






LUCENE.COM.CN
中国
··· 2
开放源代码的全文检索引擎
Lucene
――介绍、系统结构与源码实现分析
一、
什么是全文检索与全文检索系统?
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向
WWW[1]
的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。图
1.1
展示了上述全文检索系统的结构与功能。
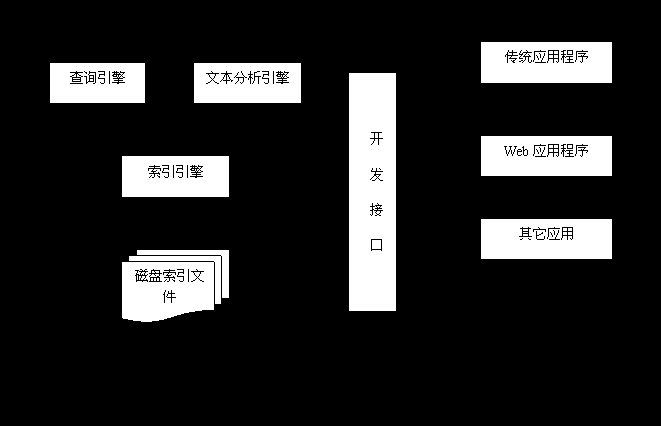
在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。另一个方面,一个优异的全文检索引擎,在做到效率优化的同时,还需要具有开放的体系结构,以方便程序员对整个系统进行优化改造,或者是添加原有系统没有的功能。比如在当今多语言处理的环境下,有时需要给全文检索系统添加处理某种语言或者文本格式的功能,比如在英文系统中添加中文处理功能,在纯文本系统中添加
XML[2]
或者
HTML[3]
格式的文本处理功能,系统的开放性和扩充性就十分的重要。
二、
什么是Lucene?
Lucene
是
apache
软件基金会
[4]
jakarta
项目组的一个子项目,是一个开放源代码
[5]
的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene
的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene
的原作者是
Doug Cutting
,他是一位资深全文索引
/
检索专家,曾经是
V-Twin
搜索引擎
[6]
的主要开发者,后在
Excite[7]
担任高级系统架构设计师,目前从事于一些
Internet
底层架构的研究。早先发布在作者自己的
http://www.lucene.com/
,后来发布在
SourceForge[8]
,
2001
年年底成为
apache
软件基金会
jakarta
的一个子项目:
http://jakarta.apache.org/lucene/
。
三、
Lucene的应用、特点及优势
作为一个开放源代码项目,
Lucene
从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建
Web
应用,甚至某些商业软件也采用了
Lucene
作为其内部全文检索子系统的核心。
apache
软件基金会的网站使用了
Lucene
作为全文检索的引擎,
IBM
的开源软件
eclipse[9]
的
2.1
版本中也采用了
Lucene
作为帮助子系统的全文索引引擎,相应的
IBM
的商业软件
Web Sphere[10]
中也采用了
Lucene
。
Lucene
以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene
作为一个全文检索引擎,其具有如下突出的优点:
(
1
)索引文件格式独立于应用平台。
Lucene
定义了一套以
8
位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(
2
)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(
3
)优秀的面向对象的系统架构,使得对于
Lucene
扩展的学习难度降低,方便扩充新功能。
(
4
)设计了独立于语言和文件格式的文本分析接口,索引器通过接受
Token
流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(
5
)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,
Lucene
的查询实现中默认实现了布尔操作、模糊查询(
Fuzzy Search[11]
)、分组查询等等。
面对已经存在的商业全文检索引擎,
Lucene
也具有相当的优势。首先,它的开发源代码发行方式(遵守
Apache Software License[12]
),在此基础上程序员不仅仅可以充分的利用
Lucene
所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及
Lucene
。其次,
Lucene
秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在
Lucene
的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到
HTML
、
PDF[13]
等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于
Lucene
恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。最后,转移到
apache
软件基金会后,借助于
apache
软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然
Lucene
使用
Java
语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如
.net framework[14]
),在遵守
Lucene
索引文件格式的基础上,使得
Lucene
能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
四、
本文的重点问题与cLucene项目
作为中国人民大学信息学院
99
级本科生的一个毕业设计项目,我们对
Lucene
进行了深入的研究,包括系统的结构,索引文件结构,各个部分的实现等等。并且我们启动了
cLucene
项目,做为一个
Lucene
的
C++
语言的重新实现,以期望带来更快的速度和更加广泛的应用范围。我们先分析了系统结构,文件结构,然后在研究各个部分的具体实现的同时开始进行的
cLucene
实现。限于时间的限制,到本文完成为止,
cLucene
项目并没有完成,对于
Lucene
的具体实现部分也仅仅完成到了索引引擎部分。
接下来的部分,本文将对
Lucene
的系统结构、文件结构、索引引擎部分做一个彻底的分析。以期望提供对
Lucene
全文检索引擎的系统架构和部分程序实现的清晰的了解。
cLucene
项目则作为一个开放源代码的项目,继续进行的开发。
有关
cLucene
项目的一些信息:
n
开发语言:
ISO C++[15]
,
STLport 4.5.3[16]
,
OpenTop 1.1[17]
n
目标平台:
Win32
,
POSIX
n
授权协议:
GNU General Public License (GPL)[18]
一、
系统结构组织
Lucene
作为一个优秀的全文检索引擎,其系统结构具有强烈的面向对象特征。首先是定义了一个与平台无关的索引文件格式,其次通过抽象将系统的核心组成部分设计为抽象类,具体的平台实现部分设计为抽象类的实现,此外与具体平台相关的部分比如文件存储也封装为类,经过层层的面向对象式的处理,最终达成了一个低耦合高效率,容易二次开发的检索引擎系统。
以下将讨论
Lucene
系统的结构组织,并给出系统结构与源码组织图:
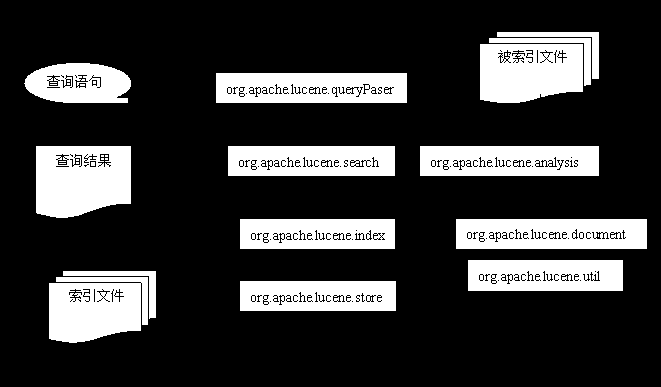
从图中我们清楚的看到,
Lucene
的系统由基础结构封装、索引核心、对外接口三大部分组成。其中直接操作索引文件的索引核心又是系统的重点。
Lucene
的将所有源码分为了
7
个模块(在
java
语言中以包即
package
来表示),各个模块所属的系统部分也如上图所示。需要说明的是
org.apache.lucene.queryPaser
是做为
org.apache.lucene.search
的语法解析器存在,不被系统之外实际调用,因此这里没有当作对外接口看待,而是将之独立出来。
从面象对象的观点来考察,
Lucene
应用了最基本的一条程序设计准则:引入额外的抽象层以降低耦合性。首先,引入对索引文件的操作
org.apache.lucene.store
的封装,然后将索引部分的实现建立在(
org.apache.lucene.index
)其之上,完成对索引核心的抽象。在索引核心的基础上开始设计对外的接口
org.apache.lucene.search
与
org.apache.lucene.analysis
。在每一个局部细节上,比如某些常用的数据结构与算法上,
Lucene
也充分的应用了这一条准则。在高度的面向对象理论的支撑下,使得
Lucene
的实现容易理解,易于扩展。
Lucene
在系统结构上的另一个特点表现为其引入了传统的客户端服务器结构以外的的应用结构。
Lucene
可以作为一个运行库被包含进入应用本身中去,而不是做为一个单独的索引服务器存在。这自然和
Lucene
开放源代码的特征分不开,但是也体现了
Lucene
在编写上的本来意图:提供一个全文索引引擎的架构,而不是实现。
二、
数据流分析
理解
Lucene
系统结构的另一个方式是去探讨其中数据流的走向,并以此摸清楚
Lucene
系统内部的调用时序。在此基础上,我们能够更加深入的理解
Lucene
的系统结构组织,以方便以后在
Lucene
系统上的开发工作。这部分的分析,是深入
Lucene
系统的钥匙,也是进行重写的基础。
我们来看看在
Lucene
系统中的主要的数据流以及它们之间的关系图:
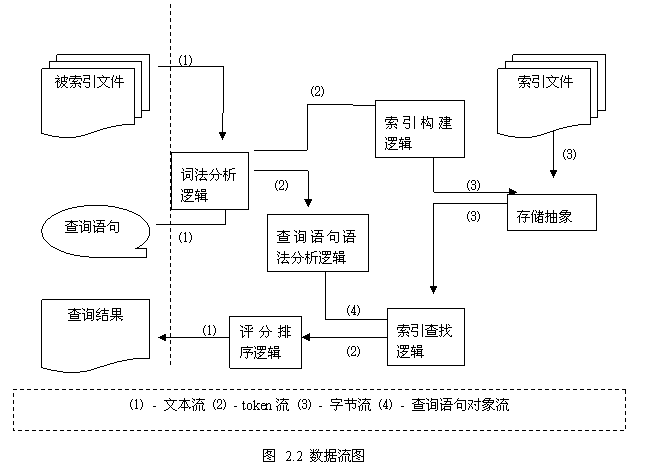
图
2.2
很好的表明了
Lucene
在内部的数据流组织情况,并且沿着数据流的方向我们也可以对与
Lucene
内部的执行时序有一个清楚的了解。现在将图中的涉及到的流的类型与各个逻辑对应系统的相关部分的关系说明一下。
图中共存在
4
种数据流,分别是文本流、
token
流、字节流与查询语句对象流。文本流表示了对于索引目标和交互控制的抽象,即用文本流表示了将要索引的文件,用文本流向用户输出信息;在实际的实现中,
Lucene
中的文本流采用了
UCS-2[19]
作为编码,以达到适应多种语言文字的处理的目的。
Token
流是
Lucene
内部所使用的概念,是对传统文字中的词的概念的抽象,也是
Lucene
在建立索引时直接处理的最小单位;简单的讲
Token
就是一个词和所在域值的组合,后面在叙述文件格式时也将继续涉及到
token
,这里不详细展开。字节流则是对文件抽象的直接操作的体现,通过固定长度的字节(
Lucene
定义为
8
比特位长,后面文件格式将详细叙述)流的处理,将文件操作解脱出来,也做到了与平台文件系统的无关性。查询语句对象流则是仅仅在查询语句解析时用到的概念,它对查询语句抽象,通过类的继承结构反映查询语句的结构,将之传送到查找逻辑来进行查找的操作。
图中的涉及到了多种逻辑,基本上直接对应于系统某一模块,但是也有跨模块调用的问题发生,这是因为
Lucene
的重用程度非常好,因此很多实现直接调用了以前的工作成果,这在某种程度上其实是加强了模块耦合性,但是也是为了避免系统的过于庞大和不必要的重复设计的一种折衷体现。词法分析逻辑对应于
org.apache.lucene.analysis
部分。查询语句语法分析逻辑对应于
org.apache.lucene.queryParser
部分,并且调用了
org.apache.lucene.analysis
的代码。查询结束之后向评分排序逻辑输出
token
流,继而由评分排序逻辑处理之后给出文本流的结果,这一部分的实现也包含在了
org.apache.lucene.search
中。索引构建逻辑对应于
org.apache.lucene.index
部分。索引查找逻辑则主要是
org.apache.lucene.search
,但是也大量的使用了
org.apache.lucene.index
部分的代码和接口定义。存储抽象对应于
org.apache.lucene.store
。没有提到的模块则是做为系统公共基础设施存在。
三、
基于Lucene的应用开发
通过以上的系统结构分析和数据流分析,我们已经很清楚的了解了
Lucene
的系统的结构特征。在此基础上,我们可以通过扩充
Lucene
系统来完成一个完备的全文检索引擎,紧接着还可以在全文检索引擎的基础上构建各种应用系统。鉴于本文的目的并不在此,以下我们只是略为叙述一下相关的步骤,从而给出应用开发的一些思路。
首先,我们需要的是按照目标语言的词法结构来构建相应的词法分析逻辑,实现
Lucene
在
org.apache.lucene.analysis
中定义的接口,为
Lucene
提供目标系统所使用的语言处理能力。
Lucene
默认的已经实现了英文和德文的简单词法分析逻辑(按照空格分词,并去除常用的语法词,如英语中的
is
,
am
,
are
等等)。在这里,主要需要参考实现的接口在
org.apache.lucene.analysis
中的
Analyzer.java
和
Tokenizer.java
中定义,
Lucene
提供了很多英文规范的实现样本,也可以做为实现时候的参考资料。其次,需要按照被索引的文件的格式来提供相应的文本分析逻辑,这里是指除开词法分析之外的部分,比如
HTML
文件,通常需要把其中的内容按照所属于域分门别类加入索引,这就需要从
org.apache.lucene.document
中定义的类
document
继承,定义自己的
HTMLDocument
类,然后就可以将之交给
org.apache.lucene.index
模块来写入索引文件。完成了这两步之后,
Lucene
全文检索引擎就基本上完备了。这个过程可以用下图表示:

当然,上面所示的仅仅只是对于
Lucene
的基本扩充过程,它将
Lucene
由不完备的变成完备的(尤其是对于非英语的语言检索)。除此之外我们还可以在很多方面对
Lucene
进行改造。第一个方面即为按照文档索引的域,比如标题,作者之类的信息对返回的查询结果排序,这即需要改造
Lucene
的评分排序逻辑。默认的,
Lucene
采用其内部的相关性方法来处理评分和排序,我们可以根据需要改变它。遗憾的是,这部分
Lucene
并没有做到如同扩充词法解析和文档类型那样的条理清晰,没有留下很好的接口,因此需要仔细的分析其源代码的实现,自行扩充等等。其他的方面,比如改进其索引的效率,改进其返回结果时候的缓冲机制等等,都是加强
Lucene
系统的方面,在此也不再叙述。
完成了
Lucene
系统,之后就可以开始考虑其上的应用系统开发。如果应用系统也使用
java
语言开发,那么
Lucene
系统能够方便的嵌入到整个系统中去,作为一个
API
集来调用。这个过程十分简单,以下便是一个示例程序,配合注释理解起来很容易。
|

或者,
Lucene
全文检索引擎也可作为服务器程序启动,但是这就需要用户自行扩充其他应用与
Lucene
的接口。这个可以通过传统的包装方式,比如客户服务器结构,或者采用现在流行的
Web
方式。诸如此类的应用方案,本文也不再继续叙述。参考
Lucene
的项目网站中的用户邮件列表能找到更多的信息。
一、
Lucene源码实现分析的说明
通过以上对
Lucene
系统结构的分析,我们已经大致的清楚了
Lucene
系统的组成,以及在
Lucene
系统之上的开发步骤。接下来,我们试图来分析
Lucene
项目(采用
Lucene 1.2
版本)的源码实现,考察其实现的细节。这不仅仅是我们尝试用
C++
语言重新实现
Lucene
的必须工作,也是进一步做
Lucene
开发工作的必要准备。因此,这一部分所涉及到的内容,对于
Lucene
上的应用开发也是有价值的,尤其是本部分所做的文件格式分析。
由于本文建立在我们的毕设项目之上,且同时我们需要实现
cLucene
项目,因此很遗憾的我们并没有完全的完成
Lucene
的所有源码实现的分析工作。接下来的部分,我们将涉及的部分为
Lucene
文件格式分析,
Lucene
中的存储抽象模块分析,以及
Lucene
中的索引构建逻辑模块分析。这一部分,我们主要涉及到的是文件格式分析与存储抽象模块分析。
二、
Lucene索引文件格式
在
Lucene
的
web
站点上,有关于
Lucene
的文件格式的规范,其规定了
Lucene
的文件格式采取的存储单位、组织结构、命名规范等等内容,但是它仅仅是一个规范说明,并没有从实现者角度来衡量这个规范的实现。因此,我们以下的内容,结合了我们自己的分析与文件格式的定义规范,以期望给出一个更加清晰的文件格式说明。具体的文档规范可以参考后面的文献
2
。
首先在
Lucene
的文件格式中,以字节为基础,定义了如下的数据类型:
表
3.1 Lucene
文件格式中定义的数据类型
|
数据类型
|
所占字节长度(字节)
|
说明
| ||||||||||||||||||||||||||||||||||||||||||||
|
Byte
|
1
|
基本数据类型,其他数据类型以此为基础定义
| ||||||||||||||||||||||||||||||||||||||||||||
|
UInt32
|
4
|
32
位无符号整数,高位优先
| ||||||||||||||||||||||||||||||||||||||||||||
|
UInt64
|
8
|
64
位无符号整数,高位优先
| ||||||||||||||||||||||||||||||||||||||||||||
|
VInt
|
不定,最少
1
字节
|
动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下
| ||||||||||||||||||||||||||||||||||||||||||||
|
Chars
|
不定,最少
1
字节
|
采用
UTF-8
编码
[20]
的
Unicode
字符序列
| ||||||||||||||||||||||||||||||||||||||||||||
|
String
|
不定,最少
2
字节
|
由
VInt
和
Chars
组成的字符串类型,
VInt
表示
Chars
的长度,
Chars
则表示了
String
的值
|
以上的数据类型就是
Lucene
索引文件格式中用到的全部数据类型,由于它们都以字节为基础定义而来,因此保证了是平台无关,这也是
Lucene
索引文件格式平台无关的主要原因。接下来我们看看
Lucene
索引文件的概念组成和结构组成。
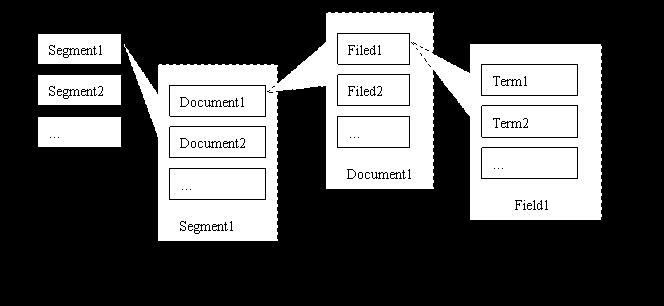
以上就是
Lucene
的索引文件的概念结构。
Lucene
索引
index
由若干段
(segment)
组成,每一段由若干的文档(
document
)组成,每一个文档由若干的域(
field
)组成,每一个域由若干的项(
term
)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚的看出,
Lucene
的索引结构在概念上即为传统的倒排索引结构
[21]
。
从概念上映射到结构中,索引被处理为一个目录(文件夹),其中含有的所有文件即为其内容,这些文件按照所属的段不同分组存放,同组的文件拥有相同的文件名,不同的扩展名。此外还有三个文件,分别用来保存所有的段的记录、保存已删除文件的记录和控制读写的同步,它们分别是
segments
,
deletable
和
lock
文件,都没有扩展名。每个段包含一组文件,它们的文件扩展名不同,但是文件名均为记录在文件
segments
中段的名字。让我们看如下的结构图
3.2
。
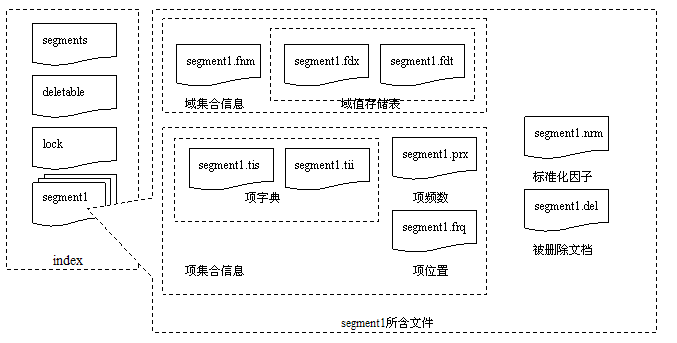
关于图
3.2
中的各个文件具体的内部格式,在参考文献
3
中,均可以找到详细的说明。接下来我们从宏观关系上说明一下这些文件组成。在这些宏观上的关系理清楚之后,仔细阅读参考文献
3
,即可清楚的明白具体的
Lucene
文件格式。
每个段的文件中,主要记录了两大类的信息:域集合与项集合。这两个集合中所含有的文件在图
3.2
中均有表明。由于索引信息是静态存储的,域集合与项集合中的文件组采用了一种类似的存储办法:一个小型的索引文件,运行时载入内存;一个对应于索引文件的实际信息文件,可以按照索引中指示的偏移量随机访问;索引文件与信息文件在记录的排列顺序上存在隐式的对应关系,即索引文件中按照“索引项
1
、索引项
2
…”排列,则信息文件则也按照“信息项
1
、信息项
2
…”排列。比如在图
3.2
所示文件中,
segment1.fdx
与
segment1.fdt
之间,
segment1.tii
与
segment1.tis
、
segment1.prx
、
segment1.frq
之间,都存在这样的组织关系。而域集合与项集合之间则通过域的在域记录文件(比如
segment1.fnm
)中所记录的域记录号维持对应关系,在图
3.2
中
segment1.fdx
与
segment1.tii
中就是通过这种方式保持联系。这样,域集合和项集合不仅仅联系起来,而且其中的文件之间也相互联系起来。此外,标准化因子文件和被删除文档文件则提供了一些程序内部的辅助设施(标准化因子用在评分排序机制中,被删除文档是一种伪删除手段)。这样,整个段的索引信息就通过这些文档有机的组成。
以上所阐述的,就是
Lucene
所采用的索引文件格式。基本上而言,它是一个倒排索引,但是
Lucene
在文件的安排上做了一些努力,比如使用索引
/
信息文件的方式,从文件安排的形式上提高查找的效率。这是一种数据库之外的处理方法,其有其优点(格式平台独立、速度快),也有其缺点(独立性带来的共享访问接口问题等等),具体如何衡量两种方法之间的利弊,本文这里就不讨论了。
三、
一些公用的基础类
分析完索引文件格式,我们接下来应该着手对存储抽象也就是
org.apache.lucenestore
中的源码做一些分析。我们先不着急分析这部分,而是分析图
2.1
中基础结构封装那一部分,因为这是整个系统的基石,然后我们在下一部分再来分析存储抽象。
基础结构封装,或者基础类,由
org.apache.lucene.util
和
org.apache.lucene.document
两个包组成,前者定义了一些常量和优化过的常用的数据结构和算法,后者则是对于文档(
document
)和域(
field
)概念的一个类定义。以下我们用列表的方式来分析这些封装类,指出其要点。
表
3.2
基础类包
org.apache.lucene.util
|
类
|
说明
|
|
Arrays
|
一个关于数组的排序方法的静态类,提供了优化的基于快排序的排序方法
sort
|
|
BitVector
|
C/C++
语言中位域的
java
实现品,但是加入了序列化能力
|
|
Constants
|
常量静态类,定义了一些常量
|
|
PriorityQueue
|
一个优先队列的抽象类,用于后面实现各种具体的优先队列,提供常数时间内的最小元素访问能力,内部实现机制是哈析表和堆排序算法
|
表
3.3
基础类包
org.apache.lucene.document
|
类
|
说明
|
|
Document
|
是文档概念的一个实现类,每个文档包含了一个域表(
fieldList
),并提供了一些实用的方法,比如多种添加域的方法、返回域表的迭代器的方法
|
|
Field
|
是域概念的一个实现类,每个域包含了一个域名和一个值,以及一些相关的属性
|
|
DateField
|
提供了一些辅助方法的静态类,这些方法将
java
中
Date
和
Time
数据类型和
String
相互转化
|
总的来说,这两个基础类包中含有的类都比较简单,通过阅读源代码,可以很容易的理解,因此这里不作过多的展开。
四、
存储抽象
有了上面的知识,我们接下来来分析存储抽象部分,也就是
org.apache.lucene.store
包。存储抽象是唯一能够直接对索引文件存取的包,因此其主要目的是抽象出和平台文件系统无关的存储抽象,提供诸如目录服务(增、删文件)、输入流和输出流。在分析其实现之前,首先我们看一下
UML[22]
图。
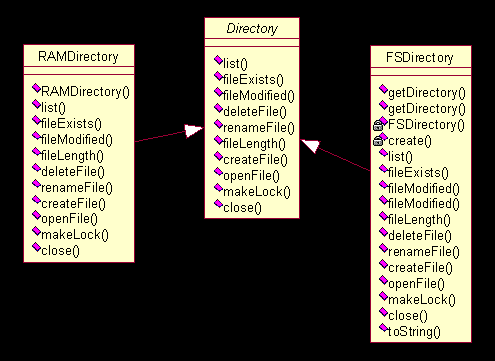
图
3.3
存储抽象实现
UML
图(一)
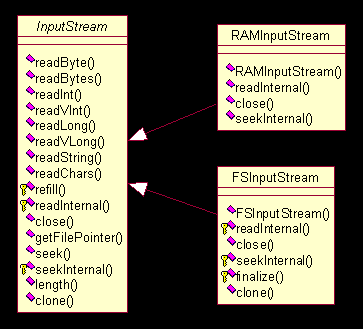
图
3.4
存储抽象实现
UML
图(二)

图
3.4
存储抽象实现
UML
图(三)
图
3.2
到
3.4
展示了整个
org.apache.lucene.store
中主要的继承体系。共有三个抽象类定义:
Directory
、
InputStream
和
OutputStrem
,构成了一个完整的基于抽象文件系统的存取体系结构,在此基础上,实作出了两个实现品:(
FSDirectory
,
FSInputStream
,
FSOutputStream
)和(
RAMDirectory
,
RAMInputStream
和
RAMOutputStream
)。前者是以实际的文件系统做为基础实现的,后者则是建立在内存中的虚拟文件系统。前者主要用来永久的保存索引文件,后者的作用则在于索引操作时是在内存中建立小的索引,然后一次性的输出合并到文件中去,这一点我们在后面的索引逻辑部分能够看到。此外,还定以了
org.apache.lucene.store.lock
和
org.apache.lucene.store.with
两个辅助内部实现的类用在实现
Directory
方法的
makeLock
的时候,以在锁定索引读写之前来让客户程序做一些准备工作。
(
FSDirectory
,
FSInputStream
,
FSOutputStream
)的内部实现依托于
java
语言中的
io
类库,只是简单的做了一个外部逻辑的包装。这当然要归功于
java
语言所提供的跨平台特性,同时也带了一些隐患:文件存取的效率提升需要依耐于文件类库的优化。如果需要继续优化文件存取的效率,应该还提供一个文件与目录的抽象,以根据各种文件系统或者文件类型来提供一个优化的机会。当然,这是应用开发者所不需要关系的问题。
(
RAMDirectory
,
RAMInputStream
和
RAMOutputStream
)的内部实现就比较直接了,直接采用了虚拟的文件
RAMFile
类(定义于文件
RAMDirectory.java
中)来表示文件,目录则看作一个
String
与
RAMFile
对应的关联数组。
RAMFile
中采用数组来表示文件的存储空间。在此的基础上,完成各项操作的实现,就形成了基于内存的虚拟文件系统。因为在实际使用时,并不会牵涉到很大字节数量的文件,因此这种设计是简单直接的,也是高效率的。
这部分的实现在理清楚继承体系后,相当的简单。因此接下来的部分,我们可以通过直接阅读源代码解决。接下来我们看看这个部分的源代码如何在实际中使用的。
一般来说,我们使用的是抽象类提供的接口而不是实际的实现类本身。在实现类中一般都含有几个静态函数,比如
createFile
,它能够返回一个
OutputStream
接口,或者
openFile
,它能够返回一个
InputStream
接口,利用这些接口之中的方法,比如
writeString
,
writeByte
等等,我们就能够在抽象的层次上处理
Lucene
定义的数据类型的读写。简单的说,
Lucene
中存储抽象这部分设计时采用了工厂模式(
Factory parttern
)
[23]
。我们利用静态类的方法也就是工厂来创建对象,返回接口,通过接口来执行操作。
五、
关于cLucene项目
这一部分详细的说明了
Lucene
系统中所采用的索引文件格式、一些基础类和存储抽象。接下来我们来叙述一下我们在项目
cLucene
中重新实现这些结构时候的一些考虑。
cLucene
彻底的遵守了
Lucene
所定义的索引文件格式,这是
Lucene
对于各个兼容系统的基本要求。在此基础上,
cLucene
系统和
Lucene
系统才能够共享索引文件数据。或者说,
cLucene
生成的索引文件和
Lucene
生成的索引文件完全等价。
在基础类问题上,
cLucene
同样封装了类似的结构。我们同样列表描述,请和前面的表
3.2
与
3.3
对照比较。
表
3.4
基础类包
cLucene::util
|
类
|
说明
|
|
Arrays
|
没有实现,直接利用了
STL
库中的快排序算法实现
|
|
BitVector
|
C/C++
语言版本的实现,与
java
实现版本类似
|
|
Constants
|
常量静态类,定义了一些常量,但是与
java
版本不同的是,这里主要定义了一些宏
|
|
PriorityQueue
|
这是一个类型定义,直接利用
STL
库中的
std::priority_queue
|
表
3.3
基础类包
cLucene::document
|
类
|
说明
|
|
Document
|
C/C++
语言版本的实现,与
java
实现版本类似
|
|
Field
|
C/C++
语言版本的实现,与
java
实现版本类似
|
|
DateField
|
没有实现,直接利用
OpenTop
库中的
ot::StringUtil
|
存储抽象的实现上,也同样是类似于
java
实现。由于我们采用了
OpenTop
库,因此同样得以借助其中对于文件系统抽象的
ot::io
包来解决文件系统问题。这部分问题与前面一样,存在优化的可能。在实现的类层次上、对外接口上,均与
java
版本的一样。
一、
绪论
这一个部分,我们将分析
Lucene
中的索引构建逻辑模块。它与前面介绍的存储抽象一起构成了
Lucene
的索引核心部分。无论是对外接口中的查询,还是分析各种文本以进一步生成索引,都需要直接调用这部分来获得对索引文件的访问能力,因此,这部分在系统中至关重要。构建一个高效的、易使用的索引构建逻辑,即是
Lucene
在这一部分需要达到的目的。
从面向对象的经典思考方式出发来看,我们只需要使用继承体系来表达图
3.1
中的各个概念,就可以通过这个继承体系来控制索引文件的结构,然后设计合适的永久化方法,以及接受分析
token
流的操作,即可将索引构建逻辑完成。原理上就是这样的简单。由于两个关键的概念
document
和
field
都已经在
org.apache.lucene.document
中当作基础类定义过了,因此实际上
Lucene
在这部分需要完善的概念结构还有
segment
和
term
。在此基础上继续编写各个逻辑结构的永久化方法,然后提供一个进入的接口方法,即是宣告完成了这个过程。其中永久化的部分,
Lucene
使用了另外实现一个代理类的方式来实现,即对于某个类
X
,存在
XWriter
类和
XReader
类来负责写出和读入的功能;用作永久化功能的类是被永久化的类的友元。
在接下来的分析过程中,我们按照这样一个思路,以
UML
图和对象体系的描述来叙述这部分的设计和实现,然后通过内部的数据流理清楚调用时序。
二、
对象体系与UML图
1
. 项(Term)
这部分主要是分析针对项(
Term
)这个概念所做的设计,包括概念所实际涉及的类、永久化类。首先,我们从图
3.2
和阅读参考文献
3
知道,项(
Term
)所表示的是一个字符串,它拥有域、频数和位置信息等等属性。因此,
Lucene
中设计了两个类来表示这个概念,如下图
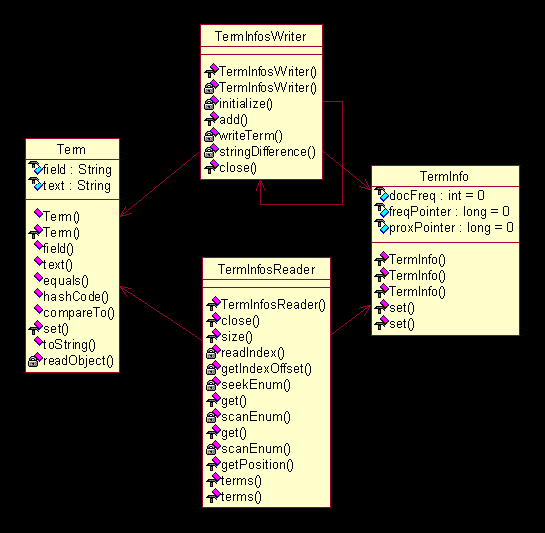
图
4.1 UML
图(-)
上图中,有意的突出了类
Term
和
TermInfo
中的数据成员,因为它反映了对于项(
Term
)这个概念的具体表示。同时上图中也同时列出了用于永久化项(
Term
)的代理类
TermInfosWriter
和
TermInfosReader
,它们完成永久化的功能,需要注意的是,
TermInfosReader
内部使用了数组
indexTerms
和
indexInfos
来存储一系列项;而
TermInfosWriter
则是一个类似于链表的结构,通过一个
other
指向下一个
TermInfosWriter
,每一个
TermInfosWriter
只负责本身那个
lastTerm
和
lastTi
的永久化工作。这是一个设计上的技巧,通过批量读取(或者称为缓冲的方式)来获得读入时候的效率优化;而通过一个链表式的、各负其责的方式,来获得写出时候的设计简化。
项(
term
)这部分的设计中,还有一些重要的接口和类,我们先介绍如下,同样我们也先展示
UML
图
图
4.2 UML
图(二)
图
4.2
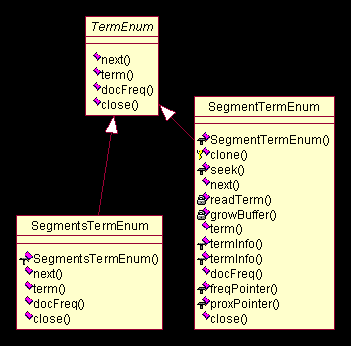
中,我们看到三个类:
TermEnum
、
TermDocs
与
TermPositions
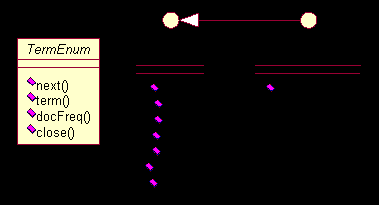
,第一个是抽象类,后两个都是接口。
TermEnum
的设计主要用在后面
Segment
和
Document
等等的实现中,以提供枚举其中每一个项(
Term
)的能力。
TermDocs
是一个接口,用来继承以提供返回
<document, frequency>
值对的能力,通过这个接口就可以获得某个项(
Term
)在某个文档中出现的频数。
TermPositions
则是在
TermDocs
上的扩展,将项(
Term
)在文档中的位置信息也表示出来。
TermDocs
(
TermPositions
)接口的使用方式类似于
java
中的
Enumration
接口,即通过
next
方法跳转,通过
doc
,
freq
等方法获得当前的属性值。
2
. 域(Field)
由于
Field
的基本概念在
org.apache.lucene.document
中已经做了定义,因此在这部分主要是针对项文件(
.fnm
文件、
.fdx
文件、
.fdt
文件)所需要的信息再来设计一些类。
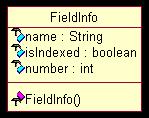
图
4.3 UML
图(三)
图
4.3
中展示的,就是表示与域(
Field
)所关联的属性信息的类。其中
isIndexed
表示的这个域的值是否被索引过,即值是否被分词然后索引;另外两个属性所表示的意思则很明显:一个是域的名字,一个是域的编号。
接下来我们来看关于域表和存取逻辑的
UML
图。
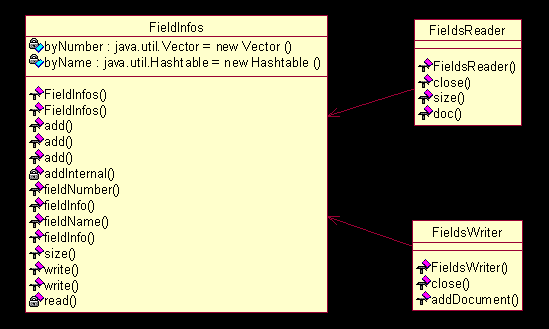
图
4.4 UML
图(四)
FieldInfos
即为域表的概念表示,内部采用了冗余的方式以获取在通过域的编号访问或者通过域的名字来访问时候的高效率。
FieldsReader
与
FieldsWriter
则分别是写出和读入的代理类。在功能和实现上,这两个类都比较简单。至于
FieldInfos
中采用的冗余方式,则是基于域的数目相对比较少而做出的一种折衷处理。
3
. 文档(document)
文档(
document
)同样也是在
org.apache.lucene.document
中定义过的结构。由于对于这部分比较重要,我们也来看看其
UML
图。
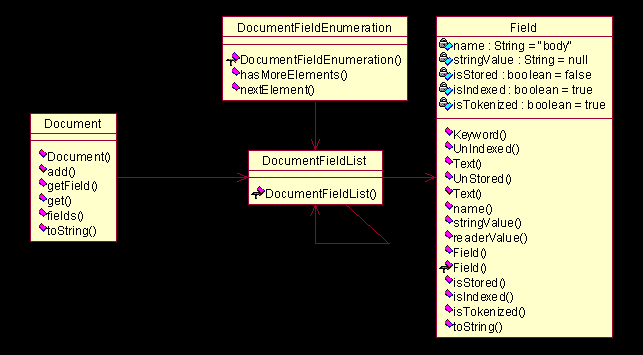
图
4.5 UML
图(五)
在图
4.5
中我们看到,
Document
的设计基本上沿用了链表的处理方法。左边的
Document
类作为一个数据外包类,用来提供对于内部结构
DocumentFieldList
的增加删除访问操作等等。
DocumentFieldList
才是实际上的数据存储单位,它用了链表的处理方法,直接指向一个当前的
Field
对象和下一个
DocumentFieldList
对象,这个与前面的类似。为了能够逐个访问链表中的节点,还设计了
DocumentFieldEnumeration
枚举类。

图
4.6 UML
图(六)
实际上定义于
org.apache.lucene.index
中的有关于
Document
的就是永久化的代理类。在图
4.6
中给出了其
UML
图。需要说明的是为什么没有出现读入的方法:这个方法已经隐含在图
4.5
中
Document
类中的
add
方法中了,结合图
2.4
中的程序代码段,我们就能够清楚的理解这种设计。
4
. 段(segment)
段(
Segment
)这一部分设计的比较特殊,在实现简单的对象结构之上,还特意的设计了用于段之间合并的类。接下来,我们仍然采取对照
UML
分析的方式逐个叙述。接下来我们看
Lucene
中如何表示段这个概念。
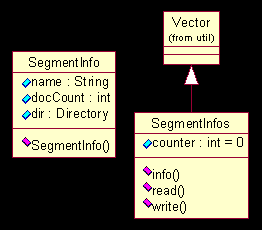
图
4.7 UML
图(七)
Lucene
定义了一个类
SegmentInfo
用来表示每一个段(
Segment
)的信息,包括名字(
name
)、含有的文档的数目(
docCount
)和段所位于的目录的位置(
dir
)。根据索引文件中的段的意义,有了这三点,就能唯一确定一个段了。
SegmentInfos
这个类则是用来表示一个段的链表(从标准的
java.util.Vector
继承而来),实际上,也就是索引(
index
)的意思了。需要注意的是,这里并没有在
SegmentInfo
中安插一个文档(
document
)的链表。这样做的原因牵涉到
Lucene
内部对于文档(相当于一个被索引文件)的处理;
Lucene
内部采用了赋予文档编号,给域赋值的方式来处理文档,即加入的文档顺次编号,以后用文档号表示文档,而路径信息,文件名字等等在以后索引查找需要的属性,都作为域存储下来;因此
SegmentInfo
中并没有另外存储一个文档(
document
)的链表,对于这些的写出和读入,则交给了永久化的代理类来做。
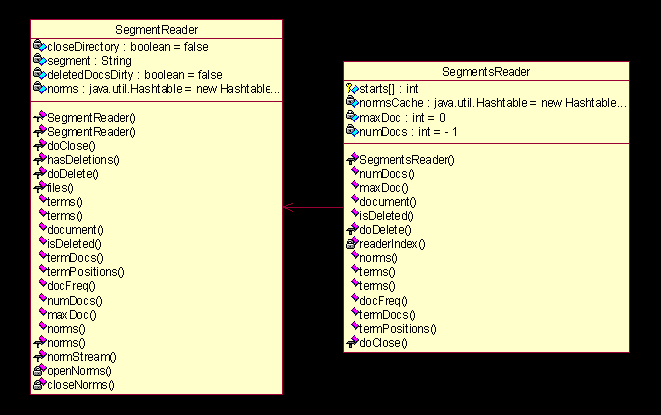
图
4.8 UML
图(八)
图
4.8
给出了负责段(
segment
)的读入操作的代理类,而负责段(
segment
)的写出操作也同样没有定义,这些操作都直接实现在了类
IndexWriter
类中(后面会详细分析)。段的操作同样采用了之前的数组或者说是缓冲的处理方式,相关的细节也不在这里详细叙述了。
然后,针对前面项(
term
)那部分定义的几个接口,段(
segment
)这部分也需要做相应的接口实现,因为提供直接遍历访问段中的各个项的能力对于检索来说,无疑是十分重要的。即这部分的设计,实际上都是在为了检索在服务。
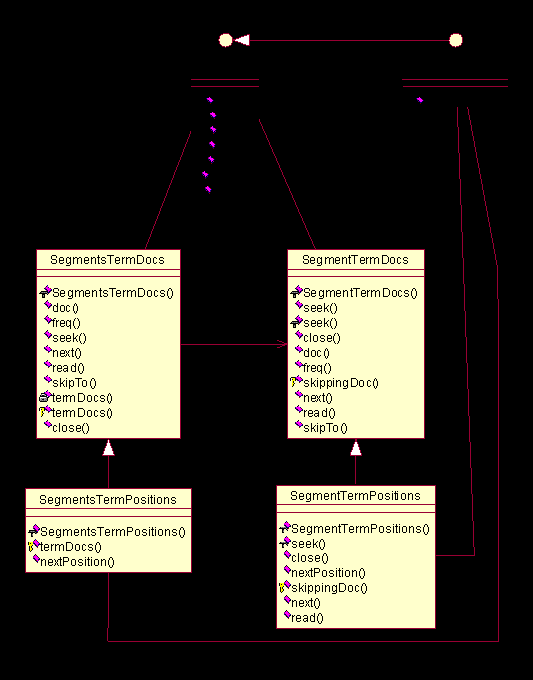
图
4.9 UML
图(九)
图
4.10 UML
图(十)
图
4.9
和图
4.10
分别展示了前面项(
term
)那里定义的接口是如何在这里通过继承实现的。
Lucene
在处理这部分的时候,也是分成两部分(
Segment
与
Segments
开头的类)来实现,而且很合理的运用了数组的技法,以及注意了继承重用。但是细化到局部,终归是比较简单的按照语义来获得结果而已了,因此关于更多的也就不多做分析了,我们完全可以通过阅读源代码来解决。
接下来所介绍的,就是在
Lucene
的设计过程中比较特殊的一个部分:段合并类(
SegmentMerger
)。这首先需要介绍
Lucene
中的建立索引时的段合并策略。
Lucene
为了兼顾建立索引时的效率和读取索引查找的速度,引入了分小段建立索引的方式,即每一次批量建立索引时,先在内存中的虚拟文件系统中为每一个文档单独建立一个段,然后在输出的时候将这些段合并之后输出成为索引文件,这时仅仅存在一个段。多次建立的索引后,如果想优化索引文件,也可采取合并段的方法,将索引中的段合并成为一个段。我们来看一下在
IndexWriter
类中相应的方法的实现,来了解一下这中建立索引的实现。

对于上面的代码,我们不做过多注释了,结合源码中的注解应该很容易理解。在最后那个
mergeSegments
函数中,将用到几个重要的类结构,它们记录了合并时候的一些重要信息,完成合并时候的工作。接下来,我们来看这几个类的
UML
图。
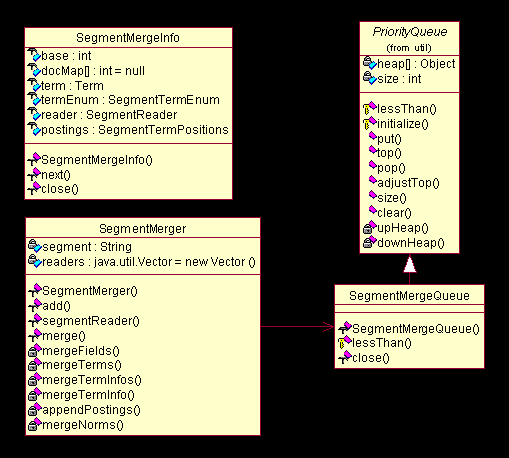
图
4.12 UML
图(十一)
从图
4.12
中,我们看到
Lucene
设计一个类
SegmentMergeInfo
用来保存每一个被合并的段的信息,也保存能够访问其内部的接口句柄,也就是说合并时的操作使用这个类作为对被合并的段的操作代理。类
SegmentMergeQueue
则设计为
org.apache.lucene.util.PriorityQueue
的子类,做为
SegmentMergeInfo
的容器类,而且附带能够自动排序。
SegmentMerger
是主要进行操作的类,里面各个方法环环相扣,分别完成合并各个数据项的问题。
5
. IndexReader类与IndexWirter类
最后剩下的,就是整个索引逻辑部分的使用接口类了。外界通过这两个类以及文档(
document
)类的构造函数调用之,比如图
2.4
中的代码示例所示。下面我们来看一下这部分最后两个类的
UML
图。

图
4.13 UML
图(十二)
IndexWriter
的设计与
IndexReader
的设计很不相同,前者是一个实现类,而后者是一个抽象类,带有没有实现的接口。
IndexWriter
的主要作用就是接收新加入的文档(
document
),然后在内部为之生成相应的小段,最后再合并并向索引文件中输出,图
4.11
中已经给出了一些实现的代码。由于
Lucene
在面向对象上封装的努力,通过各个构造函数就已经完成了对于各个概念的构造过程,剩下部分的代码主要是依据各个数组或者是链表中的信息,逐个逐个的将信息写出到相应的文件中去了。
IndexReader
部分则只是做了接口设计,没有具体的实现,这个和本部分所完成的主要功能有关:索引构建逻辑。设计这个抽象类的目的是,预先完成一些函数,为以后的检索(
search
)部分的各种形式的
IndexReader
铺平道路,也是利用了在同一个包内可以方便访问其它类的保护变量这个
java
语言的限制。
到此,在索引构建逻辑部分出现的类我们就分析完毕了,需要说明主要是做的一个宏观上的组成结构上的分析,并指出一些实现上的要点。具体的实现,由于
Lucene
的开放源码而显得并不是非常的重要,因为
Lucene
在做到良好的面相对象设计之后,实际带来的是局部复杂性的减小,因此某一些单独的函数或者实现就比较容易编写,也容易让人阅读。本文不再继续叙述这方面的细节,作为一个总结,下一个部分我们通过索引构建逻辑的数据流图的方式,再来理清楚一下索引构建逻辑这部分的调用时序。
三、
数据流逻辑
从宏观上明白一个系统的设计,理清楚其中的运行规律,最好的方式应该是通过数据流图。在分析了各个位于索引构建逻辑部分的类的设计之后,我们接下来就通过分析数据流图的方式来总结一下。但是由于之前提到的原因:索引读入部分在这一部分并没有完全实现,所以我们在数据流图中主要给出的是索引构建的数据流图。
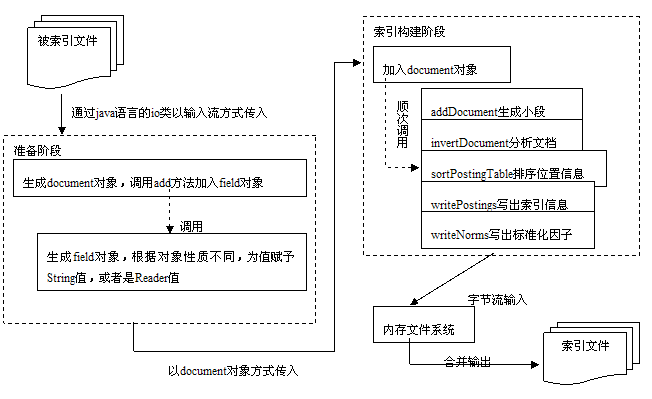
对于图
4.14
中所描述的内容,结合
Lucene
源代码中的一些文件看,能够加深理解。准备阶段可以参考
demo
文件夹中的
org.apache.lucene.demo.IndexFiles
类和
java
文件夹中的
org.apache.lucene.document
文件包。索引构建阶段的主要源码位于
java
文件夹中
org.apache.lucene.index.IndexWriter
类,因此这部分可以结合这个类的实现来看。至于内存文件系统,比较复杂,但是这时的逻辑相对简单,因此也不难理解。
上面的数据流图十分清楚的勾画除了整个索引构建逻辑这部分的设计:通过层层嵌套的类结构,在构建时候即分步骤有计划的生成了索引结构,将之存储到内存中的文件系统中,然后通过对内存中的文件系统优化合并输出到实际的文件系统中。
四、
关于cLucene项目
前面的三个部分,已经完成了分析索引构建逻辑的任务,这里我们还是有针对性的谈谈我们这次的毕业设计项目
cLucene
在这一部分的情况。
在实现这部分的时候,为了将一些
java
语法中比较特殊的部分,比如内隐类、同步函数、同步对象等等,我们不得不采用了一些比较晦涩和艰深的
C++
语法,在
OpenTop
这个类库所提供的类似于
java
语言的设施上来实现。这个尤其体现在实现
Segment
相关类时,为了处理原来
java
源代码中用内隐类实现的
Lock
文件创建机制的时候,我们不得不定义了大量的
cLucene::store::With
的子类,并为之传入调用类的指针,设置它为调用类的友元,才得以精确的模拟了原有的语义。陷于我们这次的重写以移植为主,系统结构基本上没有大的变化,不得不产生这种重复而且大量的工作。如果需要改进这中状况,我们应该考虑按照
C++
语言的特点来设计索引构建部分的类库继承结构,但是很可惜在本文成文之前,时间不允许我们这样做。
来自
java
语法的特殊性只是我们解决问题的一个方面,我们还需要处理引用的调用方式。由于
java
语言拥有了垃圾收集机制,因此得以将一切的参数形式看作为引用,而不考虑其分配与消亡的问题。
C++
语言并不具备这种机制,它需要程序员自行管理分配空间与销毁对象的问题。在这里,我们使用的是来自
OpenTop
中所引入的计数指针
RefPtr<>
模板,它能够模拟指针的语义,并且计算指针被引用的次数,在引用次数为
0
时就自动释放资源:这是一种类似于
java
语言中引用的方式,不过它显得更加高效率。我们在
cLucene
的实现中大量的使用了计数指针模板。
除此之外,我们没有改变
Lucene
所定义的索引构建逻辑的结构和语义,我们实现的是一个完全和
java
版本
Lucene
兼容的版本。
Lucene
Doug Cutting
cutting@apache.org
November 24 2004
University of Pisa
cutting@apache.org
November 24 2004
University of Pisa
Prelude
- my background..
- please interrupt with questions
- blog this talk now so that we can search for it later
(using a Lucene-based blog search engine, of course) - In this course, Paolo and Antonio have presented many techniques.
- I present real software that uses many of these techniques.
Lucene is
- software library for search
- open source
- not a complete application
- set of java classes
- active user and developer communities
- widely used, e.g, IBM and Microsoft.
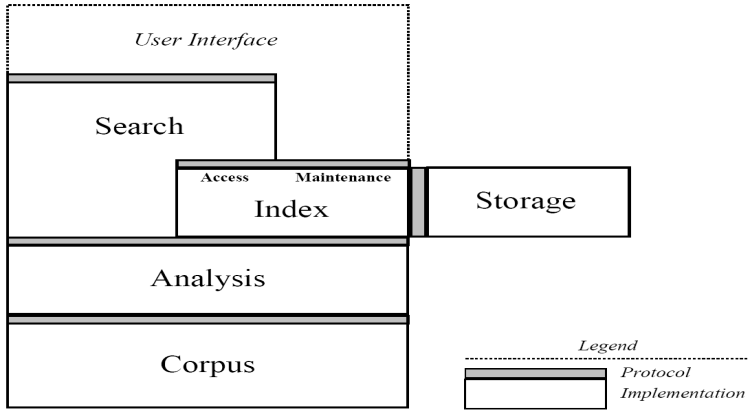
Lucene Architecture
[draw on whiteboard for reference throughout talk]
Lucene API
- org.apache.lucene.document
- org.apache.lucene.analysis
- org.apache.lucene.index
- org.apache.lucene.search
Package: org.apache.lucene.document
- A Document is a sequence of Fields.
- A Field is a <name, value> pair.
- name is the name of the field, e.g., title, body, subject, date, etc.
- value is text.
- Field values may be stored, indexed or analyzed (and, now, vectored).
Example
public Document makeDocument(File f) throws FileNotFoundException {
Document doc = new Document();
doc.add(new Field("path", f.getPath(), Store.YES, Index.TOKENIZED));
doc.add(new Field("modified",
DateTools.timeToString(f.lastModified(), Resolution.MINUTE),
Store.YES, Index.UN_TOKENIZED));
// Reader implies Store.NO and Index.TOKENIZED
doc.add(new Field("contents", new FileReader(f)));
return doc;
}
Document doc = new Document();
doc.add(new Field("path", f.getPath(), Store.YES, Index.TOKENIZED));
doc.add(new Field("modified",
DateTools.timeToString(f.lastModified(), Resolution.MINUTE),
Store.YES, Index.UN_TOKENIZED));
// Reader implies Store.NO and Index.TOKENIZED
doc.add(new Field("contents", new FileReader(f)));
return doc;
}
Example (continued)
|
field
|
stored
|
indexed
|
analyzed
|
|
path
|
yes
|
yes
|
yes
|
|
modified
|
yes
|
yes
|
no
|
|
content
|
no
|
yes
|
yes
|
Package: org.apache.lucene.analysis
- An Analyzer is a TokenStream factory.
- A TokenStream is an iterator over Tokens.
- input is a character iterator (Reader)
- A Token is tuple <text, type, start, length, positionIncrement>
- text (e.g., “pisa”).
- type (e.g., “word”, “sent”, “para”).
- start & length offsets, in characters (e.g, <5,4>)
- positionIncrement (normally 1)
- standard TokenStream implementations are
- Tokenizers, which divide characters into tokens and
- TokenFilters, e.g., stop lists, stemmers, etc.
Example
public
class ItalianAnalyzer extends Analyzer {
private Set stopWords =
StopFilter.makeStopSet(new String[] {"il", "la", "in"};
public TokenStream tokenStream(String fieldName, Reader reader) {
TokenStream result = new WhitespaceTokenizer(reader);
result = new LowerCaseFilter(result);
result = new StopFilter(result, stopWords);
result = new SnowballFilter(result, "Italian");
return result;
}
}
StopFilter.makeStopSet(new String[] {"il", "la", "in"};
public TokenStream tokenStream(String fieldName, Reader reader) {
TokenStream result = new WhitespaceTokenizer(reader);
result = new LowerCaseFilter(result);
result = new StopFilter(result, stopWords);
result = new SnowballFilter(result, "Italian");
return result;
}
}
Package: org.apache.lucene.index
- Term is <fieldName, text>
- index maps Term → <df, <docNum, <position>* >*>
- e.g., “content:pisa” → <2, <2, <14>>, <4, <2, 9>>>
- new: term vectors!
Example
IndexWriter writer = new IndexWriter("index", new ItalianAnalyzer());
File[] files = directory.listFiles();
for (int i = 0; i < files.length; i++) {
writer.addDocument(makeDocument(files[i]));
}
writer.close();
File[] files = directory.listFiles();
for (int i = 0; i < files.length; i++) {
writer.addDocument(makeDocument(files[i]));
}
writer.close();
Some Inverted Index Strategies
- batch-based: use file-sorting algorithms (textbook)
+
fastest to build
+ fastest to search
- slow to update
+ fastest to search
- slow to update
- b-tree based: update in place (http://lucene.sf.net/papers/sigir90.ps)
+
fast to search
- update/build does not scale
- complex implementation
- update/build does not scale
- complex implementation
- segment based: lots of small indexes (Verity)
+
fast to build
+ fast to update
- slower to search
+ fast to update
- slower to search
Lucene's Index Algorithm
- two basic algorithms:
- make an index for a single document
- merge a set of indices
- incremental algorithm:
- maintain a stack of segment indices
- create index for each incoming document
- push new indexes onto the stack
- let b=10 be the merge factor; M=∞
for (size = 1; size < M; size *= b) {
if (there are b indexes with size docs on top of the stack) {
pop them off the stack;
merge them into a single index;
push the merged index onto the stack;
} else {
break;
}
}
- optimization: single-doc indexes kept in RAM, saves system calls
- notes:
- average b*logb(N)/2 indexes
- N=1M, b=2 gives just 20 indexes
- fast to update and not too slow to search
- batch indexing w/ M=∞, merge all at end
- equivalent to external merge sort, optimal
- segment indexing w/ M<∞
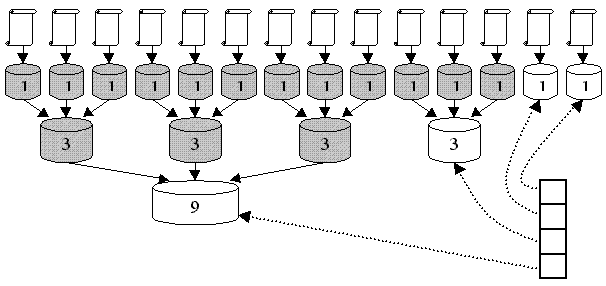
Indexing Diagram
- b = 3
- 11 documents indexed
- stack has four indexes
- grayed indexes have been deleted
- 5 merges have occurred
Index Compression
For keys in Term -> ... map, use technique from Paolo's slides:

For values in Term -> ... map, use technique from Paolo's slides:

For values in Term -> ... map, use technique from Paolo's slides:
VInt Encoding Example
|
Value
|
First byte
|
Second byte
|
Third byte
|
|
0
|
00000000
|
|
|
|
1
|
00000001
|
|
|
|
2
|
00000010
|
|
|
|
...
|
|
|
|
|
127
|
01111111
|
|
|
|
128
|
10000000
|
00000001
|
|
|
129
|
10000001
|
00000001
|
|
|
130
|
10000010
|
00000001
|
|
|
...
|
|
|
|
|
16,383
|
11111111
|
01111111
|
|
|
16,384
|
10000000
|
10000000
|
00000001
|
|
16,385
|
10000001
|
10000000
|
00000001
|
|
...
|
|
|
|
This provides compression while still being efficient to decode.
Package: org.apache.lucene.search
- primitive queries:
- TermQuery: match docs containing a Term
- PhraseQuery: match docs w/ sequence of Terms
- BooleanQuery: match docs matching other queries.
e.g., +path:pisa +content:“Doug Cutting” -path:nutch
- new: SpansQuery
- derived queries:
- PrefixQuery, WildcardQuery, etc.
Example
Query pisa = new TermQuery(new Term("content", "pisa"));
Query babel = new TermQuery(new Term("content", "babel"));
PhraseQuery leaningTower = new PhraseQuery();
leaningTower.add(new Term("content", "leaning"));
leaningTower.add(new Term("content", "tower"));
BooleanQuery query = new BooleanQuery();
query.add(leaningTower, Occur.MUST);
query.add(pisa, Occur.SHOULD);
query.add(babel, Occur.MUST_NOT);
Query babel = new TermQuery(new Term("content", "babel"));
PhraseQuery leaningTower = new PhraseQuery();
leaningTower.add(new Term("content", "leaning"));
leaningTower.add(new Term("content", "tower"));
BooleanQuery query = new BooleanQuery();
query.add(leaningTower, Occur.MUST);
query.add(pisa, Occur.SHOULD);
query.add(babel, Occur.MUST_NOT);
Search Algorithms
From Paolo's slides:

Lucene's Disjunctive Search Algorithm
- described in http://lucene.sf.net/papers/riao97.ps
- since all postings must be processed
- goal is to minimize per-posting computation
- merges postings through a fixed-size array of accumulator buckets
- performs boolean logic with bit masks
- scales well with large queries
[ draw a diagram to illustrate? ]
Lucene's Conjunctive Search Algorithm
From Paolo's slides:

Algorithm
Algorithm
- use linked list of pointers to doc list
- initially sorted by doc
- loop
- if all are at same doc, record hit
- skip first to-or-past last and move to end of list
Scoring
From Paolo's slides:

Is very much like Lucene's Similarity.
Is very much like Lucene's Similarity.
Lucene's Phrase Scoring
- approximate phrase IDF with sum of terms
- compute actual tf of phrase
- slop penalizes slight mismatches by edit-distance
Thanks!
And there's lots more to Lucene.
Check out http://jakarta.apache.org/lucene/.
Finally, search for this talk on Technorati.
Check out http://jakarta.apache.org/lucene/.
Finally, search for this talk on Technorati.
LUCENE.COM.CN
中国
本文主要讨论Lucene的系统结构,希望对其结构的初步分析,更深入的了解Lucene的运作机制,从而实现对Lucene的功能扩展。
1.
1
.
Lucene
的包结构
如上图所示,Lucene源码中共包括7个子包,每个包完成特定的功能:
|
Lucene
包结构功能表
| |
|
包名
|
功能
|
|
org.apache.lucene.analysis
|
语言分析器,主要用于的切词,支持中文主要是扩展此类
|
|
org.apache.lucene.document
|
索引存储时的文档结构管理,类似于关系型数据库的表结构
|
|
org.apache.lucene.index
|
索引管理,包括索引建立、删除等
|
|
org.apache.lucene.queryParser
|
查询分析器,实现查询关键词间的运算,如与、或、非等
|
|
org.apache.lucene.search
|
检索管理,根据查询条件,检索得到结果
|
|
org.apache.lucene.store
|
数据存储管理,主要包括一些底层的I/O操作
|
|
org.apache.lucene.util
|
一些公用类
|
2.
2
.
Lucene
的主要逻辑图
Lucene功能强大,但从根本上说,主要包括两块:一是文本内容经切词后索引入库;二是根据查询条件返回结果。
以下是上述两大功能的逻辑图:
|
|
|
|
|
|
|
|
|
|
|
|
查询逻辑
按先后顺序,查询逻辑可分为如下几步:
1. 1. 查询者输入查询条件
条件之间可以通过特定运算符进行运算,比如查询希望查询到与“中国”和“北京”相关的记录,但不希望结果中包括“海淀区中关村”,于是输入条件为“中国+北京-海淀区中关村”;
条件之间可以通过特定运算符进行运算,比如查询希望查询到与“中国”和“北京”相关的记录,但不希望结果中包括“海淀区中关村”,于是输入条件为“中国+北京-海淀区中关村”;
2. 2. 查询条件被传达到查询分析器中,分析器将将对“中国+北京-海淀区中关村”进行分析,首先分析器解析字符串的连接符,即这里的加号和减号,然后对每个词进行切词,一般最小的词元是两个汉字,则中国和北京两个词不必再切分,但对海淀区中关村需要切分,假设根据切词算法,把该词切分为“海淀区”和“中关村”两部分,则最后得到的查询条件可以表示为:
“中国”
AND
“北京”
AND NOT
(“海淀区”
AND
“中关村”)。
3. 3. 查询器根据这个条件遍历索引树,得到查询结果,并返回结果集,返回的结果集类似于JDBC中的ResultSet。
4. 4. 将返回的结果集显示在查询结果页面,当点击某一条内容时,可以链接到原始网页,也可以打开全文检索库中存储的网页内容。
这就是查询的逻辑过程,需要说明的是,Lucene默认只支持英文,为了便于说明问题,以上查询过程采用中文举例,事实上,当Lucene被扩充支持中文后就是这么一个查询过程。
入库逻辑
入库将把内容加载到全文检索库中,按顺序,入库逻辑包括如下过程:
1. 1. 入库者定义到库中文档的结构,比如需要把网站内容加载到全文检索库,让用户通过“站内检索”搜索到相关的网页内容。入库文档结构与关系型数据库中的表结构类似,每个入库的文档由多个字段构成,假设这里需要入库的网站内容包括如下字段:文章标题、作者、发布时间、原文链接、正文内容(一般作为网页快照)。
2. 2. 包含N个字段的文档(DOCUMENT)在真正入库前需要经过切词(或分词)索引,切词的规则由语言分析器(ANALYZER)完成。
3. 3. 切分后的“单词”被注册到索引树上,供查询时用,另外也需要也其它不需要索引的内容入库,所有这些是文件操作均由STORAGE完成。
以上就是记录加载流程,索引树是一种比较复杂的数据存储结构,将在后续章节陆续介绍,这里就不赘述了,需要说明的一点是,Lucene的索引树结构非常优秀,是Lucene的一大特色。
接下来将对Lucene的各个子包的结构进行讨论。
3.
3
.
语言分析包org.apache.lucene.analysis
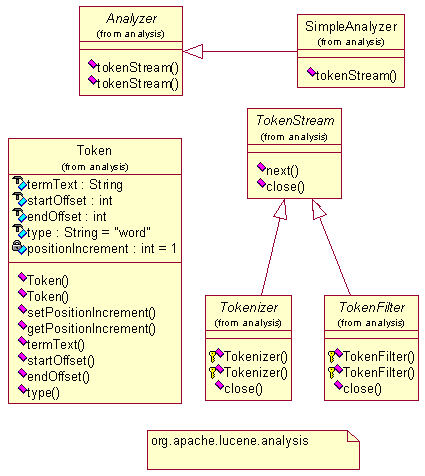
Analyzer是一个抽象类,司职对文本内容的切分词规则。
切分后返回一个TokenStream,TokenStream中有一个非常重要方法next(),即取到下一个词。简单点说,通过切词规则,把一篇文章从头到尾分成一个个的词,这就是org.apache.lucene.analysis的工作。
对英文而言,其分词规则很简单,因为每个单词间都有一个空格,按空格取单词即可,当然为了提高英文检索的准确度,也可以把一些短语作为一个整体,其间不切分,这就需要一个词库,对德文、俄文也是类似,稍有不同。
对中文而言,文字之间都是相连的,没有空格,但我们同样可以把字切分,即把每个汉字作为一个词切分,这就是所谓的“切字”,但切字方式方式的索引没有意义,准确率太低,要想提高准确度一般都是切词,这就需要一个词库,词库越大准确度将越高,但入库效率越低。
若要支持中文切词,则需要扩展Analyzer类,根据词库中的词把文章切分。
简单点说,org.apache.lucene.analysis就是完成将文章切分词的任务。
4.
4
.
文档结构包org.apache.lucene.document
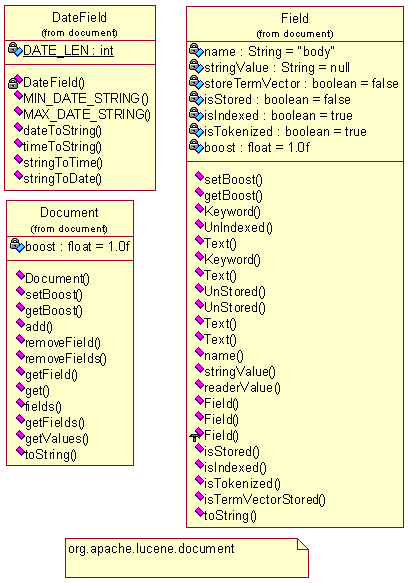
document包相对而言比较简单,该包下面就3个类,Document相对于关系型数据库的记录对象,主要负责字段的管理,字段分两种,一是Field,即文本型字段,另一个是日期型字段DateField。这个包中关键需要理解的是Field中字段存储方式的不同,这在上一篇中已列表提到,下面我们可以参见一下其详细的类图:

5.
5
.
索引管理包org.apache.lucene.index
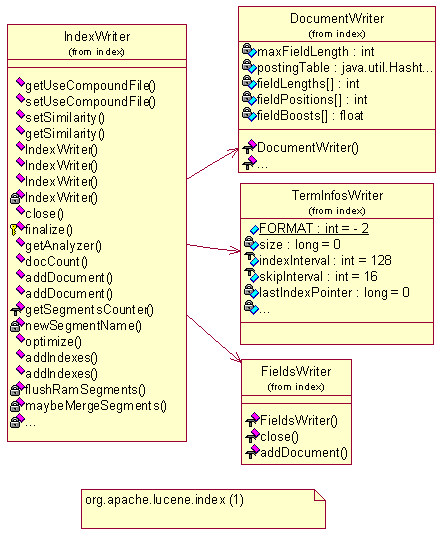
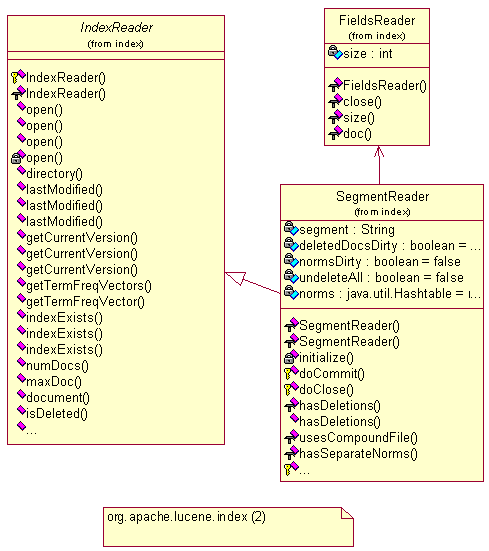
索引包是整个系统核心,全文检索的的根本就为每个切出来的词建索引,查询时就只需要遍历索引,而不需要去正文中遍历,从而极大的提高检索效率,索引建设的质量关键整个系统的质量。Lucene的索引树是非常优质高效的,具体的索引树细节,将在后续章节中重要探讨。
在这个包中,主要学习IndexWriter和IndexReader这个类。
通过上一篇的初步应用可知,全文检索库的初始化和记录加载均需要通过该类来完成。
初始化全文库的语句为:
IndexWriter
indexWriter = new IndexWriter(“
全文库的目录位置
”,
new
StandardAnalyzer(),true);
记录加载的语句为:
indexWriter.addDocument(doc);
IndexWriter
主要用于写库,当需要读取库内容时,就需要用到IndexReader这个类了。
6.
6
.
查询分析包org.apache.lucene.queryParser
和检索包org.apache.lucene.search
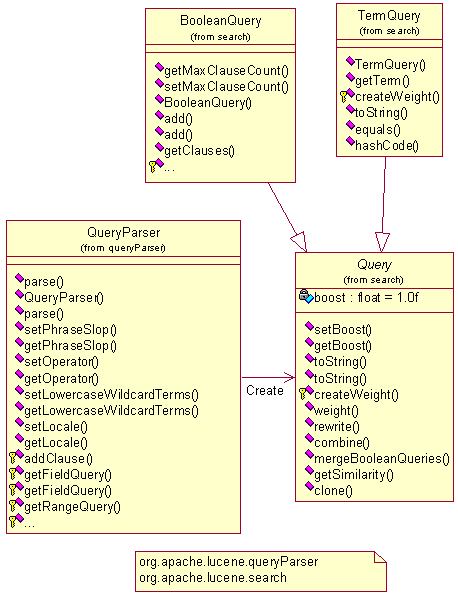
通过查询分析器(queryParser)解析后,将返回一个查询对象(query),根据查询对象就可进行检索了。上图描述了query对象的生成,下图描述了查询结果集(Hits)的生成。
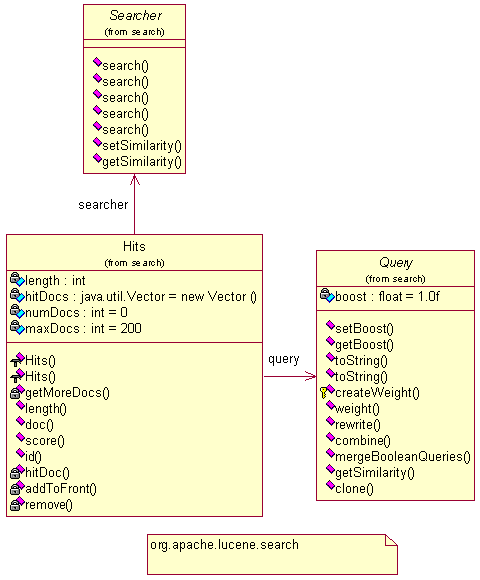
7.
7
.
存储包org.apache.lucene.store
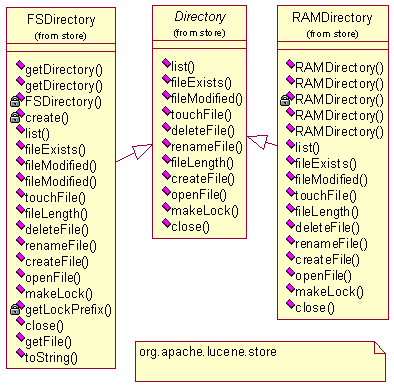
一些底层的文件I/O操作。
8.
8
.
工具包org.apache.lucene.util
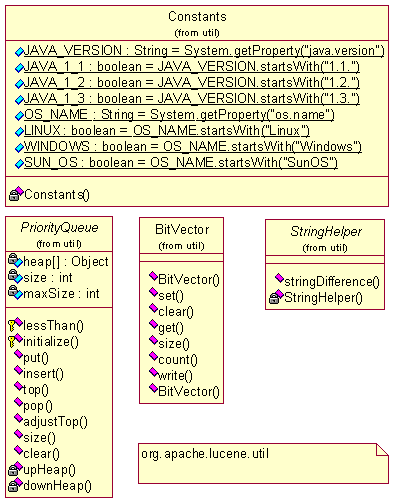
该包中包括4个工具类。
9.
9
.
总结
通过对Lucene源码包的分析,我们可以初步认识到Lucene的核心类包主要有3个:
l
l
org.apache.lucene.analysis
l
l
org.apache.lucene.index
l l
org.apache.lucene.search
其中
org.apache.lucene.analysis
主要用于切分词,切分词的工作由
Analyzer
的扩展类来实现,
Lucene
自带了
StandardAnalyzer
类,我们可以参照该写出自己的切词分析器类,如中文分析器等。
org.apache.lucene.index
主要提供库的读写接口,通过该包可以创建库、添加删除记录及读取记录等。
org.apache.lucene.search
主要提供了检索接口,通过该包,我们可以输入条件,得到查询结果集,与
org.apache.lucene.
queryParser
包配合还可以自定义的查询规则,像
google
一样支持查询条件间的与、或、非、属于等复合查询。
参考资料
Lucene
全文检索实践(
1
)
Lucene
是
Apache Jakarta
的一个子项目,是一个全文检索的搜索引擎库。其提供了简单实用的
API
,通过这些
API
,可以自行编写对文件(
TEXT
/
XML
/
HTML
等)、目录、数据库的全文检索程序。
Features
:
* Very fast indexing, minimal RAM required
* Index compression to 30% of original text
* Indexes text and HTML, document classes available for XML, PDF and RTF
* Search supports phrase and Boolean queries, plus, minus and quote marks, and parentheses
* Allows single and multiple character wildcards anywhere in the search words, fuzzy search, proximity
* Will search for punctuation such as + or ?
* Field searches for title, author, etc., and date-range searching
* Supports most European languages
* Option to store and display full text of indexed documents
* Search results in relevance order
* APIs for file format conversion, languages and user interfaces
* Very fast indexing, minimal RAM required
* Index compression to 30% of original text
* Indexes text and HTML, document classes available for XML, PDF and RTF
* Search supports phrase and Boolean queries, plus, minus and quote marks, and parentheses
* Allows single and multiple character wildcards anywhere in the search words, fuzzy search, proximity
* Will search for punctuation such as + or ?
* Field searches for title, author, etc., and date-range searching
* Supports most European languages
* Option to store and display full text of indexed documents
* Search results in relevance order
* APIs for file format conversion, languages and user interfaces
实践任务:
1) 编写 Java 程序 MyIndexer.java ,使用 JDBC 取出 MySQL 数据表内容(以某一论坛数据做测试),然后通过 org.apache.lucene.index.IndexWriter 创建索引。
2) 编写 Java 程序 MySearcher.java ,通过 org.apache.lucene.search.IndexSearcher 等查询索引。
3) 实现支持中文查询及检索关键字高亮显示。
4) 通过 PHP / Java Integration 实现对 MySearch.java 的调用。
5) 实现对 PHP 手册(简体中文) 的全文检索。
Lucene
全文检索实践(
2
)
Java
的程序基本编写完成,实现了对中文的支持。下一步是将其放到
WEB
上运行,首先想到的是使用
JSP
,安装了
Apache Tomcat/4.1.24
,默认的发布端口是
8080
。现在面临的一个问题是:
Apache httpd
的端口是
80
,并且我的机器对外只能通过
80
端口进行访问,如果将
Tomcat
的发布端口改成
80
的话,
httpd
就没法对外了,而其上的
PHP
程序也将无法在
80
端口运行。
对于这个问题,我想到两种方案:
1 、使用 PHP 直接调用 Java 。需要做的工作是使用 --with-java 重新编译 PHP ;
2 、使用 mod_jk 做桥接的方式,将 servlet 引擎结合到 httpd 中。需要做的工作是编译 jakarta-tomcat-connectors-jk-1.2.5-src ,生成 mod_jk.so 给 httpd 使用,然后按照 Howto 文档 进行 Tomcat 、 httpd 的配置。
对于第一个方案的尝试:使用 PHP 直接调用 Java
环境
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
配置步骤
1) 安装 JDK ,这个就不多说了, 到 GOOGLE 可以搜索出这方面的大量文章 。
2) 重新编译 PHP ,我的 PHP 版本是 4.3.6 :
对于这个问题,我想到两种方案:
1 、使用 PHP 直接调用 Java 。需要做的工作是使用 --with-java 重新编译 PHP ;
2 、使用 mod_jk 做桥接的方式,将 servlet 引擎结合到 httpd 中。需要做的工作是编译 jakarta-tomcat-connectors-jk-1.2.5-src ,生成 mod_jk.so 给 httpd 使用,然后按照 Howto 文档 进行 Tomcat 、 httpd 的配置。
对于第一个方案的尝试:使用 PHP 直接调用 Java
环境
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
配置步骤
1) 安装 JDK ,这个就不多说了, 到 GOOGLE 可以搜索出这方面的大量文章 。
2) 重新编译 PHP ,我的 PHP 版本是 4.3.6 :
cd php-4.3.6
./configure --with-java=/usr/local/jdk
make
make install
完成之后,会在 PHP 的 lib 下(我的是在 /usr/lib/php )有个 php_java.jar ,同时在扩展动态库存放的目录下(我的是在 /usr/lib/php/20020429 )有个 java.so 文件。到这一步需要注意一个问题,有些 PHP 版本生成的是 libphp_java.so 文件, extension 的加载只认 libphp_java.so ,直接加载 java.so 可能会出现如下错误:
PHP Fatal error: Unable to load Java Library /usr/local/jdk/jre/lib/i386/libjava.so, error: libjvm.so:
cannot open shared object file: No such file or directory in /home/nio/public_html/java.php on line 2
所以如果生成的是 java.so ,需要创建一个符号连接:
ln -s java.so libphp_java.so
3) 修改 Apache Service 启动文件(我的这个文件为 /etc/init.d/httpd ),在这个文件中加入:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/jdk/jre/lib/i386/server:/usr/local/jdk/jre/lib/i386
正如你所看到的,我的 JDK 装在 /usr/local/jdk 目录下,如果你的不是在此目录,请做相应改动(下同)。
4) 修改 PHP 配置文件 php.ini ,找到 [Java] 部分进行修改:
[Java]
java.class.path = /usr/lib/php/php_java.jar
java.home = /usr/local/jdk
;java.library =
;java.library.path =
extension_dir=/usr/lib/php/20020429/
extension=java.so
我将 java.library 及 java.library.path 都注释掉了, PHP 会自动认为 java.library=/usr/local/jdk/jre/lib/i386/libjava.so 。
5) 重新启动 Apache httpd 服务:
service httpd restart
getProperty('java.version').'<br />';
print 'Java vendor=' . $system->getProperty('java.vendor').'<br />';
print 'OS=' . $system->getProperty('os.name') . ' ' .
$system->getProperty('os.version') . ' on ' .
$system->getProperty('os.arch') . '<br />';
?>
总结
安装配置还算简单,但是在 PHP 运行 Java 的速度感觉较慢,所以下定决心开始实践第二个方案。(待续)
Lucene
全文检索实践(
3
)
今天总算有些空闲时间,正好说说第二种方案:使用
mod_jk
做桥接的方式,将
servlet
引擎结合到
httpd
中。
环境
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
* jakarta-tomcat-4.1.24 prefix=/usr/local/tomcat
* 另外需要下载 jakarta-tomcat-connectors-jk-1.2.5-src.tar.gz
配置步骤
1) 安装 JDK 与 Tomcat ,这些安装步骤就不多说了。
2) 编译 jakarta-tomcat-connectors-jk-1.2.5-src ,生成 mod_jk.so ,并将其复制到 apache 的 modules 存放目录:
环境
* PHP 4.3.6 prefix=/usr
* Apache 1.3.27 prefix=/usr/local/apache
* j2sdk1.4.1_01 prefix=/usr/local/jdk
* jakarta-tomcat-4.1.24 prefix=/usr/local/tomcat
* 另外需要下载 jakarta-tomcat-connectors-jk-1.2.5-src.tar.gz
配置步骤
1) 安装 JDK 与 Tomcat ,这些安装步骤就不多说了。
2) 编译 jakarta-tomcat-connectors-jk-1.2.5-src ,生成 mod_jk.so ,并将其复制到 apache 的 modules 存放目录:
tar xzf jakarta-tomcat-connectors-jk-1.2.5-src.tar.gz
cd jakarta-tomcat-connectors-jk-1.2.5-src/jk/native
./configure --with-apxs=/usr/local/apache/bin/apxs
make
cp apache-1.3/mod_jk.so /usr/local/apache/libexec
3) 编辑 Apache 配置文件 /usr/local/apache/conf/httpd.conf ,加入:
LoadModule jk_module libexec/mod_jk.so
AddModule mod_jk.c
这个 LoadModule 语句最好放在其他 LoadModule 语句后边。
同时在配置文件后边加入:
# workers.properties
文件所在路径,后边将对此文件进行讲解
JkWorkersFile /usr/local/apache/conf/workers.properties
# jk
的日志文件存放路径
JkLogFile /usr/local/apache/log/mod_jk.log
#
设置
jk
的日志级别
[debug/error/info]
JkLogLevel info
#
选择日志时间格式
JkLogStampFormat "[%a %b %d %H:%M:%S %Y] "
# JkOptions
选项设置
JkOptions +ForwardKeySize +ForwardURICompat -ForwardDirectories
# JkRequestLogFormat
设置日志的请求格式
JkRequestLogFormat "%w %V %T"
#
映射
/examples/*
到
worker1
,
worker1
在
workers.properties
文件中定义
JkMount /examples/* worker1
4) 在 /usr/local/apache/conf/ 目录下创建 workers.properties 文件,其内容如下:
#
定义使用
ajp13
的
worker1
worker.list=worker1
#
设置
worker1
的属性(
ajp13
)
worker.worker1.type=ajp13
worker.worker1.host=localhost
worker.worker1.port=8009
worker.worker1.lbfactor=50
worker.worker1.cachesize=10
worker.worker1.cache_timeout=600
worker.worker1.socket_keepalive=1
worker.worker1.socket_timeout=300
5) 好了,启动 Tomcat ,重启一下 Apache HTTPD Server ,访问: http://localhost/examples/index.jsp ,看看结果如何,和 http://localhost:8080/examples/index.jsp 是一样的。
提示:如果不想让别人通过 8080 端口访问到你的 Tomcat ,可以将 /usr/lcoal/tomcat/conf/server.xml 配置文件中的如下代码加上注释:
<!--
<Connector className="org.apache.coyote.tomcat4.CoyoteConnector"
port="8080" minProcessors="5" maxProcessors="75"
enableLookups="false" redirectPort="8443"
acceptCount="100" debug="0" connectionTimeout="20000"
useURIValidationHack="false" disableUploadTimeout="true" />
-->
然后重新启动 Tomcat 即可。
总结
此方案安装配置稍微复杂些,但执行效率要比第一种方案要好很多。所以决定使用这种方案来完成我的 Lucene 全文检索实践任务。
Tomcat Service
脚本
在
Linux
(我用的是
Redhat
)中,如果经常需要启动
/
关闭
Tomcat
的话,还是创建一个
daemon
来得比较方便,创建步骤如下:
1) 在 /etc/init.d/ 目录下创建文件 tomcat ,代码如下:
1) 在 /etc/init.d/ 目录下创建文件 tomcat ,代码如下:
# chkconfig: 345 91 10
# description: Tomcat daemon.
#
#
包含函数库
. /etc/rc.d/init.d/functions
#
获取网络配置
. /etc/sysconfig/network
#
检测
NETWORKING
是否为
"yes"
[ "${NETWORKING}" = "no" ] && exit 0
#
设置变量
# $TOMCAT
指向
Tomcat
的安装目录
TOMCAT=/usr/local/tomcat
# $STARTUP
指向
Tomcat
的启动脚本
STARTUP=$TOMCAT/bin/startup.sh
# $SHUTDOWN
指向
Tomcat
的关闭脚本
SHUTDOWN=$TOMCAT/bin/shutdown.sh
#
设置
JAVA_HOME
环境变量,指向
JDK
安装目录
export JAVA_HOME=/usr/local/jdk
#
启动服务函数
start() {
echo -n $"Starting Tomcat service: "
$STARTUP
RETVAL=$?
echo
}
#
关闭服务函数
stop() {
action $"Stopping Tomcat service: " $SHUTDOWN
RETVAL=$?
echo
}
#
根据参数选择调用
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo $"Usage: $0 start|stop|restart"
exit 1
esac
exit 0
2) 修改 tomcat 文件的属性
chown a+x tomcat
3) 生成 service
chkconfig --add tomcat
好了,现在可以通过 service tomcat start 命令启动 Tomcat 了,关闭及重启服务的命令也类似,只是将 start 换成 stop 或 restart 。
Lucene
全文检索实践(
4
)
在几天的研究中,了解了
Lucene
全文检索的一些原理,同时进行了实践,编写了一个论坛的全文检索创建索引程序及用于搜索的
JSP
程序,另外还写了一个
PHP 手册(简体中文)的全文检索
,可以进行多关键字搜索。基本完成了最初定下的实践任务。
Lucene
全文检索实践(
5
)
对于
Lucene
的初步研究已经过去一段时间,自己感觉还不是很深入,但由于时间的关系,一直也没再拿起。应网友的要求,将自己实践中写的一些代码贴出来,希望能对大家有用。程序没有做进一步的优化,只是很简单的实现功能而已,仅供参考。
在实践中,我以将 PHP 中文手册中的 HTML 文件生成索引,然后通过一个 JSP 对其进行全文检索。
生成索引的 Java 代码:
在实践中,我以将 PHP 中文手册中的 HTML 文件生成索引,然后通过一个 JSP 对其进行全文检索。
生成索引的 Java 代码:
/**
* PHPDocIndexer.java
*
用于对
PHPDoc
的
HTML
页面生成索引文件。
*/
import java.io.File;
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Date;
import java.text.DateFormat;
import java.lang.*;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.DateField;
class PHPDocIndexer
{
public static void main(String[] args) throws ClassNotFoundException, IOException
{
try {
Date start = new Date();
IndexWriter writer = new IndexWriter("/home/nio/indexes-phpdoc", new CJKAnalyzer(), true); //
索引保存目录,必须存在
indexDocs(writer, new File("/home/nio/phpdoc-zh")); //HTML
文件保存目录
System.out.println("Optimizing ....");
writer.optimize();
writer.close();
Date end = new Date();
System.out.print("Total time: ");
System.out.println(end.getTime() - start.getTime());
} catch (Exception e) {
System.out.println("Class " + e.getClass() + " throws error!/n errmsg: " + e.getMessage());
} //end try
} //end main
public static void indexDocs(IndexWriter writer, File file) throws Exception
{
if (file.isDirectory()) {
String[] files = file.list();
for (int i = 0; i < files.length; i++) {
indexDocs(writer, new File(file, files[i]));
} //end for
} else if (file.getPath().endsWith(".html")) { //
只对
HTML
文件做索引
System.out.print("Add file:" + file + " ....");
// Add html file ....
Document doc = new Document();
doc.add(Field.UnIndexed("file", file.getName())); //
索引文件名
doc.add(Field.UnIndexed("modified", DateFormat.getDateTimeInstance().format(new Date(file.lastModified())))); //
索引最后修改时间
String title = "";
String content = "";
String status = "start";
FileReader fReader = new FileReader(file);
BufferedReader bReader = new BufferedReader(fReader);
String line = bReader.readLine();
while (line != null) {
content += line;
//
截取
HTML
标题
<title>
if ("start" == status && line.equalsIgnoreCase("><TITLE")) {
status = "match";
} else if ("match" == status) {
title = line.substring(1, line.length() - 7);
doc.add(Field.Text("title", title)); //
索引标题
status = "end";
} //end if
line = bReader.readLine();
} //end while
bReader.close();
fReader.close();
doc.add(Field.Text("content", content.replaceAll("<[^<>]+>", ""))); //
索引内容
writer.addDocument(doc);
System.out.println(" [OK]");
} //end if
}
} //end class
索引生成完之后,就需要一个检索页面,下边是搜索页面( search.jsp )的代码:
<%@ page language="java" import="javax.servlet.*, javax.servlet.http.*, java.io.*, java.util.Date, java.util.ArrayList, java.util.regex.*, org.apache.lucene.analysis.*, org.apache.lucene.document.*, org.apache.lucene.index.*, org.apache.lucene.search.*, org.apache.lucene.queryParser.*, org.apache.lucene.analysis.Token, org.apache.lucene.analysis.TokenStream, org.apache.lucene.analysis.cjk.CJKAnalyzer, org.apache.lucene.analysis.cjk.CJKTokenizer, com.chedong.weblucene.search.WebLuceneHighlighter" %>
<%@ page contentType="text/html;charset=GB2312" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>PHPDoc - PHP
简体中文手册全文检索
</title>
<base target="main"><!--
由于使用了
Frame
,所以指定
target
到
main
窗口显示
-->
<style>
body {background-color: white; margin: 4px}
body, input, div { font-size: 9pt}
body, div {line-height: 18px}
u {color: red}
b {color: navy}
form {padding: 0px; margin: 0px}
.txt {border: 1px solid black}
.f {padding: 4px; margin-bottom: 16px; background-color: #E5ECF9; border-top: 1px solid #3366CC; border-bottom: 1px solid #3366CC; text-align: center;}
.d, .o {padding-left: 16px}
.d {color: gray}
.o {color: green}
.o a {color: #7777CC}
</style>
<script language="JavaScript">
function gotoPage(i)
{
document.frm.page.value = i;
document.frm.submit();
} //end function
</script>
</head>
<body>
<%
String keyVal = null;
String pageVal = null;
int offset = 0;
int curPage = 0;
int pages;
final int ROWS = 50;
//
获取
GET
参数
try {
byte[] keyValByte = request.getParameter("key").getBytes("ISO8859_1"); //
查找关键字
keyVal = new String(keyValByte);
pageVal = request.getParameter("page"); //
页码
} catch (Exception e) {
//do nothing;
}
if (keyVal == null)
keyVal = new String("");
%>
<div class="f">
<form name="frm" action="./index.jsp" method="GET" οnsubmit="this.page.value='0';return true;" target="_self">
<input type="text" name="key" class="txt" size="40" value="<%=keyVal%>" />
<input type="hidden" name="page" value="<%=pageVal%>" />
<input type="submit" value="
搜
索
" /><br />
<font color="green">
提示:可使用多个关键字(使用空格隔开)提高搜索的准确率。
</font>
</form>
<script language="JavaScript">
document.frm.key.focus();
</script>
</div>
<%
if (keyVal != null && keyVal.length() > 0) {
try {
curPage = Integer.parseInt(pageVal); //
将当前页转换成整数
} catch (Exception e) {
//do nothing;
} //end try
try {
Date startTime = new Date();
keyVal = keyVal.toLowerCase().replaceAll("(or|and)", "").trim().replaceAll("//s+", " AND ");
Searcher searcher = new IndexSearcher("/home/nio/indexes-phpdoc"); //
索引目录
Analyzer analyzer = new CJKAnalyzer();
String[] fields = {"title", "content"};
Query query = MultiFieldQueryParser.parse(keyVal, fields, analyzer);
Hits hits = searcher.search(query);
StringReader in = new StringReader(keyVal);
TokenStream tokenStream = analyzer.tokenStream("", in);
ArrayList al = new ArrayList();
for (Token token = tokenStream.next(); token != null; token = tokenStream.next()) {
al.add(token.termText());
} //end for
//
总页数
pages = (new Integer(hits.length()).doubleValue() % ROWS != 0) ? (hits.length() / ROWS) + 1 : (hits.length() / ROWS);
//
当前页码
if (curPage < 1)
curPage = 1;
else if (curPage > pages)
curPage = pages;
//
起始、终止下标
offset = (curPage - 1) * ROWS;
int end = Math.min(hits.length(), offset + ROWS);
//
循环输出查询结果
WebLuceneHighlighter hl = new WebLuceneHighlighter(al);
for (int i = offset; i < end; i++) {
Document doc = hits.doc(i);
%>
<div class="t"><a href="/~nio/phpdoc-zh/<%=doc.get("file")%>"><%=hl.highLight(doc.get("title"))%></a></div>
<div class="d"><%=hl.highLight(doc.get("content").replaceAll("/n", " "), 100)%> ……</div>
<div class="o">
/~nio/phpdoc-zh/<%=doc.get("file")%>
-
<%=doc.get("modified")%>
</div>
<br />
<%
} //end for
searcher.close();
Date endTime = new Date();
%>
<div class="f">
检索总共耗时
<b><%=((endTime.getTime() - startTime.getTime()) / 1000.0)%></b>
秒,约有
<b><%=hits.length()%></b>
项符合条件的记录,共
<b><%=pages%></b>
页
<%
if (curPage > 1 && pages > 1) {
%>
| <a href="javascript:gotoPage(<%=(curPage-1)%>);" target="_self">
上一页
</a>
<%
} //end if
if (curPage < pages && pages > 1) {
%>
| <a href="javascript:gotoPage(<%=(curPage+1)%>)" target="_self">
下一页
</a>
<%
} //end if
} catch (Exception e) {
%>
<!-- <%=e.getClass()%>
导致错误:
<%=e.getMessage()%> -->
<%
} //end if
} //end if
%>
</body>
</html>
Lucene.Net
系列一
本文介绍了什么是
Lucene,Lucene
能做什么
.
如何从一个文件夹下的所有
txt
文件中查找特定的词
?
本文将围绕该个实例介绍了
lucene.net
的索引的建立以及如何针对索引进行搜索
.
最后还将给出源代码供大家学习
.
What’s Lucene
Lucene 是一个信息检索的函数库 (Library), 利用它你可以为你的应用加上索引和搜索的功能 .
Lucene 是一个信息检索的函数库 (Library), 利用它你可以为你的应用加上索引和搜索的功能 .
Lucene
的使用者不需要深入了解有关全文检索的知识
,
仅仅学会使用库中的一个类
,
你就为你的应用实现全文检索的功能
.
不过千万别以为
Lucene
是一个象
google
那样的搜索引擎
,Lucene
甚至不是一个应用程序
,
它仅仅是一个工具
,
一个
Library.
你也可以把它理解为一个将索引
,
搜索功能封装的很好的一套简单易用的
API.
利用这套
API
你可以做很多有关搜索的事情
,
而且很方便
.
What Can Lucene Do
Lucene
可以对任何的数据做索引和搜索
. Lucene
不管数据源是什么格式
,
只要它能被转化为文字的形式
,
就可以被
Lucene
所分析利用
.
也就是说不管是
MS word, Html ,pdf
还是其他什么形式的文件只要你可以从中抽取出文字形式的内容就可以被
Lucene
所用
.
你就可以用
Lucene
对它们进行索引以及搜索
.
How To Use Lucene --- A Simple Example
示例介绍 :
示例介绍 :
为作为输入参数的文件夹下的所有
txt
类型的文件做索引
,
做好的索引文件放入
index
文件夹
.
然后在索引的基础上对文件进行全文搜索
.
1.
建立索引
IndexWriter writer = new IndexWriter("index", new StandardAnalyzer(), true);
IndexDocs(writer, new System.IO.FileInfo(args[0]));
writer.Optimize();
writer.Close();
IndexWriter writer = new IndexWriter("index", new StandardAnalyzer(), true);
IndexDocs(writer, new System.IO.FileInfo(args[0]));
writer.Optimize();
writer.Close();
IndexWriter
是对索引进行写操作的一个类
,
利用它可以创建一个索引对象然后往其中添加文件
.
需要注意它并不是唯一可以修改索引的类
.
在索引建好后利用其他类还可以对其进行修改
.
构造函数第一个参数是建立的索引所要放的文件夹的名字
.
第二个参数是一个分析对象
,
主要用于从文本中抽取那些需要建立索引的内容
,
把不需要参与建索引的文本内容去掉
.
比如去掉一些
a the
之类的常用词
,
还有决定是否大小写敏感
.
不同的选项通过指定不同的分析对象控制
.
第三个参数用于确定是否覆盖原有索引的
.
第二步就是利用这个
writer
往索引中添加文件
.
具体后面再说
.
第三步进行优化
.
第四步关闭
writer.
下面具体看看第二步
:
public static void IndexDirectory(IndexWriter writer, FileInfo file)
{
if (Directory.Exists(file.FullName))
{
String[] files = Directory.GetFileSystemEntries(file.FullName);
// an IO error could occur
if (files != null)
{
for (int i = 0; i < files.Length; i++)
{
IndexDirectory(writer, new FileInfo(files[i])); // 这里是一个递归
}
}
}
else if (file.Extension == ".txt")
{
IndexFile(file, writer);
}
}
{
if (Directory.Exists(file.FullName))
{
String[] files = Directory.GetFileSystemEntries(file.FullName);
// an IO error could occur
if (files != null)
{
for (int i = 0; i < files.Length; i++)
{
IndexDirectory(writer, new FileInfo(files[i])); // 这里是一个递归
}
}
}
else if (file.Extension == ".txt")
{
IndexFile(file, writer);
}
}
private static void IndexFile(FileInfo file, IndexWriter writer)
{
Console.Out.WriteLine("adding " + file);
try
{
Document doc = new Document();
doc.Add(Field.Keyword("filename", file.FullName));
{
Console.Out.WriteLine("adding " + file);
try
{
Document doc = new Document();
doc.Add(Field.Keyword("filename", file.FullName));
doc.Add(Field.Text("contents", new StreamReader(file.FullName)));
writer.AddDocument(doc);
}
catch (FileNotFoundException fnfe)
{
}
}
}
catch (FileNotFoundException fnfe)
{
}
}
主要就是两个函数一个用于处理文件夹
(
不是为文件夹建立索引
),
一个用于真正为文件建立索引
.
因此主要集中看一下
IndexFile
这个方法
.
首先建立
Document
对象
,
然后为
Document
对象添加一些属性
Field.
你可以把
Document
对象看成是虚拟文件
,
将来将从此获取信息
.
而
Field
则看成是描述此虚拟文件的元数据
(metadata).
其中
Field
包括四个类型
:
|
Keywork
|
该类型的数据将不被分析
,
而会被索引并保存保存在索引中
.
|
|
UnIndexed
|
该类型的数据不会被分析也不会被索引
,
但是会保存在索引
.
|
|
UnStored
|
和
UnIndexed
刚好相反
,
被分析被索引
,
但是不被保存
.
|
|
Text
|
和
UnStrored
类似
.
如果值的类型为
string
还会被保存
.
如果值的类型
Reader
就不会被保存和
UnStored
一样
.
|
最后将每一个
Document
添加到索引当中
.
需要注意的是索引不仅可以建立在文件系统上
,
也可以建立在内存中
.
例如
IndexWriter writer = new IndexWriter("index", new StandardAnalyzer(), true);
在第一个参数不是指定文件夹的名字而是使用
Directory
对象
,
并使用它的子类
RAMDirectory,
就可以将索引建立在内存当中
.
2.
对索引进行搜索
IndexSearcher indexSearcher= new IndexSearcher(indexDir);
Query query = QueryParser.Parse(queryString, "contents",new StandardAnalyzer());
Hits hits = indexSearcher.Search(query);
Query query = QueryParser.Parse(queryString, "contents",new StandardAnalyzer());
Hits hits = indexSearcher.Search(query);
第一步利用
IndexSearcher
打开索引文件用于后面搜索
,
其中的参数是索引文件的路径
.
第二步使用
QueryParser
将可读性较好的查询语句
(
比如查询的词
lucene ,
以及一些高级方式
lucene AND .net)
转化为
Lucene
内部使用的查询对象
.
第三步执行搜索
.
并将结果返回到
hits
集合
.
需要注意的是
Lucene
并不是一次将所有的结果放入
hits
中而是采取一次放一部分的方式
.
出于空间考虑
.
|
作者
idior
|
|
2005-03-16 22:36
|
|
|
Lucene.net
系列二
--- index
上
一详细介绍了有关
Lucene.net
索引添加删除更新的详细内容
.
并给出了所有的
TestCase
供学习参考
.
Lucene
建立
Index
的过程
:
1.
抽取文本
.
比如将
PDF
以及
Word
中的内容以纯文本的形式提取出来
.Lucene
所支持的类型主要为
String,
为了方便同时也支持
Date
以及
Reader.
其实如果使用这两个类型
lucene
会自动进行类型转换
.
2.
文本分析
.
Lucene
将针对所给的文本进行一些最基本的分析
,
并从中去除一些不必要的信息
,
比如一些常用字
a ,an, the
等等
,
如果搜索的时候不在乎字母的大小写
,
又可以去掉一些不必要的信息
.
总而言之你可以把这个过程想象成一个文本的过滤器
,
所有的文本内容通过分析
,
将过滤掉一些内容
,
剩下最有用的信息
.
3.
写入
index.
和
google
等常用的索引技术一样
lucene
在写
index
的时候都是采用的倒排索引技术
(inverted index.)
简而言之
,
就是通过某种方法
(
类似
hash
表
?)
将常见的
”
一篇文档中含有哪些词
”
这个问题转成
”
哪篇文档中有这些词
”.
而各个搜索引擎的索引机制的不同主要在于如何为这张倒排表添加更准确的描述
.
比如
google
有名的
PageRank
因素
.Lucene
当然也有自己的技术
,
希望在以后的文章中能为大家加以介绍
.
在上一篇文章中
,
使用了最基本的建立索引的方法
.
在这里将对某些问题加以详细的讨论
.
1.
添加
Document
至索引
上次添加的每份文档的信息是一样的 , 都是文档的 filename 和 contents.
上次添加的每份文档的信息是一样的 , 都是文档的 filename 和 contents.
doc.Add(Field.Keyword("filename", file.FullName));
doc.Add(Field.Text("contents", new StreamReader(file.FullName)));
doc.Add(Field.Text("contents", new StreamReader(file.FullName)));
在
Lucene
中对每个文档的描述是可以不同的
,
比如
,
两份文档都是描述一个人
,
其中一个添加的是
name, age
另一个添加的是
id, sex ,
这种不规则的文档描述在
Lucene
中是允许的
.
还有一点 Lucene 支持对 Field 进行 Append , 如下 :
还有一点 Lucene 支持对 Field 进行 Append , 如下 :
string baseWord = "fast";
string synonyms[] = String {"quick", "rapid", "speedy"};
Document doc = new Document();
doc.Add(Field.Text("word", baseWord));
for (int i = 0; i < synonyms.length; i++)
doc.Add(Field.Text("word", synonyms[i]));
string synonyms[] = String {"quick", "rapid", "speedy"};
Document doc = new Document();
doc.Add(Field.Text("word", baseWord));
for (int i = 0; i < synonyms.length; i++)
doc.Add(Field.Text("word", synonyms[i]));
这点纯粹是为了方便用户的使用
.
在内部
Lucene
自动做了转化
,
效果和将它们拼接好再存是一样
.
2.
删除索引中的文档
这一点
Lucene
所采取的方式比较怪
,
它使用
IndexReader
来对要删除的项进行标记
,
然后在
Reader Close
的时候一起删除
.
这里简要介绍几个方法 .
这里简要介绍几个方法 .
[TestFixture]
public class DocumentDeleteTest : BaseIndexingTestCase // BaseIndexingTestCase 中的 SetUp 方法 // 建立了索引其中加入了两个 Document
{
[Test]
public void testDeleteBeforeIndexMerge()
{
IndexReader reader = IndexReader.Open(dir); // 当前索引中有两个 Document
public class DocumentDeleteTest : BaseIndexingTestCase // BaseIndexingTestCase 中的 SetUp 方法 // 建立了索引其中加入了两个 Document
{
[Test]
public void testDeleteBeforeIndexMerge()
{
IndexReader reader = IndexReader.Open(dir); // 当前索引中有两个 Document
Assert.AreEqual(2, reader.MaxDoc()); //
文档从
0
开始计数
,MaxDoc
表示下一个文档的序号
Assert.AreEqual(2, reader.NumDocs()); //NumDocs
表示当前索引中文档的个数
reader.Delete(1); // 对标号为 1 的文档标记为待删除 , 逻辑删除
Assert.IsTrue(reader.IsDeleted(1)); // 检测某个序号的文档是否被标记删除
Assert.IsTrue(reader.HasDeletions()); // 检测索引中是否有 Document 被标记删除
Assert.AreEqual(2, reader.MaxDoc()); // 当前下一个文档序号仍然为 2
Assert.AreEqual(1, reader.NumDocs()); // 当前索引中文档数变成 1
reader.Close(); // 此时真正从物理上删除之前被标记的文档
reader = IndexReader.Open(dir);
Assert.AreEqual(2, reader.MaxDoc());
Assert.AreEqual(1, reader.NumDocs());
reader.Close();
}
reader.Delete(1); // 对标号为 1 的文档标记为待删除 , 逻辑删除
Assert.IsTrue(reader.IsDeleted(1)); // 检测某个序号的文档是否被标记删除
Assert.IsTrue(reader.HasDeletions()); // 检测索引中是否有 Document 被标记删除
Assert.AreEqual(2, reader.MaxDoc()); // 当前下一个文档序号仍然为 2
Assert.AreEqual(1, reader.NumDocs()); // 当前索引中文档数变成 1
reader.Close(); // 此时真正从物理上删除之前被标记的文档
reader = IndexReader.Open(dir);
Assert.AreEqual(2, reader.MaxDoc());
Assert.AreEqual(1, reader.NumDocs());
reader.Close();
}
[Test]
public void DeleteAfterIndexMerge() // 在索引重排之后
{
IndexReader reader = IndexReader.Open(dir);
Assert.AreEqual(2, reader.MaxDoc());
Assert.AreEqual(2, reader.NumDocs());
reader.Delete(1);
reader.Close();
IndexWriter writer = new IndexWriter(dir, GetAnalyzer(), false);
writer.Optimize(); // 索引重排
writer.Close();
reader = IndexReader.Open(dir);
Assert.IsFalse(reader.IsDeleted(1));
Assert.IsFalse(reader.HasDeletions());
Assert.AreEqual(1, reader.MaxDoc()); // 索引重排后 , 下一个文档序号变为 1
Assert.AreEqual(1, reader.NumDocs());
reader.Close();
}
}
public void DeleteAfterIndexMerge() // 在索引重排之后
{
IndexReader reader = IndexReader.Open(dir);
Assert.AreEqual(2, reader.MaxDoc());
Assert.AreEqual(2, reader.NumDocs());
reader.Delete(1);
reader.Close();
IndexWriter writer = new IndexWriter(dir, GetAnalyzer(), false);
writer.Optimize(); // 索引重排
writer.Close();
reader = IndexReader.Open(dir);
Assert.IsFalse(reader.IsDeleted(1));
Assert.IsFalse(reader.HasDeletions());
Assert.AreEqual(1, reader.MaxDoc()); // 索引重排后 , 下一个文档序号变为 1
Assert.AreEqual(1, reader.NumDocs());
reader.Close();
}
}
当然你也可以不通过文档序号进行删除工作 . 采用下面的方法 , 可以从索引中删除包含特定的内容文档 .
IndexReader reader = IndexReader.Open(dir);
reader.Delete(new Term("city", "Amsterdam"));
reader.Close();
reader.Delete(new Term("city", "Amsterdam"));
reader.Close();
你还可以通过
reader.UndeleteAll()
这个方法取消前面所做的标记
,
即在
read.Close()
调用之前取消所有的删除工作
3.
更新索引中的文档
这个功能
Lucene
没有支持
,
只有通过删除后在添加来实现
.
看看代码
,
很好理解的
.
[
TestFixture]
public class DocumentUpdateTest : BaseIndexingTestCase
{
[Test]
public void Update()
{
Assert.AreEqual(1, GetHitCount("city", "Amsterdam"));
IndexReader reader = IndexReader.Open(dir);
reader.Delete(new Term("city", "Amsterdam"));
reader.Close();
Assert.AreEqual(0, GetHitCount("city", "Amsterdam"));
IndexWriter writer = new IndexWriter(dir, GetAnalyzer(),false);
Document doc = new Document();
doc.Add(Field.Keyword("id", "1"));
public class DocumentUpdateTest : BaseIndexingTestCase
{
[Test]
public void Update()
{
Assert.AreEqual(1, GetHitCount("city", "Amsterdam"));
IndexReader reader = IndexReader.Open(dir);
reader.Delete(new Term("city", "Amsterdam"));
reader.Close();
Assert.AreEqual(0, GetHitCount("city", "Amsterdam"));
IndexWriter writer = new IndexWriter(dir, GetAnalyzer(),false);
Document doc = new Document();
doc.Add(Field.Keyword("id", "1"));
doc.Add(Field.UnIndexed("country", "Netherlands"));
doc.Add(Field.UnStored("contents","Amsterdam has lots of bridges"));
doc.Add(Field.Text("city", "Haag"));
writer.AddDocument(doc);
writer.Optimize();
writer.Close();
Assert.AreEqual(1, GetHitCount("city", "Haag"));
}
doc.Add(Field.UnStored("contents","Amsterdam has lots of bridges"));
doc.Add(Field.Text("city", "Haag"));
writer.AddDocument(doc);
writer.Optimize();
writer.Close();
Assert.AreEqual(1, GetHitCount("city", "Haag"));
}
protected override Analyzer GetAnalyzer()
{
return new WhitespaceAnalyzer(); // 注意此处如果用 SimpleAnalyzer 搜索会失败 , 因为建立索引的时候使用的 SimpleAnalyse 它会将所有字母变成小写 .
{
return new WhitespaceAnalyzer(); // 注意此处如果用 SimpleAnalyzer 搜索会失败 , 因为建立索引的时候使用的 SimpleAnalyse 它会将所有字母变成小写 .
}
private int GetHitCount(String fieldName, String searchString)
{
IndexSearcher searcher = new IndexSearcher(dir);
Term t = new Term(fieldName, searchString);
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
int hitCount = hits.Length();
searcher.Close();
return hitCount;
}
}
{
IndexSearcher searcher = new IndexSearcher(dir);
Term t = new Term(fieldName, searchString);
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
int hitCount = hits.Length();
searcher.Close();
return hitCount;
}
}
需要注意的是以上所有有关索引的操作
,
为了避免频繁的打开和关闭
Writer
和
Reader.
又由于添加和删除是不同的连接
(Writer, Reader)
做的
.
所以应该尽可能的将添加文档的操作放在一起批量执行
,
然后将删除文档的操作也放在一起批量执行
.
避免添加删除交替进行
.
Lucene.net
系列三
--- index
中
本文将进一步讨论有关
Lucene.net
建立索引的问题
:
主要包含以下主题
:
1. 索引的权重
2. 利用 IndexWriter 属性对建立索引进行高级管理
3. 利用 RAMDirectory 充分发挥内存的优势
4. 利用 RAMDirectory 并行建立索引
5. 控制索引内容的长度
6.Optimize 优化的是什么 ?
1. 索引的权重
2. 利用 IndexWriter 属性对建立索引进行高级管理
3. 利用 RAMDirectory 充分发挥内存的优势
4. 利用 RAMDirectory 并行建立索引
5. 控制索引内容的长度
6.Optimize 优化的是什么 ?
本文将进一步讨论有关
Lucene.net
建立索引的问题
:
索引的权重
根据文档的重要性的不同 , 显然对于某些文档你希望提高权重以便将来搜索的时候 , 更符合你想要的结果 . 下面的代码演示了如何提高符合某些条件的文档的权重 .
根据文档的重要性的不同 , 显然对于某些文档你希望提高权重以便将来搜索的时候 , 更符合你想要的结果 . 下面的代码演示了如何提高符合某些条件的文档的权重 .
比如对公司内很多的邮件做了索引
,
你当然希望主要查看和公司有关的邮件
,
而不是员工的个人邮件
.
这点根据邮件的地址就可以做出判断比如包含
@alphatom.com
的就是公司邮件
,
而
@gmail.com
等等就是私人邮件
.
如何提高相应邮件的权重
?
代码如下
:
public static String COMPANY_DOMAIN = "alphatom.com";
Document doc = new Document();
String senderEmail = GetSenderEmail();
String senderName = getSenderName();
String subject = GetSubject();
String body = GetBody();
doc.Add(Field.Keyword("senderEmail”, senderEmail));
doc.Add(Field.Text("senderName", senderName));
doc.Add(Field.Text("subject", subject));
doc.Add(Field.UnStored("body", body));
Document doc = new Document();
String senderEmail = GetSenderEmail();
String senderName = getSenderName();
String subject = GetSubject();
String body = GetBody();
doc.Add(Field.Keyword("senderEmail”, senderEmail));
doc.Add(Field.Text("senderName", senderName));
doc.Add(Field.Text("subject", subject));
doc.Add(Field.UnStored("body", body));
if (GetSenderDomain().EndsWith(COMPANY_DOMAIN))
//
如果是公司邮件
,
提高权重
,
默认权重是
1.0
doc.SetBoost(1.5);
else // 如果是私人邮件 , 降低权重 .
doc.SetBoost(0.1);
doc.SetBoost(1.5);
else // 如果是私人邮件 , 降低权重 .
doc.SetBoost(0.1);
writer.AddDocument(doc);
不仅如此你还可以对
Field
也设置权重
.
比如你对邮件的主题更感兴趣
.
就可以提高它的权重
.
Field senderNameField = Field.Text("senderName", senderName);
Field subjectField = Field.Text("subject", subject);
subjectField.SetBoost(1.2);
lucene 搜索的时候会对符合条件的文档按匹配的程度打分 , 这点就和 google 的 PageRank 有点类似 , 而 SetBoost 中的 Boost 就是其中的一个因素 , 当然还有其他的因素 . 这要放到搜索里再说 .
subjectField.SetBoost(1.2);
lucene 搜索的时候会对符合条件的文档按匹配的程度打分 , 这点就和 google 的 PageRank 有点类似 , 而 SetBoost 中的 Boost 就是其中的一个因素 , 当然还有其他的因素 . 这要放到搜索里再说 .
利用
IndexWriter
变量对建立索引进行高级管理
在建立索引的时候对性能影响最大的地方就是在将索引写入文件的时候 , 所以在具体应用的时候就需要对此加以控制 .
在建立索引的时候对性能影响最大的地方就是在将索引写入文件的时候 , 所以在具体应用的时候就需要对此加以控制 .
在建立索引的时候对性能影响最大的地方就是在将索引写入文件的时候所以在具体应用的时候就需要对此加以控制
|
IndexWriter
属性
|
默认值
|
描述
|
|
MergeFactory
|
10
|
控制
segment
合并的频率和大小
|
|
MaxMergeDocs
|
Int32.MaxValue
|
限制每个
segment
中包含的文档数
|
|
MinMergeDocs
|
10
|
当内存中的文档达到多少的时候再写入
segment
|
Lucene
默认情况是每加入
10
份文档就从内存往
index
文件写入并生成一个
segement,
然后每
10
个
segment
就合并成一个
segment.
通过
MergeFactory
这个变量就可以对此进行控制
.
MaxMergeDocs
用于控制一个
segment
文件中最多包含的
Document
数
.
比如限制为
100
的话
,
即使当前有
10
个
segment
也不会合并
,
因为合并后的
segmnet
将包含
1000
个文档
,
超过了限制
.
MinMergeDocs
用于确定一个当内存中文档达到多少的时候才写入文件
,
该项对
segment
的数量和大小不会有什么影响
,
它仅仅影响内存的使用
,
进一步影响写索引的效率
.
为了生动的体现这些变量对性能的影响
,
用一个小程序对此做了说明
.
这里有点不可思议
.Lucene in Action
书上的结果比我用
dotLucene
做的结果快了近千倍
.
这里给出书中用
Lucene
的数据
,
希望大家比较一下看看是不是我的问题
.
Lucene in Action
书中的数据
:
% java lia.indexing.IndexTuningDemo 100000 10 9999999 10
Merge factor: 10
Max merge docs: 9999999
Min merge docs: 10
Time: 74136 ms
% java lia.indexing.IndexTuningDemo 100000 100 9999999 10
Merge factor: 100
Max merge docs: 9999999
Min merge docs: 10
Time: 68307 ms
我的数据 : 336684128 ms
可以看出 MinMergeDocs( 主要用于控制内存 ) 和 MergeFactory( 控制合并的次数和合并后的大小 ) 对建立索引有显著的影响 . 但是并不是 MergeFactory 越大越好 , 因为如果一个 segment 的文档数很多的话 , 在搜索的时候必然也会影响效率 , 所以这里 MergeFactory 的取值是一个需要平衡的问题 . 而 MinMergeDocs 主要受限于内存 .
Merge factor: 10
Max merge docs: 9999999
Min merge docs: 10
Time: 74136 ms
% java lia.indexing.IndexTuningDemo 100000 100 9999999 10
Merge factor: 100
Max merge docs: 9999999
Min merge docs: 10
Time: 68307 ms
我的数据 : 336684128 ms
可以看出 MinMergeDocs( 主要用于控制内存 ) 和 MergeFactory( 控制合并的次数和合并后的大小 ) 对建立索引有显著的影响 . 但是并不是 MergeFactory 越大越好 , 因为如果一个 segment 的文档数很多的话 , 在搜索的时候必然也会影响效率 , 所以这里 MergeFactory 的取值是一个需要平衡的问题 . 而 MinMergeDocs 主要受限于内存 .
利用
RAMDirectory
充分发挥内存的优势
从上面来看充分利用内存的空间
,
减少读写文件
(
写入
index)
的次数是优化建立索引的重要方法
.
其实在
Lucene
中提供了更强大的方法来利用内存建立索引
.
使用
RAMDirectory
来替代
FSDirectory.
这时所有的索引都将建立在内存当中
,
这种方法对于数据量小的搜索业务很有帮助
,
同时可以使用它来进行一些小的测试
,
避免在测试时频繁建立删除索引文件
.
在实际应用中
RAMDirectory
和
FSDirectory
协作可以更好的利用内存来优化建立索引的时间
.
具体方法如下
:
1.
建立一个使用
FSDirectory
的
IndexWriter
2 .
建立一个使用
RAMDirectory
的
IndexWriter
3
把
Document
添加到
RAMDirectory
中
4
当达到某种条件将
RAMDirectory
中的
Document
写入
FSDirectory.
5
重复第三步
示意代码
:
private FSDirectory fsDir = FSDirectory.GetDirectory("index",true);
private FSDirectory fsDir = FSDirectory.GetDirectory("index",true);
private RAMDirectory ramDir = new RAMDirectory();
private IndexWriter fsWriter = IndexWriter(fsDir,new SimpleAnalyzer(), true);
private IndexWriter ramWriter = new IndexWriter(ramDir,new SimpleAnalyzer(), true);
while (there are documents to index)
{
ramWriter.addDocument(doc);
if (condition for flushing memory to disk has been met)
{
fsWriter.AddIndexes(Directory[]{ramDir}) ;
ramWriter.Close(); //why not support flush?
ramWriter =new IndexWriter(ramDir,new SimpleAnalyzer(),true);
}
}
private IndexWriter ramWriter = new IndexWriter(ramDir,new SimpleAnalyzer(), true);
while (there are documents to index)
{
ramWriter.addDocument(doc);
if (condition for flushing memory to disk has been met)
{
fsWriter.AddIndexes(Directory[]{ramDir}) ;
ramWriter.Close(); //why not support flush?
ramWriter =new IndexWriter(ramDir,new SimpleAnalyzer(),true);
}
}
这里的条件完全由用户控制
,
而不是
FSDirectory
采用对
Document
计数的方式控制何时写入文件
.
相比之下有更大的自由性
,
更能提升性能
.
利用
RAMDirectory
并行建立索引
RAMDirectory
还提供了使用多线程来建立索引的可能性
.
下面这副图很好的说明了这一点
.
甚至你可以在一个高速的网络里使用多台计算机来同时建立索引
.
就像下面这种图所示
.
虽然有关并行同步的问题需要你自己进行处理
,
不过通过这种方式可以大大提高对大量数据建立索引的能力
.
控制索引内容的长度
.
在我的一篇
速递
介绍过
Google Desktop Search
只能搜索到文本中第
5000
个字的
.
也就是
google
在建立索引的时候只考虑前
5000
个字
,
在
Lucene
中同样也有这个配置功能
.
Lucene
对一份文本建立索引时默认的索引长度是
10,000.
你可以通过
IndexWriter
的
MaxFieldLength
属性对此加以修改
.
还是用一个例子说明问题
.
[Test]
public void FieldSize()
// AddDocuments 和 GetHitCount 都是自定义的方法 , 详见源代码
{
AddDocuments(dir, 10);
// 第一个参数是目录 , 第二个配置是索引的长度
Assert.AreEqual(1, GetHitCount("contents", "bridges"))
// 原文档的 contents 为 ”Amsterdam has lots of bridges”
// 当索引长度为 10 个字时能找到 bridge
AddDocuments(dir, 1);
Assert.AreEqual(0, GetHitCount("contents", "bridges"));
// 当索引长度限制为 1 个字时就无法发现第 5 个字 bridges
}
public void FieldSize()
// AddDocuments 和 GetHitCount 都是自定义的方法 , 详见源代码
{
AddDocuments(dir, 10);
// 第一个参数是目录 , 第二个配置是索引的长度
Assert.AreEqual(1, GetHitCount("contents", "bridges"))
// 原文档的 contents 为 ”Amsterdam has lots of bridges”
// 当索引长度为 10 个字时能找到 bridge
AddDocuments(dir, 1);
Assert.AreEqual(0, GetHitCount("contents", "bridges"));
// 当索引长度限制为 1 个字时就无法发现第 5 个字 bridges
}
对索引内容限长往往是处于效率和空间大小的考虑
.
能够对此进行配置是建立索引必备的一个功能
.
Optimize
优化的是什么
?
在以前的例子里
,
你可能已经多次见过
writer.Optimize()
这段代码
.Optimize
到底做了什么
?
让你吃惊的是这里的优化对于建立索引不仅没有起到加速的作用
,
反而是延长了建立索引的时间
.
为什么
?
因为这里的优化不是为建立索引做的
,
而是为搜索做的
.
之前我们提到
Lucene
默认每遇到
10
个
Segment
就合并一次
,
尽管如此在索引完成后仍然会留下几个
segmnets,
比如
6,7.
而
Optimize
的过程就是要减少剩下的
Segment
的数量
,
尽量让它们处于一个文件中
.
它的过程很简单
,
就是新建一个空的
Segmnet,
然后把原来的几个
segmnet
全合并到这一个
segmnet
中
,
在此过程中
,
你的硬盘空间会变大
,
因为同时存在两份一样大小的索引
.
不过在优化完成后
,Lucene
会自动将原来的多份
Segments
删除
,
只保留最后生成的一份包含原来所有索引的
segment.
尽量减少
segments
的个数主要是为了增加查询的效率
.
假设你有一个
Server,
同时有很多的
Client
建立了各自不同的索引
,
如果此时搜索
,
那么必然要同时打开很多的索引文件
,
这样显然会受到很大的限制
,
对性能产生影响
.
当然也不是随时做
Optimize
就好
,
如前所述做优化时要花费更多的时间和空间
,
而且在做优化的时候是不能进行查询的
.
所以索引建立的后期
,
并且索引的内容不会再发生太多的变化的时候做优化是一个比较好的时段
.
Lucene.net
系列四
--- index
下
本文将介绍有关索引并发控制的问题
,
以结束对
Lucene.net
建立索引问题的讨论
.
1.
允许任意多的读操作并发
.
即可以有任意多的用户在同一时间对同一份索引做查询工作
.
2.
允许任意多的读操作在索引被正在被修改的时候进行
.
即哪怕索引正在被优化
,
添加删除文档
,
这时也是允许用户对索引进行查询工作
. (it’s so cool.)
3.
同一时间只允许一个对索引修改的操作
.
即同一时间只允许
IndexWriter
或
IndexReader
打开同一份索引
.
不能允许两个同时打开一份索引
.
Lucene
提供了几种对索引进行读写的操作
.
添加文档到索引
,
从索引中删除文档
,
优化索引
,
合并
Segments.
这些都是对索引进行写操作的方法
.
查询的时候就会读取索引的内容
.
有关索引并发的问题是一个比较重要的问题
,
而且是
Lucene
的初学者容易忽略的问题
,
当索引被破坏
,
或者程序突然出现异常的时候初学者往往不知道是自己的误操作造成的
.
下面让我们看看
Lucene
是如何处理索引文件的并发控制的
.
首先记住一下三点准则
:
1.
允许任意多的读操作并发
.
即可以有任意多的用户在同一时间对同一份索引做查询工作
.
2.
允许任意多的读操作在索引被正在被修改的时候进行
.
即哪怕索引正在被优化
,
添加删除文档
,
这时也是允许用户对索引进行查询工作
. (it’s so cool.)
3.
同一时间只允许一个对索引修改的操作
.
即同一时间只允许
IndexWriter
或
IndexReader
打开同一份索引
.
不能允许两个同时打开一份索引
.
第一个准则很容易理解
,
第二个准则说明
Lucene
对并发的操作支持还是不错的
.
第三个准则也很正常
,
不过需要注意的是第三个准则只是表明
IndexWriter
和
IndexReader
不能并存
,
而没有反对在多线程中利用同一个
IndexWriter
对索引进行修改
.
这个功能可是经常用到的
,
所以不要以为它是不允许的
.
不过这个时候的并发就需要你自己加以控制
,
以免出现冲突
.
(
注
:
在前面的系列中已说过
IndexReader
不是对
Index
进行读操作
,
而是从索引中删除
docuemnt
时使用的对象
)
有关这三个原则在实际使用
Lucene API
时候的体现
,
让我们先看看下面这张表
:
表中列出了有关索引的主要读写操作 . 其中空白处表示 X 轴的操作和 Y 轴的操作允许并发 .
而
X
处表明
X
轴的操作和
Y
轴的操作不允许同时进行
.
比如
Add document
到索引的时候不允许同时从索引中删除
document.
其实以上这张表就是前面三个准则的体现
.Add Optimize Merge
操作都是由
IndexWriter
来做的
.
而
Delete
则是通过
IndexReader
完成
.
所以表中空白处正是第一条和第二条准则的体现
,
而
X(
冲突
)
处正是第三个原则的具体表现
.
为了在不了解并发控制的情况下对
Lucene API
的乱用
. Lucene
提供了基于文件的锁机制以确保索引文件不会被破坏
.
当你对
index
进行修改的时候
,
比如添加删除文档的时候就会产生
***write.lock
文件
,
而当你从
segment
进行读取信息或者合并
segments
的时候就会产生
***commit.lock
文件
.
在默认情况下
,
这些文件是放在系统临时文件夹下的
.
简而言之
, write.lock
文件存在的时间比较长
,
也就是对
index
进行修改的锁时间比较长
,
而
commit.lock
存在的时间往往很短
.
具体情况见下表
.
如果索引存在于
server,
很多
clients
想访问的时候
,
自然希望能看到其他用户的锁文件
,
这时把锁文件放到系统临时文件夹就不好了
.
此时可以通过配置文件来改变锁文件存放的位置
.
比如在一个
asp.net
的应用下
,
你就可以象下面这样利用
web.config
文件来实现你的目的
.
<configuration>
<appSettings>
<add key="Lucene.Net.lockdir" value="c:yourdir" />
</appSettings>
</configuration>
<appSettings>
<add key="Lucene.Net.lockdir" value="c:yourdir" />
</appSettings>
</configuration>
不仅如此
,
在某些情况下比如你的索引文件存放在一个
CD-ROM
中
,
这时根本就无法对索引进行修改
,
也就不存在所谓的并发冲突
,
这种情况下你甚至可以讲锁文件的机制取消掉
.
同样通过配置文件
.
<configuration>
<appSettings>
<add key="disableLuceneLocks" value="true" />
</appSettings>
</configuration>
<appSettings>
<add key="disableLuceneLocks" value="true" />
</appSettings>
</configuration>
不过请注意不要乱用此功能
,
不然你的索引文件将不再受到安全的保护
.
下面用一个例子说明锁机制的体现
.
using System;
using System.IO;
using Lucene.Net.Analysis;
using Lucene.Net.Index;
using Lucene.Net.Store;
using NUnit.Framework;
using Directory = Lucene.Net.Store.Directory;
using System.IO;
using Lucene.Net.Analysis;
using Lucene.Net.Index;
using Lucene.Net.Store;
using NUnit.Framework;
using Directory = Lucene.Net.Store.Directory;
[TestFixture]
public class LockTest
{
private Directory dir;
[SetUp]
public void Init()
{
String indexDir = "index";
dir = FSDirectory.GetDirectory(indexDir, true);
}
public void Init()
{
String indexDir = "index";
dir = FSDirectory.GetDirectory(indexDir, true);
}
[Test]
[ExpectedException(typeof(IOException))]
public void WriteLock()
{
IndexWriter writer1 = null;
IndexWriter writer2 = null;
try
{
writer1 = new IndexWriter(dir, new SimpleAnalyzer(), true);
writer2 = new IndexWriter(dir, new SimpleAnalyzer(), true);
}
catch (IOException e)
{
Console.Out.WriteLine(e.StackTrace);
}
finally
{
writer1.Close();
Assert.IsNull(writer2);
}
}
[ExpectedException(typeof(IOException))]
public void WriteLock()
{
IndexWriter writer1 = null;
IndexWriter writer2 = null;
try
{
writer1 = new IndexWriter(dir, new SimpleAnalyzer(), true);
writer2 = new IndexWriter(dir, new SimpleAnalyzer(), true);
}
catch (IOException e)
{
Console.Out.WriteLine(e.StackTrace);
}
finally
{
writer1.Close();
Assert.IsNull(writer2);
}
}
[Test]
public void CommitLock()
{
IndexReader reader1 = null;
IndexReader reader2 = null;
try
{
IndexWriter writer = new IndexWriter(dir, new SimpleAnalyzer(),
true);
writer.Close();
reader1 = IndexReader.Open(dir);
reader2 = IndexReader.Open(dir);
}
finally
{
reader1.Close();
reader2.Close();
}
}
}
public void CommitLock()
{
IndexReader reader1 = null;
IndexReader reader2 = null;
try
{
IndexWriter writer = new IndexWriter(dir, new SimpleAnalyzer(),
true);
writer.Close();
reader1 = IndexReader.Open(dir);
reader2 = IndexReader.Open(dir);
}
finally
{
reader1.Close();
reader2.Close();
}
}
}
不过很令人失望的是在
Lucene(Java)
中应该收到的异常在
dotLucene(1.4.3)
我却没有捕获到
.
随后我在
dotLucene
的论坛上问了一下
,
至今尚未有解答
.
这也是开源项目的无奈了吧
.
Lucene.net
系列五
--- search
上
在前面的系列我们一直在介绍有关索引建立的问题
,
现在是该利用这些索引来进行搜索的时候了
,Lucene
良好的架构使得我们只需要很少的几行代码就可以为我们的应用加上搜索的功能
,
首先让我们来认识一下搜索时最常用的几个类
.
查询特定的某个概念
当我们搜索完成的时候会返回一个按
Sorce
排序的结果集
Hits.
这里的
Score
就是接近度的意思
,
象
Google
那样每个页面都会有一个分值
,
搜索结果按分值排列
.
如同你使用
Google
一样
,
你不可能查看所有的结果
,
你可能只查看第一个结果所以
Hits
返回的不是所有的匹配文档本身
,
而仅仅是实际文档的引用
.
通过这个引用你可以获得实际的文档
.
原因很好理解
,
如果直接返回匹配文档
,
数据量太大
,
而很多的结果你甚至不会去看
,
想想你会去看
Google
搜索结果
10
页以后的内容吗
?
下面用一个例子来简要介绍一下
Search
先建立索引
namespace dotLucene.inAction.BasicSearch
{
[TestFixture]
public class BaseIndexingTestCase
{
protected String[] keywords = {"1930110994", "1930110995"};
{
[TestFixture]
public class BaseIndexingTestCase
{
protected String[] keywords = {"1930110994", "1930110995"};
protected String[] unindexed = {"Java Development with Ant", "JUnit in Action"};
protected String[] unstored = {
"we have ant and junit",
"junit use a mock,ant is also",
};
"we have ant and junit",
"junit use a mock,ant is also",
};
protected String[] text1 = {
"ant junit",
"junit mock"
};
"ant junit",
"junit mock"
};
protected String[] text2 = {
"200206",
"200309"
};
"200206",
"200309"
};
protected String[] text3 = {
"/Computers/Ant", "/Computers/JUnit"
};
"/Computers/Ant", "/Computers/JUnit"
};
protected Directory dir;
[SetUp]
protected void Init()
{
string indexDir = "index";
dir = FSDirectory.GetDirectory(indexDir, true);
AddDocuments(dir);
}
protected void Init()
{
string indexDir = "index";
dir = FSDirectory.GetDirectory(indexDir, true);
AddDocuments(dir);
}
protected void AddDocuments(Directory dir)
{
IndexWriter writer=new IndexWriter(dir, GetAnalyzer(), true);
{
IndexWriter writer=new IndexWriter(dir, GetAnalyzer(), true);
for (int i = 0; i < keywords.Length; i++)
{
{
Document doc = new Document();
doc.Add(Field.Keyword("isbn", keywords[i]));
doc.Add(Field.UnIndexed("title", unindexed[i]));
doc.Add(Field.UnStored("contents", unstored[i]));
doc.Add(Field.Text("subject", text1[i]));
doc.Add(Field.Text("pubmonth", text2[i]));
doc.Add(Field.Text("category", text3[i]));
writer.AddDocument(doc);
doc.Add(Field.Keyword("isbn", keywords[i]));
doc.Add(Field.UnIndexed("title", unindexed[i]));
doc.Add(Field.UnStored("contents", unstored[i]));
doc.Add(Field.Text("subject", text1[i]));
doc.Add(Field.Text("pubmonth", text2[i]));
doc.Add(Field.Text("category", text3[i]));
writer.AddDocument(doc);
}
writer.Optimize();
writer.Close();
writer.Optimize();
writer.Close();
}
protected virtual Analyzer GetAnalyzer()
{
PerFieldAnalyzerWrapper analyzer = new PerFieldAnalyzerWrapper(
new SimpleAnalyzer());
analyzer.AddAnalyzer("pubmonth", new WhitespaceAnalyzer());
analyzer.AddAnalyzer("category", new WhitespaceAnalyzer());
return analyzer;
}
}
}
这里用到了一些有关 Analyzer 的知识 , 将放在以后的系列中介绍 .
查询特定的某个概念
然后利用利用
TermQery
来搜索一个
Term(
你可以把它理解为一个
Word)
[Test]
public void Term()
{
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term("subject", "ant");
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JDwA");
public void Term()
{
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term("subject", "ant");
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JDwA");
t = new Term("subject", "junit");
hits = searcher.Search(new TermQuery(t));
Assert.AreEqual(2, hits.Length());
hits = searcher.Search(new TermQuery(t));
Assert.AreEqual(2, hits.Length());
searcher.Close();
}
}
利用 QueryParse 简化查询语句
显然对于各种各样的查询
(
与或关系
,
等等各种复杂的查询
,
在下面将介绍
),
你不希望一一对应的为它们写出相应的
XXXQuery. Lucene
已经为你考虑到了这点
,
通过使用
QueryParse
这个类
,
你只需要写出我们常见的搜索语句
, Lucene
会在内部自动做一个转换
.
这个过程有点类似于数据库搜索
,
我们已经习惯于使用
SQL
查询语句
,
其实在数据库的内部是要做一个转换的
,
因为数据库不认得
SQL
语句
,
它只认得查询语法树
.
让我们来看一个例子
.
[Test]
public void TestQueryParser()
{
IndexSearcher searcher = new IndexSearcher(directory);
public void TestQueryParser()
{
IndexSearcher searcher = new IndexSearcher(directory);
Query query = QueryParser.Parse("+JUNIT +ANT -MOCK",
"contents",
new SimpleAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
Document d = hits.Doc(0);
Assert.AreEqual("Java Development with Ant", d.Get("title"));
"contents",
new SimpleAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
Document d = hits.Doc(0);
Assert.AreEqual("Java Development with Ant", d.Get("title"));
query = QueryParser.Parse("mock OR junit",
"contents",
new SimpleAnalyzer());
hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length(), "JDwA and JIA");
}
"contents",
new SimpleAnalyzer());
hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length(), "JDwA and JIA");
}
由以上的代码可以看出我们不需要为每种特定查询而去设定
XXXQuery
通过
QueryParse
类的静态方法
Parse
就可以很方便的将可读性好的查询口语转换成
Lucene
内部所使用的各种复杂的查询语句
.
有一点需要注意
:
在
Parse
方法中我们使用了
SimpleAnalyzer,
这时候会将查询语句做一些变换
,
比如这里将
JUNIT
等等大写字母变成了小写字母
,
所以才能搜索到
(
因为我们在建立索引的时候使用的是小写
),
如果你将
StanderAnalyzer
变成
WhitespaceAnalyzer
就会搜索不到
.
具体原理以后再说
.
+A +B
表示
A
和
B
要同时存在
,-C
表示
C
不存在
,A OR B
表示
A
或
B
二者有一个存在就可以
..
具体的查询规则如下
:
其中
title
等等的
field
表示你在建立索引时所采用的属性名
.
Lucene.net
系列六
-- search
下
本文主要结合测试案例介绍了
Lucene
下的各种查询语句以及它们的简化方法
.
通过本文你将了解
Lucene
的基本查询语句
,
并可以学习所有的测试代码已加强了解
.
具体的查询语句
在了解了
SQL
后
,
你是否想了解一下查询语法树
?
在这里简要介绍一些能被
Lucene
直接使用的查询语句
.
1. TermQuery
查询某个特定的词 , 在文章开始的例子中已有介绍 . 常用于查询关键字 .
查询某个特定的词 , 在文章开始的例子中已有介绍 . 常用于查询关键字 .
[Test]
public void Keyword()
{
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term("isbn", "1930110995");
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
public void Keyword()
{
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term("isbn", "1930110995");
Query query = new TermQuery(t);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
注意
Lucene
中的关键字
,
是需要用户去保证唯一性的
.
TermQuery
和
QueryParse
只要在
QueryParse
的
Parse
方法中只有一个
word,
就会自动转换成
TermQuery.
2. RangeQuery
用于查询范围 , 通常用于时间 , 还是来看例子 :
用于查询范围 , 通常用于时间 , 还是来看例子 :
namespace dotLucene.inAction.BasicSearch
{
public class RangeQueryTest : LiaTestCase
{
private Term begin, end;
{
public class RangeQueryTest : LiaTestCase
{
private Term begin, end;
[SetUp]
protected override void Init()
{
begin = new Term("pubmonth", "200004");
protected override void Init()
{
begin = new Term("pubmonth", "200004");
end = new Term("pubmonth", "200206");
base.Init();
}
base.Init();
}
[Test]
public void Inclusive()
{
RangeQuery query = new RangeQuery(begin, end, true);
IndexSearcher searcher = new IndexSearcher(directory);
public void Inclusive()
{
RangeQuery query = new RangeQuery(begin, end, true);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
}
Assert.AreEqual(1, hits.Length());
}
[Test]
public void Exclusive()
{
RangeQuery query = new RangeQuery(begin, end, false);
IndexSearcher searcher = new IndexSearcher(directory);
public void Exclusive()
{
RangeQuery query = new RangeQuery(begin, end, false);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(0, hits.Length());
}
Assert.AreEqual(0, hits.Length());
}
}
}
}
RangeQuery
的第三个参数用于表示是否包含该起止日期
.
RangeQuery
和
QueryParse
[Test]
public void TestQueryParser()
{
Query query = QueryParser.Parse("pubmonth:[200004 TO 200206]", "subject", new SimpleAnalyzer());
Assert.IsTrue(query is RangeQuery);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
public void TestQueryParser()
{
Query query = QueryParser.Parse("pubmonth:[200004 TO 200206]", "subject", new SimpleAnalyzer());
Assert.IsTrue(query is RangeQuery);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
query = QueryParser.Parse("{200004 TO 200206}", "pubmonth", new SimpleAnalyzer());
hits = searcher.Search(query);
Assert.AreEqual(0, hits.Length(), "JDwA in 200206");
}
hits = searcher.Search(query);
Assert.AreEqual(0, hits.Length(), "JDwA in 200206");
}
Lucene
用
[]
和
{}
分别表示包含和不包含
.
3. PrefixQuery
用于搜索是否包含某个特定前缀
,
常用于
Catalog
的检索
.
[Test]
public void TestPrefixQuery()
{
PrefixQuery query = new PrefixQuery(new Term("category", "/Computers"));
public void TestPrefixQuery()
{
PrefixQuery query = new PrefixQuery(new Term("category", "/Computers"));
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
query = new PrefixQuery(new Term("category", "/Computers/JUnit"));
hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
query = new PrefixQuery(new Term("category", "/Computers/JUnit"));
hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
PrefixQuery
和
QueryParse
[Test]
public void TestQueryParser()
{
public void TestQueryParser()
{
QueryParser qp = new QueryParser("category", new SimpleAnalyzer());
qp.SetLowercaseWildcardTerms(false);
Query query =qp.Parse("/Computers*");
Console.Out.WriteLine("query = {0}", query.ToString());
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
query =qp.Parse("/Computers/JUnit*");
hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
qp.SetLowercaseWildcardTerms(false);
Query query =qp.Parse("/Computers*");
Console.Out.WriteLine("query = {0}", query.ToString());
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
query =qp.Parse("/Computers/JUnit*");
hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length(), "JUnit in Action");
}
这里需要注意的是我们使用了
QueryParser
对象
,
而不是
QueryParser
类
.
原因在于使用对象可以对
QueryParser
的一些默认属性进行修改
.
比如在上面的例子中我们的
category
是大写的
,
而
QueryParser
默认会把所有的含
*
的查询字符串变成小写
/computer*.
这样我们就会查不到原文中的
/Computers* ,
所以我们需要通过设置
QueryParser
的默认属性来改变这一默认选项
.
即
qp.SetLowercaseWildcardTerms(false)
所做的工作
.
4. BooleanQuery
用于测试满足多个条件
.
下面两个例子用于分别测试了满足与条件和或条件的情况
.
[Test]
public void And()
{
TermQuery searchingBooks =
new TermQuery(new Term("subject", "junit"));
public void And()
{
TermQuery searchingBooks =
new TermQuery(new Term("subject", "junit"));
RangeQuery currentBooks =
new RangeQuery(new Term("pubmonth", "200301"),
new Term("pubmonth", "200312"),
true);
BooleanQuery currentSearchingBooks = new BooleanQuery();
currentSearchingBooks.Add(searchingBooks, true, false);
currentSearchingBooks.Add(currentBooks, true, false);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(currentSearchingBooks);
new RangeQuery(new Term("pubmonth", "200301"),
new Term("pubmonth", "200312"),
true);
BooleanQuery currentSearchingBooks = new BooleanQuery();
currentSearchingBooks.Add(searchingBooks, true, false);
currentSearchingBooks.Add(currentBooks, true, false);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(currentSearchingBooks);
AssertHitsIncludeTitle(hits, "JUnit in Action");
}
[Test]
public void Or()
{
TermQuery methodologyBooks = new TermQuery(
new Term("category",
"/Computers/JUnit"));
TermQuery easternPhilosophyBooks = new TermQuery(
new Term("category",
"/Computers/Ant"));
BooleanQuery enlightenmentBooks = new BooleanQuery();
enlightenmentBooks.Add(methodologyBooks, false, false);
enlightenmentBooks.Add(easternPhilosophyBooks, false, false);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(enlightenmentBooks);
Console.Out.WriteLine("or = " + enlightenmentBooks);
AssertHitsIncludeTitle(hits, "Java Development with Ant");
AssertHitsIncludeTitle(hits, "JUnit in Action");
}
[Test]
public void Or()
{
TermQuery methodologyBooks = new TermQuery(
new Term("category",
"/Computers/JUnit"));
TermQuery easternPhilosophyBooks = new TermQuery(
new Term("category",
"/Computers/Ant"));
BooleanQuery enlightenmentBooks = new BooleanQuery();
enlightenmentBooks.Add(methodologyBooks, false, false);
enlightenmentBooks.Add(easternPhilosophyBooks, false, false);
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(enlightenmentBooks);
Console.Out.WriteLine("or = " + enlightenmentBooks);
AssertHitsIncludeTitle(hits, "Java Development with Ant");
AssertHitsIncludeTitle(hits, "JUnit in Action");
}
什么时候是与什么时候又是或
?
关键在于
BooleanQuery
对象的
Add
方法的参数
.
参数一是待添加的查询条件
.
参数二
Required
表示这个条件必须满足吗
? True
表示必须满足
, False
表示可以不满足该条件
.
参数三
Prohibited
表示这个条件必须拒绝吗
? True
表示这么满足这个条件的结果要排除
, False
表示可以满足该条件
.
这样会有三种组合情况
,
如下表所示
:
BooleanQuery
和
QueryParse
[Test]
public void TestQueryParser()
{
Query query = QueryParser.Parse("pubmonth:[200301 TO 200312] AND junit", "subject", new SimpleAnalyzer());
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
query = QueryParser.Parse("/Computers/JUnit OR /Computers/Ant", "category", new WhitespaceAnalyzer());
hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
}
public void TestQueryParser()
{
Query query = QueryParser.Parse("pubmonth:[200301 TO 200312] AND junit", "subject", new SimpleAnalyzer());
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
query = QueryParser.Parse("/Computers/JUnit OR /Computers/Ant", "category", new WhitespaceAnalyzer());
hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
}
注意
AND
和
OR
的大小
如果想要A与非
B
就用
A AND –B
表示
, +A –B
也可以
.
默认的情况下
QueryParser
会把空格认为是或关系
,
就象
google
一样
.
但是你可以通过
QueryParser
对象修改这一属性
.
[Test]
public void TestQueryParserDefaultAND()
{
QueryParser qp = new QueryParser("subject", new SimpleAnalyzer());
qp.SetOperator(QueryParser.DEFAULT_OPERATOR_AND );
Query query = qp.Parse("pubmonth:[200301 TO 200312] junit");
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
public void TestQueryParserDefaultAND()
{
QueryParser qp = new QueryParser("subject", new SimpleAnalyzer());
qp.SetOperator(QueryParser.DEFAULT_OPERATOR_AND );
Query query = qp.Parse("pubmonth:[200301 TO 200312] junit");
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.Search(query);
Assert.AreEqual(1, hits.Length());
}
5. PhraseQuery 查询短语 , 这里面主要有一个 slop 的概念 , 也就是各个词之间的位移偏差 , 这个值会影响到结果的评分 . 如果 slop 为 0, 当然最匹配 . 看看下面的例子就比较容易明白了 , 有关 slop 的计算用户就不需要理解了 , 不过 slop 太大的时候对查询效率是有影响的 , 所以在实际使用中要把该值设小一点 .PhraseQuery 对于短语的顺序是不管的 , 这点在查询时除了提高命中率外 , 也会对性能产生很大的影响 , 利用 SpanNearQuery 可以对短语的顺序进行控制 , 提高性能 .
[SetUp]
protected void Init()
{
// set up sample document
RAMDirectory directory = new RAMDirectory();
IndexWriter writer = new IndexWriter(directory,
new WhitespaceAnalyzer(), true);
Document doc = new Document();
doc.Add(Field.Text("field",
"the quick brown fox jumped over the lazy dog"));
writer.AddDocument(doc);
writer.Close();
5. PhraseQuery 查询短语 , 这里面主要有一个 slop 的概念 , 也就是各个词之间的位移偏差 , 这个值会影响到结果的评分 . 如果 slop 为 0, 当然最匹配 . 看看下面的例子就比较容易明白了 , 有关 slop 的计算用户就不需要理解了 , 不过 slop 太大的时候对查询效率是有影响的 , 所以在实际使用中要把该值设小一点 .PhraseQuery 对于短语的顺序是不管的 , 这点在查询时除了提高命中率外 , 也会对性能产生很大的影响 , 利用 SpanNearQuery 可以对短语的顺序进行控制 , 提高性能 .
[SetUp]
protected void Init()
{
// set up sample document
RAMDirectory directory = new RAMDirectory();
IndexWriter writer = new IndexWriter(directory,
new WhitespaceAnalyzer(), true);
Document doc = new Document();
doc.Add(Field.Text("field",
"the quick brown fox jumped over the lazy dog"));
writer.AddDocument(doc);
writer.Close();
searcher = new IndexSearcher(directory);
}
private bool matched(String[] phrase, int slop)
{
PhraseQuery query = new PhraseQuery();
query.SetSlop(slop);
}
private bool matched(String[] phrase, int slop)
{
PhraseQuery query = new PhraseQuery();
query.SetSlop(slop);
for (int i = 0; i < phrase.Length; i++)
{
query.Add(new Term("field", phrase[i]));
}
{
query.Add(new Term("field", phrase[i]));
}
Hits hits = searcher.Search(query);
return hits.Length() > 0;
}
return hits.Length() > 0;
}
[Test]
public void SlopComparison()
{
String[] phrase = new String[]{"quick", "fox"};
public void SlopComparison()
{
String[] phrase = new String[]{"quick", "fox"};
Assert.IsFalse(matched(phrase, 0), "exact phrase not found");
Assert.IsTrue(matched(phrase, 1), "close enough");
}
}
[Test]
public void Reverse()
{
String[] phrase = new String[] {"fox", "quick"};
public void Reverse()
{
String[] phrase = new String[] {"fox", "quick"};
Assert.IsFalse(matched(phrase, 2), "exact phrase not found");
Assert.IsTrue(matched(phrase, 3), "close enough");
}
}
[Test]
public void Multiple()-
{
Assert.IsFalse(matched(new String[] {"quick", "jumped", "lazy"}, 3), "not close enough");
Assert.IsTrue(matched(new String[] {"quick", "jumped", "lazy"}, 4), "just enough");
Assert.IsFalse(matched(new String[] {"lazy", "jumped", "quick"}, 7), "almost but not quite");
Assert.IsTrue(matched(new String[] {"lazy", "jumped", "quick"}, 8), "bingo");
}
public void Multiple()-
{
Assert.IsFalse(matched(new String[] {"quick", "jumped", "lazy"}, 3), "not close enough");
Assert.IsTrue(matched(new String[] {"quick", "jumped", "lazy"}, 4), "just enough");
Assert.IsFalse(matched(new String[] {"lazy", "jumped", "quick"}, 7), "almost but not quite");
Assert.IsTrue(matched(new String[] {"lazy", "jumped", "quick"}, 8), "bingo");
}
PhraseQuery
和
QueryParse
利用
QueryParse
进行短语查询的时候要先设定
slop
的值
,
有两种方式如下所示
[Test]
public void TestQueryParser()
{
Query q1 = QueryParser.Parse(""quick fox"",
"field", new SimpleAnalyzer());
Hits hits1 = searcher.Search(q1);
Assert.AreEqual(hits1.Length(), 0);
public void TestQueryParser()
{
Query q1 = QueryParser.Parse(""quick fox"",
"field", new SimpleAnalyzer());
Hits hits1 = searcher.Search(q1);
Assert.AreEqual(hits1.Length(), 0);
Query q2 = QueryParser.Parse(""quick fox"~1", //
第一种方式
"field", new SimpleAnalyzer());
Hits hits2 = searcher.Search(q2);
Assert.AreEqual(hits2.Length(), 1);
"field", new SimpleAnalyzer());
Hits hits2 = searcher.Search(q2);
Assert.AreEqual(hits2.Length(), 1);
QueryParser qp = new QueryParser("field", new SimpleAnalyzer());
qp.SetPhraseSlop(1); // 第二种方式
Query q3=qp.Parse(""quick fox"");
Assert.AreEqual(""quick fox"~1", q3.ToString("field"),"sloppy, implicitly");
Hits hits3 = searcher.Search(q2);
Assert.AreEqual(hits3.Length(), 1);
}
qp.SetPhraseSlop(1); // 第二种方式
Query q3=qp.Parse(""quick fox"");
Assert.AreEqual(""quick fox"~1", q3.ToString("field"),"sloppy, implicitly");
Hits hits3 = searcher.Search(q2);
Assert.AreEqual(hits3.Length(), 1);
}
6. WildcardQuery
通配符搜索 , 需要注意的是 child, mildew 的分值是一样的 . [Test]
public void Wildcard()
{
IndexSingleFieldDocs(new Field[]
{
Field.Text("contents", "wild"),
Field.Text("contents", "child"),
Field.Text("contents", "mild"),
Field.Text("contents", "mildew")
});
IndexSearcher searcher = new IndexSearcher(directory);
Query query = new WildcardQuery(
new Term("contents", "?ild*"));
Hits hits = searcher.Search(query);
Assert.AreEqual(3, hits.Length(), "child no match");
Assert.AreEqual(hits.Score(0), hits.Score(1), 0.0, "score the same");
Assert.AreEqual(hits.Score(1), hits.Score(2), 0.0, "score the same");
}
WildcardQuery 和 QueryParse
需要注意的是出于性能的考虑使用 QueryParse 的时候 , 不允许在开头就使用就使用通配符 .
同样处于性能考虑会将只在末尾含有 * 的查询词转换为 PrefixQuery.
[Test, ExpectedException(typeof (ParseException))]
public void TestQueryParserException()
{
Query query = QueryParser.Parse("?ild*", "contents", new WhitespaceAnalyzer());
}
通配符搜索 , 需要注意的是 child, mildew 的分值是一样的 . [Test]
public void Wildcard()
{
IndexSingleFieldDocs(new Field[]
{
Field.Text("contents", "wild"),
Field.Text("contents", "child"),
Field.Text("contents", "mild"),
Field.Text("contents", "mildew")
});
IndexSearcher searcher = new IndexSearcher(directory);
Query query = new WildcardQuery(
new Term("contents", "?ild*"));
Hits hits = searcher.Search(query);
Assert.AreEqual(3, hits.Length(), "child no match");
Assert.AreEqual(hits.Score(0), hits.Score(1), 0.0, "score the same");
Assert.AreEqual(hits.Score(1), hits.Score(2), 0.0, "score the same");
}
WildcardQuery 和 QueryParse
需要注意的是出于性能的考虑使用 QueryParse 的时候 , 不允许在开头就使用就使用通配符 .
同样处于性能考虑会将只在末尾含有 * 的查询词转换为 PrefixQuery.
[Test, ExpectedException(typeof (ParseException))]
public void TestQueryParserException()
{
Query query = QueryParser.Parse("?ild*", "contents", new WhitespaceAnalyzer());
}
[Test]
public void TestQueryParserTailAsterrisk()
{
Query query = QueryParser.Parse("mild*", "contents", new WhitespaceAnalyzer());
Assert.IsTrue(query is PrefixQuery);
Assert.IsFalse(query is WildcardQuery);
public void TestQueryParserTailAsterrisk()
{
Query query = QueryParser.Parse("mild*", "contents", new WhitespaceAnalyzer());
Assert.IsTrue(query is PrefixQuery);
Assert.IsFalse(query is WildcardQuery);
}
[Test]
public void TestQueryParser()
{
Query query = QueryParser.Parse("mi?d*", "contents", new WhitespaceAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
}
7. FuzzyQuery
模糊查询 , 需要注意的是两个匹配项的分值是不同的 , 这点和 WildcardQuery 是不同的
public void TestQueryParser()
{
Query query = QueryParser.Parse("mi?d*", "contents", new WhitespaceAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual(2, hits.Length());
}
7. FuzzyQuery
模糊查询 , 需要注意的是两个匹配项的分值是不同的 , 这点和 WildcardQuery 是不同的
[Test]
public void Fuzzy()
{
Query query = new FuzzyQuery(new Term("contents", "wuzza"));
Hits hits = searcher.Search(query);
Assert.AreEqual( 2, hits.Length(),"both close enough");
Assert.IsTrue(hits.Score(0) != hits.Score(1),"wuzzy closer than fuzzy");
Assert.AreEqual("wuzzy", hits.Doc(0).Get("contents"),"wuzza bear");
}
public void Fuzzy()
{
Query query = new FuzzyQuery(new Term("contents", "wuzza"));
Hits hits = searcher.Search(query);
Assert.AreEqual( 2, hits.Length(),"both close enough");
Assert.IsTrue(hits.Score(0) != hits.Score(1),"wuzzy closer than fuzzy");
Assert.AreEqual("wuzzy", hits.Doc(0).Get("contents"),"wuzza bear");
}
FuzzyQuery 和 QueryParse
注意和
PhraseQuery
中表示
slop
的区别
,
前者
~
后要跟数字
.
[Test]
public void TestQueryParser()
{
Query query =QueryParser.Parse("wuzza~","contents",new SimpleAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual( 2, hits.Length(),"both close enough");
}
public void TestQueryParser()
{
Query query =QueryParser.Parse("wuzza~","contents",new SimpleAnalyzer());
Hits hits = searcher.Search(query);
Assert.AreEqual( 2, hits.Length(),"both close enough");
}















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









