






序列到序列模型(Sequence to Sequence Model,简称Seq2Seq)是一种广泛应用于自然语言处理(NLP)任务中的深度学习模型架构。它能够将一个输入序列转换为一个输出序列,常用于机器翻译、文本摘要、对话系统等应用场景。本文将介绍Seq2Seq模型的基本原理、常见结构中的带注意力机制的Seq2Seq模型以及训练方法。
1. Seq2Seq模型的基本原理
Seq2Seq模型的核心思想是使用两个神经网络,一个用于编码输入序列(Encoder),另一个用于解码输出序列(Decoder)。编码器将输入序列转换为一个固定长度的上下文向量(Context Vector),解码器根据这个上下文向量生成输出序列。
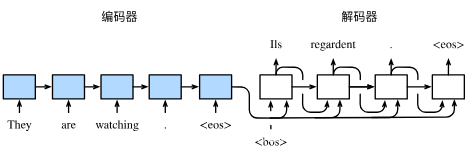
1.1 编码器(Encoder)
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量 ,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
让我们考虑批量大小为1的时序数据样本。假设输入序列是 ,…,
例如
是输入句子中的第
个词。在时间步
,循环神经网络将输入
的特征向量
和上个时间步的隐藏状态
变换为当前时间步的隐藏状态
。我们可以用函数
表达循环神经网络隐藏层的变换:
接下来,编码器通过自定义函数将各个时间步的隐藏状态变换为背景变量:
例如,当选择时,背景变量是输入序列最终时间步的隐藏状态
。
以上描述的编码器是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
1.2 解码器(Decoder)
刚刚已经介绍,编码器输出的背景变量𝑐𝑐编码了整个输入序列 ,…,
的信息。给定训练样本中的输出序列
对每个时间步
(符号与输入序列或编码器的时间步
有区别),解码器输出
的条件概率将基于之前的输出序列
和背景变量,即
。
为此,我们可以使用另一个循环神经网络作为解码器。在输出序列的时间,解码器将上一时间步的输出
以及背景变量
作为输入,并将它们与上一时间步的隐藏状态
变换为当前时间步的隐藏状态
。因此,我们可以用函数
表达解码器隐藏层的变换:
有了解码器的隐藏状态后,我们可以使用自定义的输出层和softmax运算来计算,例如,基于当前时间步的解码器隐藏状态
、上一时间步的输出
以及背景变量
来计算当前时间步输出
的概率分布。
2 Seq2Seq模型的常见结构
2.1带注意力机制的Seq2Seq模型
注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到背景变量。解码器在每一时间步调整这些权重,即注意力权重,从而能够在不同时间步分别关注输入序列中的不同部分并编码进相应时间步的背景变量。本节我们将讨论注意力机制是怎么工作的。
在基本原理里我们区分了输入序列或编码器的索引与输出序列或解码器的索引
。该节中,解码器在时间步
′的隐藏状态
,其中
是上一时间步
的输出
的表征,且任一时间步
使用相同的背景变量
。但在注意力机制中,解码器的每一时间步将使用可变的背景变量。记
是解码器在时间步𝑡′𝑡′的背景变量,那么解码器在该时间步的隐藏状态可以改写为
这里的关键是如何计算背景变量和如何利用它来更新隐藏状态
。下面将分别描述这两个关键点。
2.1.1 计算背景变量
我们先描述第一个关键点,即计算背景变量。图2描绘了注意力机制如何为解码器在时间步2计算背景变量。首先,函数根据解码器在时间步1的隐藏状态和编码器在各个时间步的隐藏状态计算softmax运算的输入。softmax运算输出概率分布并对编码器各个时间步的隐藏状态做加权平均,从而得到背景变量。

具体来说,令编码器在时间步𝑡𝑡的隐藏状态为,且总时间步数为
。那么解码器在时间步
的背景变量为所有编码器隐藏状态的加权平均:
其中给定时,权重
在
= 1,…,
的值是一个概率分布。为了得到概率分布,我们可以使用softmax运算:
现在,我们需要定义如何计算上式中softmax运算的输入。由于
同时取决于解码器的时间步
和编码器的时间步
,我们不妨以解码器在时间步
的隐藏状态
与编码器在时间步
的隐藏状态
为输入,并通过函数
计算
:
这里函数有多种选择,如果两个输入向量长度相同,一个简单的选择是计算它们的内积
。而最早提出注意力机制的论文则将输入连结后通过含单隐藏层的多层感知机变换 [1]:
其中、
、
都是可以学习的模型参数。
2.1.2 更新隐藏状态
现在我们描述第二个关键点,即更新隐藏状态。以门控循环单元为例,在解码器中我们可以对门控循环单元的设计稍作修改,从而变换上一时间步的输出
、隐藏状态
和当前时间步
′的含注意力机制的背景变量
[1]。解码器在时间步
的隐藏状态为
其中的重置门、更新门和候选隐藏状态分别为
其中含下标的和
分别为门控循环单元的权重参数和偏差参数。
3 训练方法
Seq2Seq模型的训练通常采用有监督学习的方法,使用配对的输入和输出序列进行训练。训练目标是最小化解码器生成的输出序列与目标序列之间的差异,常用的损失函数是交叉熵损失(Cross-Entropy Loss)。
3.1 数据准备
准备训练数据时,需要将输入序列和输出序列转化为向量表示。具体步骤如下:
- 标记处理和填充: 将输入和输出序列中的单词转换为索引,添加特殊标记(BOS、EOS、PAD)。
- 构建词汇表: 使用训练数据中的所有单词构建词汇表,将每个单词映射到一个唯一的索引。
- 数据集构建: 将处理后的输入和输出序列转化为Tensor数据集,供模型训练使用。
3.2 模型训练
在模型训练过程中,使用反向传播算法(Backpropagation)和梯度下降算法(Gradient Descent)来更新模型参数。为了提高训练效率,可以使用迷你批量梯度下降(Mini-Batch Gradient Descent)和Adam优化器。具体步骤如下:
- 定义模型: 包括编码器(Encoder)、注意力机制(Attention)和解码器(Decoder)。
- 定义损失函数: 使用交叉熵损失函数(Cross-Entropy Loss)。
- 前向传播: 将输入序列通过编码器生成隐藏状态,然后通过解码器生成输出序列。
- 计算损失: 使用损失函数计算模型输出与目标序列之间的损失。
- 反向传播和参数更新: 使用反向传播算法计算梯度并更新模型参数。
3.3 评价指标
评价机器翻译结果通常使用BLEU(Bilingual Evaluation Understudy)[2]。对于模型预测序列中任意的子序列,BLEU考察这个子序列是否出现在标签序列中。
具体来说,设词数为的子序列的精度为
。它是预测序列与标签序列匹配词数为
的子序列的数量与预测序列中词数为
的子序列的数量之比。举个例子,假设标签序列为
、
、
、
、
、
,预测序列为
、
、
、
、
,那么
。设
和
分别为标签序列和预测序列的词数,那么,BLEU的定义为
其中是我们希望匹配的子序列的最大词数。可以看到当预测序列和标签序列完全一致时,BLEU为1。
4 总结
本质上,注意力机制能够为表征中较有价值的部分分配较多的计算资源。这个有趣的想法自提出后得到了快速发展,特别是启发了依靠注意力机制来编码输入序列并解码出输出序列的变换器(Transformer)模型的设计 [3]。变换器抛弃了卷积神经网络和循环神经网络的架构。它在计算效率上比基于循环神经网络的编码器—解码器模型通常更具明显优势。含注意力机制的变换器的编码结构在后来的BERT预训练模型中得以应用并令后者大放异彩:微调后的模型在多达11项自然语言处理任务中取得了当时最先进的结果 [4]。
参考文献
[1] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[2] Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
[3] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998-6008).
[4] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









