







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
合集在这里:《大模型面试宝典》(2024版) 正式发布!
之前我写过一篇讲解 MoE 的文章,收到了不少读者的关注和阅读。
今天这篇文章再来从应用层面给大家分享一下MoE的主要分类和用法。喜欢本文记得收藏、关注、点赞。
MoE 原理回顾
MoE 是用稀疏 MoE 层替换前馈层。这些层包含一定数量的专家(例如 8 个),每个专家都是一个神经网络(通常是 FFN)。然后,路由器/门网络负责选择要使用的专家。

MoE 具有预训练速度快的特点,通过只激活所需的参数数量,从而获得更快的训练和推理速度。但如果您希望将所有专家加载到内存中,仍然需要很高的 VRAM。无论如何,就激活参数而言,它们往往比具有相同参数数量的密集模型表现出色。典型的 MoE 架构的大语言模型:Switch Transformers、Mixtral、DBRX、Jamba DeepSeekMoE 等等。
MoE 分类与对比
Pretrain MoE
Pretrain MoE (预训练 MoE)旨在利用 MoE 架构从头开始预训练语言模型,以期获得比传统密集模型更高效的训练效果。
下表是 ST-MoE 这篇论文对哪些 Token 组发送给哪些专家的统计:
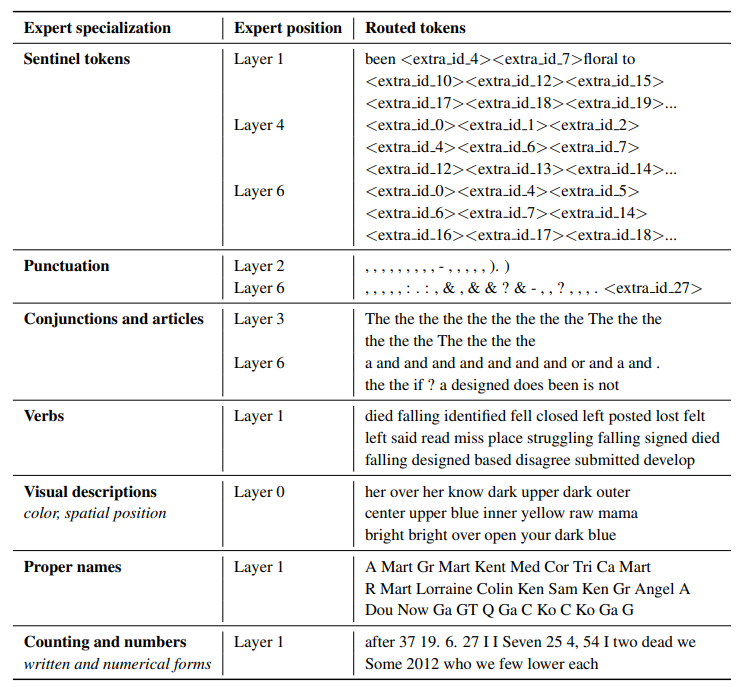
预训练 MoE 的优势在于:
-
训练速度更快。在相同计算预算下,MoE 模型理论上可以比密集模型更快达到相同的性能水平。
-
推理速度更快。尽管 MoE 模型参数量巨大,但实际推理时只会激活部分专家,因此推理速度比拥有相同参数量的密集模型更快。
-
专家可以专门针对不同的浅层概念或词元组,而不是某个特定主题。
不过,预训练 MoE 也面临一些挑战,如推理时需要大量内存来加载所有专家参数,以及在下游任务微调时容易过拟合等。
代表性的预训练 MoE 模型有 Switch Transformer、Mixtral 等。
Upcycled MoE
Upcycled MoE(再利用 MoE)的思路是在一个已经训练好的基础模型上,通过复制其前馈网络来创建多个专家,形成一个 MoE 模型。
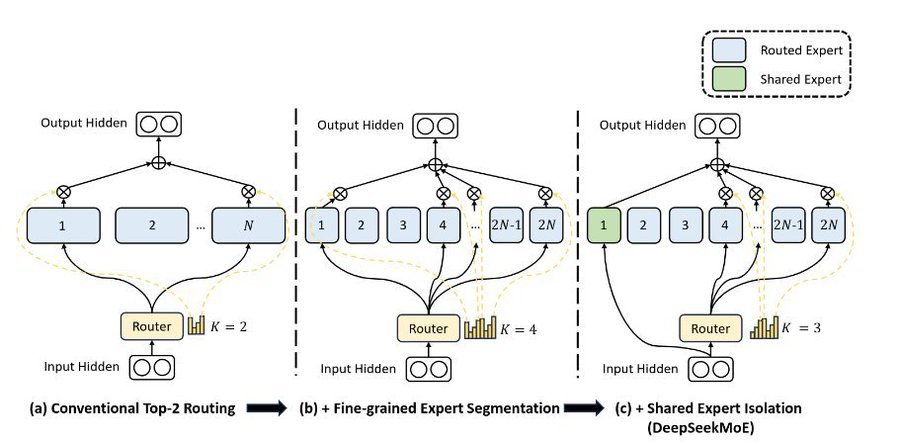
与从头预训练相比,Upcycled MoE 的优势在于:
-
基于成熟的预训练模型,继续预训练的计算成本更低。
-
可以使用细粒度的专家,即将前馈网络切割成更小的单元,从而获得数量众多的小型专家。
-
可以灵活控制要激活的专家数量,在推理速度和效果之间进行权衡。
Upcycled MoE 的代表性工作包括 DeepSeek-MoE、Upstage SOLAR 等。
Franken MoE
Franken MoE(转基因 MoE)的思路与模型合并类似,即选择几个在特定任务上表现优异的微调模型,将它们组合成一个 MoE 模型。 通过一定的训练,可以让路由器学会将不同类型的 token 发送给对应的专家。

与预训练 MoE 和再利用 MoE 相比,Franken MoE 的特点是:
-
专家是面向特定任务的,而不是通用的浅层概念,这一点与预训练 MoE 有本质区别。
-
不再具有 MoE 的某些优势,如负载均衡。因为专家之间的能力差异较大。
-
在特定任务上的表现可能优于通用的 MoE 模型,如 Beyonder-4x7B-v2。
但 Franken MoE 能否广泛应用于不同场景,目前还有待进一步验证。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
- 《大模型面试宝典》(2024版) 正式发布!
- 《大模型实战宝典》(2024版)正式发布!
- 大模型面试准备(一):LLM主流结构和训练目标、构建流程
- 大模型面试准备(二):LLM容易被忽略的Tokenizer与Embedding
- 大模型面试准备(三):聊一聊大模型的幻觉问题
- 大模型面试准备(四):大模型面试必会的位置编码
- 大模型面试准备(五):图解 Transformer 最关键模块 MHA
- 大模型面试准备(六):一文讲透生成式预训练模型 GPT、GPT2、GPT3
- 大模型面试准备(七):ChatGPT 的内核 InstructGPT 详细解读
- 大模型面试准备(八):一文详解国产大模型导师 LLaMA v1和v2
- 大模型面试准备(九):简单透彻理解MoE
- 大模型面试准备(十):大模型数据处理方法及优秀的开源数据介绍
- 大模型面试准备(十一):怎样让英文大语言模型可以很好的支持中文?
- 大模型面试准备(十二):怎样利用预训练方法让英文大语言模型可以很好的支持中文?
- 大模型面试准备(十三):怎样对预训练模型进行指令微调,让英文大语言模型支持中文?
















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









