







1. 概念
官方解释:利用统计原理进行计算的方法,是一种线性变换。
ICA分为基于信息论准则的迭代算法和基于统计学的代数方法两大类,如FastICA算法,Infomax算法,最大似然估计算法等。
这里主要讨论FastICA算法。
先来看ICA和PCA的区别:PCA是降维并提取不相关属性,而ICA是降维并提取相互独立的属性(不相关不一定独立,独立一定不相关。不相关是指没有线性关系,独立是指没有任何关系)。PCA是提取出最能表示原始事物的特征,而ICA是使每个分量最大化独立,便于发现隐藏因素。
PCA的适用环境是数据为高斯分布时。而ICA不适用于高斯分布的数据。
ICA的两条假设:
① 源信号之间互相独立
② 每一个源信号为非高斯分布
【更新日志:2019-12-27】
为什么原信号为非高斯分布,戳这里
http://cis.legacy.ics.tkk.fi/aapo/papers/IJCNN99_tutorialweb/node9.html
混合信号源的三个特性:
①独立性(Independence):源信号相互独立,但是混合的信号却不是,因为混合信号共享了源信号。
②正态化(Normality):根据中心极限定理,具有有限方差的独立随机变量的和的分布倾向于高斯分布;宽松点说就是,两个独立随机变量的和比原始的独立随机变量中的任何一个更加接近高斯分布。这里我们考虑的每一个信号源都是独立随机变量。
③复杂度(Complexity):任何混合信号的时间复杂性都比构成它的最简单的信号源复杂。
其实这几点就告诉我们ICA的动机:如果组成混合信号的信号是独立的,或者具有非高斯直方图,或者较低复杂度,那么他们一定是信号源。
2. 白化
为了便于计算,需要先进行数据预处理:
对数据进行白化或球化处理去除各观测信号之间的相关性,简化后续独立分量的提取过程,且算法的收敛性较好。
白化向量:若一零均值的随机向量Z=(Z1,Z2,…ZM)T满足E{ZZT}=I,其中I是单位矩阵。白化的本质是去相关,同PCA的目标是一样的。称源信号S(t)为白色的是因为对于零均值的独立源信号S(t)=[S1(t),….,SN(t)]T,有E{Si Sj}=E{Si}E{Sj}=0(i≠j)且协方差矩阵是单位阵,cov(S)=I。
对于观测信号X(t),找到线性变换W0,使X(t)投影到新的子空间后变成白化向量,即Z(t)=W0X(t),
其中W0为白化矩阵,Z为白化向量
利用主成分分析能得到
W0=Λ-1/2UT
其中U和Λ分别代表协方差矩阵CX的特征向量矩阵和特征值矩阵。
因此协方差矩阵:
E{ZZT}=E{Λ-1/2UTXXTUΛ-1/2}=Λ-1/2UTE{XXT}UΛ-1/2=Λ-1/2ΛΛ-1/2=I
将X(t)=AS(t)式代入Z(t)=W0X(t),且令W0A=A~,有
Z(t)=W0AS(t)=A~S(t)
多维情况下,混合矩阵A是N*N的,白化后的新的混合矩阵A~是正交矩阵,自由度降为N*(N-1)/2,所以说白化使得ICA问题的工作量几乎减少了一半。
用PCA对观测信号进行白化的预处理使原来所求的解混合矩阵退化成一个正交阵,减少了ICA的工作量,当观测信号的个数大于源信号个数时,经过PCA降维也就是白化可以自动将观测信号的数目降到与源信号数目维数相同。
3. FastICA算法
FastICA算法也叫固定点算法(Fixed-Point)算法,是一种快速寻优迭代算法,采用批处理的方式,每一步迭代由大量的样本数据参与运算。
FastICA由基于峭度,基于似然最大,基于负熵最大等形式。这里介绍基于负熵最大的FastICA算法。
负熵的判决准则:由信息论理论可知,在所有等方差的随机变量中,高斯变量的熵最大,所以可以利用熵来度量非高斯性,采用熵的修正形式,负熵。根据中心极限定理,若一个随机变量X由许多相互独立的随机变量Si(i=1,2,3….,N)之和组成,只要Si具有有限的均值和方差,则不论其为何种分布,随机变量X较Si更接近高斯分布。所以当高斯性度量达到最大的时候,说明完成各独立成分的分离。
负熵的定义
Ng(Y)=H(YGauss)-H(Y)
其中YGauss是与Y具有相同方差的高斯随机变量。H(.)为随机变量的微分熵。
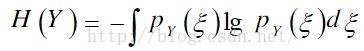
根据信息理论,在具有相同方差的随机变量中,高斯分布的随机变量具有最大的微分熵。当Y具有高斯分布时,Ng(Y)=0;Y的非高斯性越强,其微分熵越小,Ng(Y)的值越大,所以Ng(Y)可以作为随机变量Y非高斯性的测度。采用负熵定义求解需要知道Y的概率密度分布函数,但是实际不可能,于是采用下面的近似公式:
Ng(Y)={E[g(Y)]-E[g(YGauss)]}²
其中E[.]为均值运算,g(.)为非线性函数,可取g1(y)=tanh(a1y)或g2(y)=y exp(-y2/2)或g3(y)=y3等非线性函数,这里1≤a1≤2,通常取a1=1
快速ICA的规则就是找到一个方向以便WTX(Y=WTX)具有最大的非高斯性,非高斯性用Ng(Y)={E[g(Y)]-E[g(YGauss)]}²给出的负熵的近似值来度量。WTX的方差约束为1,对于白化数据,等于约束W的范数为1.
FastICA的推导:
① WTX的负熵的最大近似值能通过对E{G(WTX)}进行优化取得。在E{( WTX)²}=||W||²=1的约束下,E{G(WTX)}的最优值能在满足下式的点上获得
E{Xg(WTX)}+βW=0
其中β=E{W0TXg(WTX)} 是一个恒定值,W0是优化后的W值。
②利用牛顿迭代法解①的方程。用F表示左边的函数,得到F的雅克比矩阵JF(W)如下:
JF(W)=E{XXTg’(WTX)}-βI 可以近似为第一项,即忽略βI
由于数据被球化,所以E{XXT}=I,所以E{XXTg’(WTX)}≈E{XXT}*E{g’(WTX)}=E{g’(WTX)}I。
从而雅克比矩阵变成了对角阵,并且比较容易求逆。因而得到下面的近似牛顿迭代公式:
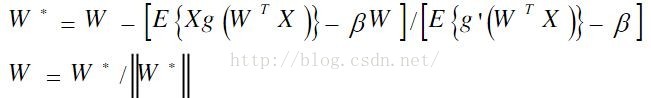
这里的W*是W的新值,β= E{WTXg(WTX)},规格化能提高稳定性。
简化后得到FastICA的迭代公式:
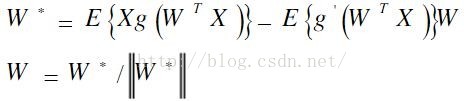
实践中,FastICA算法中用的期望必须用他们的估计值代替。最好的估计是相应的样本平均。理想情况下,所有的有效数据都应该参与计算,但是会降低运算速度,所以通常选取一部分样本的平均来估计,样本数目的多少对最后估计的精确度有很大影响。迭代中的样本点应该分别选取,加入收敛不理想,可以增加样本数量。
FastICA算法的步骤:
1. 对观测数据X进行中心化,使它的均值为0
2. 对数据进行白化,X→Z
3. 选择需要估计的分量的个数m,设迭代次数p←1
4. 选择一个初始权矢量(随机的)Wp。
5. 令Wp=E{Zg(WTZ)}-E{g’(WTZ)}W,非线性函数g,可取g1(y)=tanh(a1y)或g2(y)=y exp(-y2/2)或g3(y)=y3等非线性函数
6.
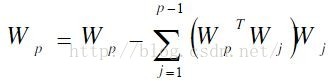
7.令Wp=Wp/||Wp||。
8. 假如Wp不收敛的话,返回第五步
9. 令p=p+1,如果p≤m,返回第四步
ICA.m
function Z = ICA( X )
%去均值
[M,T]=size(X); %获取输入矩阵的行列数,行数为观测数据的数目,列数为采样点数
average=mean(X')'; %均值
for i=1:M
X(i,:)=X(i,:)-average(i)*ones(1,T);
end
%白化/球化
Cx=cov(X',1); %计算协方差矩阵Cx
[eigvector,eigvalue]=eig(Cx); %计算Cx的特征值和特征向量
W=eigvalue^(-1/2)*eigvector'; %白化矩阵
Z=W*X; %正交矩阵
%迭代
Maxcount=10000; %最大迭代次数
Critical=0.00001; %判断是否收敛
m=M;
W=rand(m);
for n=1:m
WP=W(:,n); %初始权矢量(任意)
%Y=WP'*Z;
%G=Y.^3;%G为非线性函数,可取y^3等
%GG=3*Y.^2; %G的导数
count=0;
LastWP=zeros(m,1);
W(:,n)=W(:,n)/norm(W(:,n));
while abs(WP-LastWP)&abs(WP+LastWP)>Critical
count=count+1; %迭代次数
LastWP=WP; %上次迭代的值
%WP=1/T*Z*((LastWP'*Z).^3)'-3*LastWP;
for i=1:m
WP(i)=mean(Z(i,:).*(tanh((LastWP)'*Z)))-(mean(1-(tanh((LastWP))'*Z).^2)).*LastWP(i);
end
WPP=zeros(m,1);
for j=1:n-1
WPP=WPP+(WP'*W(:,j))*W(:,j);
end
WP=WP-WPP;
WP=WP/(norm(WP));
if count==Maxcount
fprintf('未找到相应的信号');
return;
end
end
W(:,n)=WP;
end
Z=W'*Z;
end
ICATest.m
clear all;
clc;
N=200;
n=1:N;%N为采样本数
s1=2*sin(0.02*pi*n); %正弦信号
t=1:N;
s2=2*square(100*t,50); %方波信号
a=linspace(1,-1,25);
s3=2*[a,a,a,a,a,a,a,a];%锯齿信号
s4=rand(1,N); %随机噪声
S=[s1;s2;s3;s4]; %信号组成4*N
A=rand(4,4);
X=A*S; %观察信号
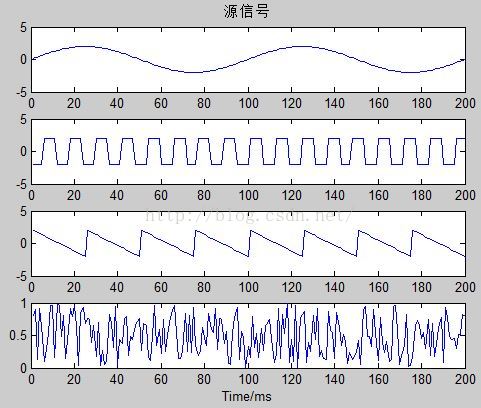
%源信号波形图
figure(1);
subplot(4,1,1);plot(s1);axis([0 N -5,5]);title('源信号');
subplot(4,1,2);plot(s2);axis([0 N -5,5]);
subplot(4,1,3);plot(s3);axis([0 N -5,5]);
subplot(4,1,4);plot(s4);xlabel('Time/ms');
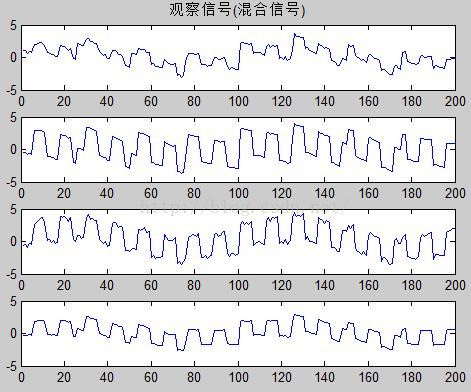
%观察信号(混合信号)波形图
figure(2);
subplot(4,1,1);plot(X(1,:));title('观察信号(混合信号)');
subplot(4,1,2);plot(X(2,:));
subplot(4,1,3);plot(X(3,:));
subplot(4,1,4);plot(X(4,:));
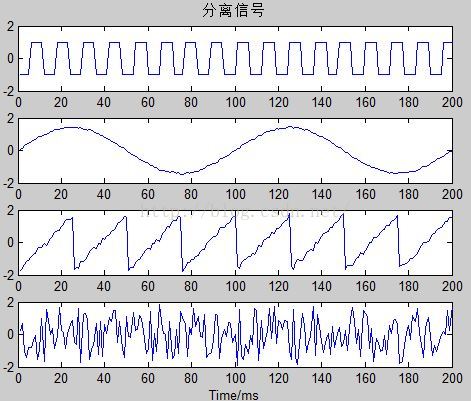
Z=ICA(X);
figure(3);subplot(4,1,1);plot(Z(1,:));title('分离信号');
subplot(4,1,2);plot(Z(2,:));
subplot(4,1,3);plot(Z(3,:));
subplot(4,1,4);plot(Z(4,:));
plot(Z(4,:));
xlabel('Time/ms');
结果
参考文献:
http://www.cnblogs.com/tornadomeet/archive/2012/12/30/2839841.html
https://en.wikipedia.org/wiki/Independent_component_analysis
http://cs229.stanford.edu/notes/cs229-notes11.pdf
本文已经同步到微信公众号中,公众号与本博客将持续同步更新运动捕捉、机器学习、深度学习、计算机视觉算法,敬请关注
















 2095
2095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











