指数形状的非线性函数
3.1.1 sigmoid
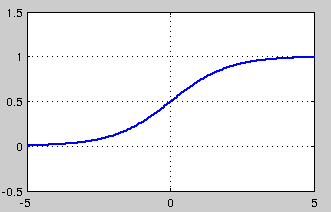
sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
然而,sigmoid也有其自身的缺陷,最明显的就是饱和性。从上图可以看到,其两侧导数逐渐趋近于0
具有这种性质的称为 软饱和激活函数 。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是 硬饱和 , 即
sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区, f′(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
3.1.2 tanh
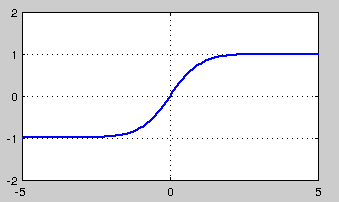
tanh也是一种非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从途中可以看出,tanh一样具有软饱和性,从而造成梯度消失。
3.1.3 ReLU,P-ReLU, Leaky-ReLU
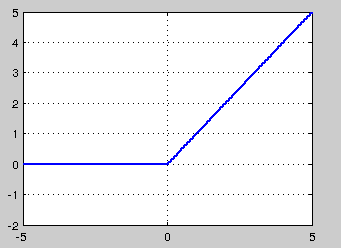
ReLU的全称是Rectified Linear Units,是一种后来才出现的激活函数。 可以看到,当x<0时,ReLU硬饱和,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。这让我们能够直接以监督的方式训练深度神经网络,而无需依赖无监督的逐层预训练。
然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。
针对在x<0的硬饱和问题,我们对ReLU做出相应的改进,使得
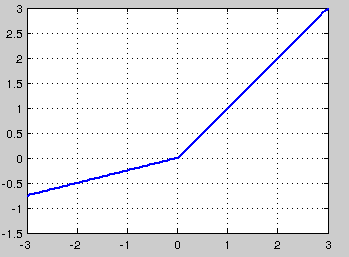
这就是Leaky-ReLU, 而P-ReLU认为, α 也可以作为一个参数来学习,原文献建议初始化a为0.25,不采用正则。
3.1.4 ELU
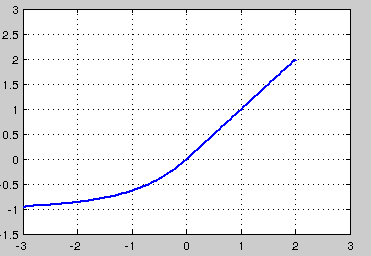
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛
3.1.5 Maxout
在我看来,这个激活函数有点大一统的感觉,因为maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
3.2 损失函数
在之前的内容中,我们用的损失函数都是平方差函数,即
其中y是我们期望的输出,a为神经元的实际输出( a=σ(Wx+b) 。也就是说,当神经元的实际输出与我们的期望输出差距越大,代价就越高。想法非常的好,然而在实际应用中,我们知道参数的修正是与 ∂C∂W 和 ∂C∂b 成正比的,而根据
我们发现其中都有 σ′(a) 这一项。因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会造成饱和现象,从而使得参数的更新速度非常慢,甚至会造成离期望值越远,更新越慢的现象。那么怎么克服这个问题呢?我们想到了交叉熵函数。我们知道,熵的计算公式是
而在实际操作中,我们并不知道y的分布,只能对y的分布做一个估计,也就是算得的a值, 这样我们就能够得到用a来表示y的交叉熵
如果有多个样本,则整个样本的平均交叉熵为
其中n表示样本编号,i表示类别编。 如果用于logistic分类,则上式可以简化成
与平方损失函数相比,交叉熵函数有个非常好的特质,
可以看到其中没有了 σ′ 这一项,这样一来也就不会受到饱和性的影响了。当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
参考资料:
[1]ReLu(Rectified Linear Units)激活函数
[2]神经网络之激活函数面面观
[3]深度学习中的激活函数导引
[4]分类问题损失函数的信息论解释
[5]交叉熵代价函数















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









